
Hosszú várakozás után 2014. március 18-án jelent meg a Java 8 fejlesztői környezet és programozási nyelv (JDK 1.8.0). A 8-as Java talán a legnagyobb előrelépés a 2004-ben megjelent Java 5 óta és óriási mennyiségű újítást hoz a nyelvbe, fordítóba, osztálykönyvtárakba és a JVM-be. Az 1998-as Java 2 (J2SE 1.2) után a nyelv fejlesztése évekig 2 éves kiadási ciklussal működött. Ezt az ütemet a Java 7 törte meg, amire a 2006-os Java SE 6 után különböző üzletpolitikai huzavonák miatt majdnem 5 évet kellett várni. A Java 8 esetén ennél azért már rövidebb volt a fejlesztési idő, a Java 9 után pedig a fejlesztést végző közösség tervei szerint újra visszaáll a két éves kiadási ciklus. Egy 2012-es The Register cikkből kiderült, hogy akkoriban a Java 9-et és 10-et még 2015-re és 2017-re tervezték. Végül aztán a Java 9 2017. szeptember 21-én jelent meg. Ez a verzió nyelvi szempontból gyakorlatilag nem változott a 8-hoz képest, a Java 10-be viszont újra jelentős módosítást terveznek, mégpedig a teljes objektumorientáltság elérését. Ezzel megszűnnének a primitív típusok és immár minden objektum lenne. Ezen kívül pedig a tömböket 64 bites indexeléssel is lehetne használni ami sokkal nagyobb tömbméreteket tenne lehetővé. Emellett pedig némi tisztogatást is szeretnének elvégezni. A Java ugyanis már több, mint 20 éve velünk van. Először 200 class fájllal indult, ma már 70 ezernél is több van benne. Néhány osztályban több a deprecated metódus, mint a használható.
Ebben a cikkben részletesen áttekintem a Java 8 nyelvi újdonságait. (Bár a Java 8 SE támogatása 2019 januárjában hivatalosan végetért, a cikkben található ismeretek újabb Java esetén is hasznosak. A fejlesztők túlnyomó többsége pedig még mindig ezt a verziót használja.) A cikkben található példaprogramok az alábbi JDK-verzióval készültek:
Az alábbi lista a Java 8 minden újdonságát felsorolja kategóriákra bontva:
Java programozási nyelv
Collections
Kompakt profilok, amelyek a Java SE előre meghatározott részhalmazait tartalmazzák olyan alkalmazásokhoz, amelyeknek a kisebb eszközökön való futáshoz nincs szükségük a teljes platformra.
Biztonság
JavaFX
Eszközök
Nemzetközi támogatás
Deployment
Date-Time csomag: új csomagkészlet, ami új és kiterjedt dátum-idő modellt biztosít
Scripting
Pack200
IO és NIO
java.lang és java.util csomagok
JDBC
Java DB
Hálózatkezelés
Konkurencia
Java XML-JAXP
HotSpot
Java Mission Control 5.3
Ebből a hatalmas újdonsághalmazból ebben a cikkben az új nyelvi elemeket és változásokat fogom ismertetni. Ugorjunk is egyből a mély vízbe!
A lambda kifejezések bevezetése (néha closure néven is emlegetik) a Java 8 egyik legjobban várt és (higgyük el!) legnagyobb újdonsága. Magát a fogalmat többféleképpen magyarázzák el különböző bemutatók és tananyagok. Egyesek szerint ez végre egy módszer arra, hogy funkcionális programozási stílust vezessünk be az objektum-orientált Java-ba. Más megközelítés szerint lehetővé teszi, hogy függvényeket használjunk metódusparaméterként vagy kódot kezeljünk adatként. Egy harmadik elképzelés szerint - és ezt az utat járja az Oracle oktatási leírása is - a megismerés legegyszerűbb első lépése, ha azt mondjuk, hogy anonim belső osztályokat lehet kiváltani lambda kifejezésekkel. (Emellett nem elhanyagolható módon hatékonnyá és egyszerűbbé teszi a modern többmagos processzorok kihasználását is.) A lambda kifejezés egyébként a funkcionális nyelvekben használatos fogalom, de több JVM-en futó nyelvben megvolt már régóta (Groovy, Scala). Aki matematikai megalapozást szeretne a fogalomhoz, annak könnyed esti olvasmányként tudom ajánlani a Typotex kiadó Lambda kalkulus nevű lektűrjét.
A Java szerint a lambda kifejezés szintaxisa a következő:
| Paraméterlista | Nyíl token | Törzs |
|---|---|---|
| (int x, int y) | -> | x+y |
A törzs lehet egyetlen kifejezés vagy pedig egy hosszabb kódblokk. A kifejezés törzse a végrehajtáskor egyszerűen kiértékelődik és visszaadódik az értéke. Kódblokk esetén a blokk egy metódustörzshöz hasonlóan lefut és a vezérlés egy return kifejezéssel visszatér a hívóhoz. A break és continue kulcsszavak nem használhatók a törzsben a szokványos ciklusbeli használatuktól eltekintve. Amennyiben a törzs visszatérési értéket készít, akkor minden vezérlési útnak vissza kell adnia valamit, különben nem fordul le a kódunk. Nézzünk három példát:
(int x, int y) -> x + y
() -> 42
(String s) -> { System.out.println(s); }
Az első kifejezés vesz két egész paramétert (x és y) és visszaadja az összegüket. A másodiknak nincs paramétere és egy egészet, 42-t ad vissza. A harmadik egy sztringet vesz és kiírja a konzolra, majd nem ad vissza semmit (de azt nagyon). Nézzünk egy gyakorlati példát is, mondjuk ezt, ami kiírja egy lista elemeit:
Arrays.asList("a", "b", "d").forEach((String e) -> System.out.println(e));
Ezen még egyszerűsíthetünk is, ugyanis a fordító van olyan okos, hogy kikövetkezteti az e típusát:
Arrays.asList("a", "b", "d").forEach(e -> System.out.println(e));
Kódblokkot is fabrikálhatunk, ez így néz ki:
Arrays.asList("a", "b", "d").forEach(e -> { System.out.print(e); System.out.print(e); });
Java 8-ban minden collection kiegészült lambdát fogadó forEach megtódussal. A lambda kifejezések hivatkozhatják az osztály tagváltozóit és helyi változókat. A következő két kódrészlet ekvivalens:
String separator = ","; Arrays.asList("a", "b", "d").forEach((String e) -> System.out.print(e + separator));
és
final String separator = ","; Arrays.asList("a", "b", "d").forEach((String e) -> System.out.print(e + separator));
A kifejezés típusa non-capturing, ha nem ér el a törzsén kívül definiált változókat és capturing ha igen.
Egy lambdán kívüli nem final változó elérése lambda törzséből fordítási hibát fog okozni. Akkor hogy is van ez a fenti példánál? Nos expliciten nem kötelező minden változót final-ként jelölni. A Java 8 bevezette az effektíven final fogalmat: a fordító automatikusan minden változót final-nak tekint aminek csak egyszer adnak értéket. Lambda kifejezéseknél csak final vagy effektíven final lambdán kívüli változókra lehet hivatkozni. Ez a megközelítés egyszerűsíti a lambda kifejezések szálbiztossá tételét. A lambdák egyik fő célja ugyanis a párhuzamos feldolgozásban való használat, a szálbiztosság pedig nagyon alkalmassá teszi őket erre. Az effektíven final elképzelés sokat segít ebben de azért ez sem megoldás mindenre. A mutable objektumok belső állapotát továbbra is megváltoztathatják. Tekintsük a következő kódrészletet:
int[] total = new int[1]; Runnable r = () -> total[0]++; r.run();
A kód helyes, a total változó effektíven final, de az általa hivatkozott objektum nem marad ugyanaz a lambda végrehajtása után. Ezt nem árt észben tartani, hogy elkerüljük az olyan kód írását ami nem várt módosításokat csinál.
A lambda kifejezések visszatérési értékének típusát (ha van visszatérési érték) szintén kikövetkezteti a fordító. Amennyiben a lambda törzse csak egy sorból áll, akkor a return kifejezés nem kötelező. A következő két kódrészlet ekvivalens:
Arrays.asList("a", "b", "d").sort((e1, e2) -> e1.compareTo(e2));
és
Arrays.asList("a", "b", "d").sort((e1, e2) -> { int result = e1.compareTo(e2); return result; });
Lambda kifejezést persze nem lehet csak úgy ész nélkül írogatni mindenhová. A fenti példákban a sort és forEach metódusok azért használhatók ilyen módon, mert ún. funkcionális interfészeket várnak paraméterként. A nyelv tervezői ugyanis sokat gondolkodtak azon, hogyan tegyék a már létező funkcionalitást lambda-baráttá. A végeredmény a funkcionális interfészek elképzelése lett. A két fogalom kéz a kézben jár.
A Java fejlesztők már korábban is használhattak funkcionális interfészt mégpedig anélkül, hogy egyáltalán tudtak volna róla. Például ezeket: java.lang.Runnable, java.awt.event.ActionListener, java.util.Comparator, java.util.concurrent.Callable. Ezekben több közös vonás is van, azonban itt most az a lényeges, hogy a definíciójuk csak egy metódust tartalmaz. Ezt más néven Single Abstract Method interfészeknek is hívják (SAM). Ezeket mindenki előszeretettel használja úgy, hogy csinál hozzájuk egy anonim belső osztályt, mint például:
public class AnonymousClassTest { public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { System.out.println("Most valami remek dolog történt..."); } }).start(); } }
Anonim belső osztály? Mintha ezt már hallottuk volna a lambda kifejezéseknél is! Igen, itt kapcsolódik össze a két fogalom. A Java 8-cal a SAM interfészeket némileg újragondolták, elnevezték funkcionális interfészeknek és immár szépen használhatók lambda kifejezésekkel (sőt metódus és konstruktor referenciákkal is, de azokról majd később). Ahol egy metódus funkcionális interfészt vár, ott lambda kifejezést is megadhatunk. A funkcionális interfész metódusát funkcionális metódusnak hívjuk.
A gyakorlatban a funkcionális interfészek elképzelése törékeny dolog, hiszen ha bárki hozzáír még egy metódust, akkor onnantól már sok minden lesz, csak nem funkcionális. Ezért aztán bevezettek egy @FunctionalInterface annotációt is, amivel a fordítónak meg lehet mondani, hogy amit elkövetni készülünk, az egy funkcionális interfész. Ha esetleg mégis megszaladna a ceruzánk és nem ez lesz az eredmény, akkor a fordító majd a kezünkre csap az annotáció hatására. Ezt például lefordítja:
@FunctionalInterface public interface Buli extends OsInterface { public void buliVan(); }
De ha hozzáírunk még egy public void nagyBuliVan() metódust, akkor már nem. Azt viszont elfogadja, ha a java.lang.Object osztályból definiálunk benne absztrakt metódusokat (toString, equals, stb.). Ez tehát szintén szabályos:
@FunctionalInterface public interface Buli extends OsInterface { public void buliVan(); public String toString(); public int hashCode(); }
Az interfészek öröklődhetnek más interfészekből és ha nem hoznak be új absztrakt metódusokat egy korábban funkcionális interfészbe, akkor továbbra is funkcionálisnak tekinthetők. Ha egy funkcionális interfészt bármennyi default vagy statikus metódussal kiegészítünk, még mindig funkcionális marad. (Default metódusokról később lesz szó.) A Java összes "gyári" osztálykönyvtárában lévő funkcionális interfészt is megjelölték a @FunctionalInterface annotációval. A funkcionális interfészek a lambda kifejezésekkel immár egyszerűen kiváltják a korábbi belső osztályos megoldást:
public class BuliTest { public static void main(String[] args) { induljonABanzaj(new Buli() { @Override public void buliVan() { System.out.println("Anonim osztállyal!"); } }); induljonABanzaj(() -> System.out.println("Lambdával könnyebb az élet! :-)")); } public static void induljonABanzaj(Buli buli) { buli.buliVan(); } }
A Java 8 a viselkedési paraméter (behavioral parameter) kifejezést használja a paraméterként átadott funkcionalitásra. Viselkedési paraméterek használata a Java 8 előtt csak interfészekkel és anonim osztályokkal volt megoldható, mint a fenti AnonymousClassTest vagy BuliTest is bemutatja. A Java 8 a lambda kifejezésekkel és a metódusreferenciákkal a viselkedési paraméterek leírását sokkal könnyebbé tette.
A Java 8 API-ja 40 funkcionális interfészt tartalmaz a java.util.function package-ben, de természetesen bárki aki elég bátorságot érez magában, akárhány újat is definiálhat magának. Előbb azonban érdemes a beépítetteket megnézni, hátha van már olyan!
Nézzünk ezek közül néhány nagyon egyszerűt és használatukat!
Predicate<T>: egy paraméter predikátumát reprezentálja. Olyan lambda kifejezést hozhatunk vele létre, ami egy boolean értéket ad vissza a megadott aktuális paraméter alapján. Például meg tudjuk nézni, hogy egy átadott érték pozitív-e, majd ezt használva el tudjuk tüntetni egy listából a pozitív értékeket:
Predicate<Integer> isPositive = number -> number > 0; Arrays.asList(10, -3, 1).removeIf(isPositive);
Persze a lambda kifejezést egyből a removeIf paramétereként is megadhatjuk, hiszen az Predicate<T> típusú. A Predicate<T> funkcionális metódusát test-nek hívják.
Consumer<T>: olyan műveletet vár, aminek egy paramétere van és nincs visszatérési értéke. A többi funkcionális interfésztől eltérően ennek valamilyen mellékhatása van. A fenti forEach-es példa pont ilyen volt. Most a külön Consumer<String> deklarációt már nem írom ki, gondolom ezek után már egyértelmű, hogy úgy is lehet:
Arrays.asList("a", "b", "d").forEach(e -> System.out.println(e));
Supplier<T>: valamilyen végeredmény létrehozója. Egyfajta gyártómetódus, ami nem vár paramétert, csak visszaad egy eredményt. Akár egy objektumpéldányt:
Supplier<String> domainName = () -> "egalizer.hu";
domainName.get();
Function<T,R>: olyan függvényt reprezentál, ami egy T típusú paramétert fogad és egy R típusú eredményt ad.
Function<Double, Double> multiPi = x -> x * Math.PI; multiPi.apply(3.0);
A Function interfésznek van egy statikus identity() metódusa is amivel egyszerűen lehet olyan implementációt gyártani ami a paramétert változatlanul adja vissza (itt például Integer típusút):
Function<Integer, Integer> funct = Function.<Integer> identity();
A fenti alapvető funkcionális interfészeknek létezik típusos verziója is a java.util.function csomagban, de ha megnézzük ezeket, meglepve fogjuk tapasztalni, hogy míg int, long, double, boolean primitív típusokat alkalmazó interfészek léteznek, a többi primitív típus - byte, short, float és char - mintha nem is létezne. Úgy tűnik, minden típus egyenlő de vannak egyenlőbbek. (Erről a kérdésről később még lesz szó.)
A funkcionális interfészeket természetesen kombinálhatjuk is, például így:
Function<Integer, Predicate<Integer>> numberCheck = value -> other -> value > other; List<Integer> numbers = Arrays.asList(5, 8, 23, 56, 2); Long numberCount = numbers.stream().filter(numberCheck.apply(5)).count();
A fenti kódrészletben a numberCount 1 lesz. Bár teljes megértéséhez a stream-ek ismerete is szükséges lesz, most elégedjünk meg annyival, hogy a stream() visszaadja a numbers elemeit, amiből a filter a numberCheck interfész által visszaadott predikátummal kiszűr bizonyos elemeket és azok számosságát adja vissza a count(). Egyébként a leszámolást egyszerűen így is megírhattuk volna:
numberCount = numbers.stream().filter(p -> 5 > p).count();
A fentebb ismertetett előre definiált funkcionális interfészek elnevezéseivel többen is elégedetlenek voltak már a 8-as Java fejlesztése közben is. Mert például van ilyen:
Function<T,R>
meg van ilyen:
BiFunction<T,U,R>
Felmerül a kérdés, hogy minek kellett a BiFunction-nak külön nevet adni, miért nem lett volna elég Function<T,U,R> típust bevezetni? A Java 8 egyik tervezője, Brian Goetz elárulta, hogy a tervezés korai fázisában voltak akik kardoskodtak a többféle Function bevezetése mellett, de a Java-nak van egy olyan tulajdonsága ami miatt fájó szívvel bár de ő is leszavazta ezt a megoldást. Ez a tulajdonság pedig a típustörlés. A Java típustörlése miatt a Function<T1,T2> és Function<T1,T2,T3> vagy Function<T1,T2,T3,...Tn> típusok között a bájtkód szintjén semmi különbség nincs. Ezért kreatívkodtak inkább különböző nevekkel. Amennyiben a típustörléssel egy jövőbeli verzióban majd tudnak valamit kezdeni, akkor később persze változhat a helyzet és bevezethetik a többféle Function-t.
A tisztánlátás miatt a következőkben összefoglalom az API által adott különböző funkcionális interfészeket.
Funkcionális interfészek void visszatérési típussal.
| Függvény típusa | Lambda kifejezés | Ismert funkcionális interfészek |
|---|---|---|
| Nullaszoros | () -> doSomething() | Runnable |
| Egyszeres | param -> System.out.println(param) | Consumer IntConsumer LongConsumer DoubleConsumer |
| Bináris | (console,text) -> console.print(text) | BiConsumer ObjIntConsumer ObjLongConsumer ObjDoubleConsumer |
| n-szeres | (sender,host,text) -> sender.send(host, text) | sajátot kell definiálni |
Funkcionális interfészek T visszatérési típussal.
| Függvény típusa | Lambda kifejezés | Ismert funkcionális interfészek |
|---|---|---|
| Nullaszoros | () -> "Visszatérek!" | Callable Supplier BooleanSupplier IntSupplier LongSupplier DoubleSupplier |
| Egyszeres | n -> n + 1 n -> n <= 0 |
Function IntFunction LongFunction DoubleFunction IntToLongFunction IntToDoubleFunction LongToIntFunction LongToDoubleFunction DoubleToIntFunction DoubleToLongFunction UnaryOperator IntUnaryOperator LongUnaryOperator LongUnaryOperator Predicate IntPredicate LongPredicate DoublePredicate |
| Bináris | (a,b) -> a > b ? 1 : 0 (x,y) -> x + y (x,y) -> x % y == 0 |
Comparator BiFunction ToIntBiFunction ToLongBiFunction ToDoubleBiFunction BinaryOperator IntBinaryOperator LongBinaryOperator DoubleBinaryOperator BiPredicate |
| n-szeres | (sender,host,text) -> sender.send(host, text) | sajátot kell definiálni |
Ezek után bónusz lambda és funkcionális interfész példaként nézzük a Runnable interfész szokványos és újszerű használatát.
package hu.egalizer.java8; public class RunnableTest { public static void main(String[] args) { // Runnable anonim osztállyal Runnable r1 = new Runnable() { @Override public void run() { System.out.println("Hello world 1!"); } }; // Runnable lambdával Runnable r2 = () -> System.out.println("Hello world 2!"); // Fussunk! r1.run(); r2.run(); } }
Problémák
Ahogyan a költő mondja: nincsen funkcionális interfész és rózsa tövis nélkül. A tövisek egy része a metódustúlterhelésben rejlik. Tegyük fel (de tényleg csak tegyük fel) hogy van egy run() metódusunk ami Callable típusú paramétert vár. Bővíteni szeretnénk, hogy most már Supplier típust is fogadjon el:
static <T> T run(Callable<T> c) throws Exception { return c.call(); } static <T> T run(Supplier<T> s) throws Exception { return s.get(); }
Ez Java 7 szemmel teljesen jónak tűnik, de próbáljuk csak meghívni lambda kifejezéssel:
run(() -> "Fordulj!");
Ezt a fordítási hibát fogjuk kapni:
javac.exe hu/egalizer/java8/Test.java
hu\egalizer\java8\Test.java:57: error: reference to run is ambiguous
run(() -> "Fordulj!");
^
both method <T#1>run(Callable<T#1>) in Test and method <T#2>run(Supplier<T#2>) in Test match
where T#1,T#2 are type-variables:
T#1 extends Object declared in method <T#1>run(Callable<T#1>)
T#2 extends Object declared in method <T#2>run(Supplier<T#2>)
1 error
Ez bizony balszerencse. Ilyen esetben sajnos nem tudunk mást tenni, mint régi jól bevált megoldásokat alkalmazni:
run((Callable<Object>) (() -> "Fordulj!")); // vagy: run(new Callable<Object>() { @Override public Object call() throws Exception { return "Fordulj!"; } });
Persze ha a generikus T típus helyett a két metódust két konkrét eltérő típussal definiáljuk, akkor a fordító a lambda kifejezésből már nagy eséllyel kikövetkezteti, melyiket kell meghívni.
Az anonim osztályoknak egyébként egyik hátránya a lambdákhoz képest, hogy a fordító minden anonim belső osztályhoz egy új class fájlt készít. A fájlnév általában ClassName$1.class, ahol a ClassName annak az osztálynak a neve, ahol az anonim belső osztályt definiáltuk, ezt követi a dollár jel és egy szám. Ez a megoldás többek között azért sem kívánatos, mert használat előtt minden class fájlt betölteni és ellenőrizni kell, ami az alkalmazás induláskori teljesítményére van hatással. Ha a lambdák is anonim belső osztályokká fordítódnának, akkor minden lambdához új class fájlunk lenne és minden anonim osztály helyet foglalna a metaspace-en.
Hatókörök
A hasonlóságok ellenére azért a lambda és az anonim osztály nem ugyanaz. Többek között abban is különböznek, hogy anonim osztály használatakor új hatókör jön létre. A befoglaló hatókör helyi változóit felüldefiniálhatjuk úgy, hogy azonos névvel bevezetünk új változókat. A this kulcsszót is használhatjuk az anonim osztályban referenciaként a saját példányára, illetve a ClassName.this megoldást pedig a befoglaló osztály példányára. A lambda kifejezések viszont a befoglaló hatókörben dolgoznak és nem tudunk felülírni abból a hatókörből változókat a lambda belsejében. Ebben az esetben a this kulcsszó a befoglaló példányt hivatkozza. Például:
package hu.egalizer.java8; public class ScopeExample { public String field = "ScopeExample public field value"; public void method() { final String variable = "ScopeExample variable value"; Runnable runinner = new Runnable() { String field = "Runnable field value"; @Override public void run() { System.out.println("Inner Class field: " + field); System.out.println("Inner Class this.field: " + this.field); System.out.println("Inner Class ScopeExample.this.field: " + ScopeExample.this.field); System.out.println("Inner Class variable: " + variable); String variable = "";// megtehetjük, de ezzel innentől kezdve felüldefiniáljuk a külső variable változót } }}; Runnable runlambda = () -> { String field = "lambda field value"; System.out.println("Lambda field: " + field); System.out.println("Lambda this.field: " + this.field); System.out.println("Lambda ScopeExample.this.field: " + ScopeExample.this.field); System.out.println("Lambda variable: " + variable); // String variable=""; - nem fordul le }; runinner.run(); runlambda.run(); } public static void main(String[] args) { new ScopeExample().method(); } }
Ha lefuttatjuk a method() metódust akkor a következő eredményt kapjuk:
Inner Class field: Runnable field value Inner Class this.field: Runnable field value Inner Class ScopeExample.this.field: ScopeExample public field value Inner Class variable: ScopeExample variable value Lambda field: lambda field value Lambda this.field: ScopeExample public field value Lambda ScopeExample.this.field: ScopeExample public field value Lambda variable: ScopeExample variable value
Látható, hogy a this.field a belső osztályban a saját mezőt éri el, míg lambda esetén a this.field a ScopeExample osztályban lévő field-hez biztosít hozzáférést, nem pedig a lambda belsejében definiált field értékéhez. Egyébként nagy kódblokkok helyett ajánlatos inkább egysoros lambdákat írni, mert a lambda egy kifejezés nem pedig egy elbeszélés kellene hogy legyen. Ez inkább csak az érthetőség miatt fontos, teljesítménybeli hatása egyébként nincs.
Most, hogy megismertük a Java 8 talán legfontosabb két nyelvi újítását, érdemes kissé megnézni, mi van a motorháztető alatt. Bár a 7-es verziót kevésbé jelentős mérföldkőnek tartják, mint a 8-at, azért nagyon sok olyan fejlesztést tartalmazott, amire szükség volt a 8-as újdonságaihoz. Érdemes megismerni ezeket az újdonságokat is, mert az egyik legfontosabb ilyen fejlesztés például a lambda kifejezések alapját jelenti.
Egy gondolat a típusokról
Mielőtt megnéznénk, mi van a lambda kifejezések mögött, vizsgáljuk meg kicsit az értékadások témakörét. A Java-ban az értékadás szintaxisával kapcsolatosan sokszor felmerült már a bőbeszédűség vádja. Java 6-ban például így kell értékadást írnunk:
Map<String, String> map = new HashMap<String, String>();
Ez a kifejezés redundáns információkat tartalmaz ezért jó lenne, ha a fordító több mindent magától kitalálna és a programozónak nem kellene mindent expliciten megfogalmaznia. Az olyan nyelv mint például a Scala a kifejezésekből nagyon sok típuskövetkeztetést meg tud csinálni és egy értékadás például így is leírható:
val map = Map("x" -> 24, "y" -> 25, "z" -> 26);
A val azt jelzi, hogy ennek a változónak ezután nem lehet újra értéket adni (mint a final kulcsszó a Javában). Ebben a formában egyáltalán nem kell típusinformációt megadni a változóhoz, mert a Scala fordító a jobb oldali kifejezésből magától kitalálja. A változó pontos típusát meghatározza az, hogy milyen értéket rendelnek hozzá. A Java 7-ben is megjelent egy nagyon egyszerű típuskövetkeztetés és ennek köszönhetően az értékadások immár a következőképpen is leírhatók (az ún. gyémánt operátorral):
Map<String, String> m = new HashMap<>();
A fő különbség a Scala és eközött, hogy míg a Scala-ban az értékeknek van explicit típusuk, ami meghatározza a változók típusát, a Java 7-ben a változók típusa explicit és az értékek típusa lesz kikövetkeztetve. Bár voltak akik a Scala-szerű megoldást szerették volna látni a Java 7-ben is, az kevésbé fért volna össza a lambda kifejezésekkel.
Java 8-ban a fentebb már megismert Function funkcionális interfésszel így is le tudunk írni egy függvényt ami 2-t és egy egészet ad össze:
Function<Integer, Integer> func = x -> x + 2;
Ez a forma itt most azért jó mert hasonló a Scala-beli megfelelőjéhez. Azzal, hogy a func típusát expliciten megadjuk a Function-nek (egész típusú paramétert vár és egy másik egészet ad vissza eredményként), a Java fordító képes kikövetkeztetni az x paraméter típusát: Integer. Ezt a mintát már láttuk a Java 7 gyémánt szintaxisban: megadjuk a változók típusát és kikövetkeztetődik az érték típusa. Lássuk ennek megfelelőját Scala nyelven:
val func = (x : Int) => x + 2;
Itt expliciten meg kell adni az x paraméter típusát, mivel a func-nak nincs konkrét típus megadva és enélkül nem lehetne miből következtetni.
A metódus handle-ök is a Java 7-ben jelentek meg és bár a legtöbb Java fejlesztő szinte sosem találkozik velük élete folyamán, a lambda kifejezések működéséhez alapvető fontossággal bírnak. A metódus handle fejlesztői szemszögből tulajdonképpen egy metódusra vagy konstruktorra hivatkozó típusos referencia. Ahhoz, hogy megértsük ezt a fogalmat, elevenítsük fel, hogy egy Java metódus mely négy összetevőből épül fel:
Ez azt jelenti, hogy ha metódusokra akarunk hivatkozni, akkor először szükség van valamire, amivel hatékonyan ábrázolhatjuk a metódus aláírásokat (és nem a szörnyű Class<?>[] buherálást használni, amire a reflection-nel kényszerítve vagyunk). A Java 7-ben bevezetett Method Handles API-ban ezt a szerepet a java.lang.invoke.MethodType osztály játssza, aminek immutable példányai használatosak az aláírások ábrázolásához. (A metódus aláírásának throws záradéka semmilyen szerepet nem játszik a metódus handle esetén, azzal valójában a Java fordítón kívül más nem is foglalkozik, a bájtkódban már nem jelenik meg.)
Egy MethodType példány megszerzéséhez a methodType gyártómetódust kell használni. Ez egy nem rögzített paraméterszámmal meghívható (variadic) metódus, ami paraméterként class objektumokat vár. Az első paraméter a visszatérési típusnak megfelelő class objektum, a többi pedig a metódusparaméterek típusainak megfelelő class objektum-felsorolás. Például:
// toString() aláírása MethodType mtToString = MethodType.methodType(String.class); // Setter metódus aláírása MethodType mtSetter = MethodType.methodType(void.class, Object.class); // A Comparator<String> compare() metódusának aláírása MethodType mtStringComparator = MethodType.methodType(int.class, String.class, String.class);
Ahhoz, hogy metódus handle-ünk legyen, egy MethodType mellett kell a metódust definiáló név és osztály is. A handle-t ezek birtokában a statikus MethodHandles.lookup() metódussal kapjuk meg. Ez egy ún. "lookup kontextust" ad vissza (egy MethodHandles.Lookup példány), ami az aktuálisan futó (vagyis a lookup-ot hívó) metódus elérési jogain alapul. A lookup reprezentálja gyakorlatilag azt a helyet a kódunkban ahol létre akarjuk hozni a metódus handle-t. Létezik MethodHandles.publicLookup() is, amivel csak a publikus metódusokat tudjuk elérni (privát vagy protected metódusok esetén ennél java.lang.IllegalAccessException kivételt kapunk). A Lookup objektumnak számos olyan metódusa van, aminek a neve "find" szóval kezdődik. Ilyen például a findVirtual(), findConstructor(), findStatic(). Ezek a metódusok fogják visszaadni a tulajdonképpeni metódus handle-t, de csak ha a lookup kontextust olyan metódusban hozták létre, ami elérheti (meghívhatja) a kért metódust. (A find... metódusok nevéből elég egyértelműen kikövetkeztethető, hogy melyik milyen metódus handle megszerzésére való.) A reflection-től eltérően nincs mód rá, hogy kicselezzük ezt a hozzáférés-szabályozást (nincs setAccessible()-höz hasonló metódusuk), de az objektumot már továbbadhatjuk olyan metódusoknak amiknek egyébként nem lenne joguk meghívni azt a metódust. Persze csak ha megbízunk bennük... Ja, és míg el nem felejtem: a MethodHandle példányai is immutable tulajdonságúak!
Metódus handle-t egyébként meglepő módon nem csak metódusokra, hanem mezőkre is létre tudunk hozni. Ezekre a Lookup objektum findGetter, findSetter illetve ezek statikus mezőkre vonatkozó változatai használhatóak. A nevük ne legyen megtévesztő: nem szükséges, hogy a mezőkre legyen konkrét getter vagy setter definiálva az osztályban, ezek anélkül is használhatóak (példát lentebb lehet találni). (A Java 9-ben egyébként megjelent a java.lang.invoke.VarHandle API is, ami bevezeti a változó handle-öket.)
Egy példa arra, hogyan tudunk metódus handle-t előállítani (a példa saját osztályának toString() metódusára hoz létre egy metódus handle-t):
public MethodHandle getToStringMH() { MethodHandle result = null; MethodType mt = MethodType.methodType(String.class); MethodHandles.Lookup lk = MethodHandles.lookup(); try { result = lk.findVirtual(getClass(), "toString", mt); } catch (NoSuchMethodException | IllegalAccessException ex) { throw (AssertionError) new AssertionError().initCause(ex); } return result; }
A MethodHandle-nek két metódusa van, amivel meghívhatjuk a metódus handle-t. Mindkét metódus a fogadó objektumot és a paramétereket várja, az aláírásuk:
public final Object invoke(Object... args) throws Throwable; public final Object invokeExact(Object... args) throws Throwable;
A kettő között az a különbség, hogy az invokeExact() megpróbálja közvetlenül a pontos argumentumokkal hívni a metódus handle-t. Az invoke() viszont szükség esetén tudja kissé módosítani a metódus argumentumait. Végez például egy asType() konverziót, ami át tudja alakítani az argumentumokat az alábbi szabályoknak megfelelően:
Lássunk néhány egyszerű meghívási példát! A legelső eset a legegyszerűbb is; egy InvokeExample példányon meghívjuk a sayHello virtuális metódust:
package hu.egalizer.java8; import java.lang.invoke.MethodHandle; import java.lang.invoke.MethodHandles; import java.lang.invoke.MethodType; public class InvokeExample { public void sayHello(String name) { System.out.println("Hello " + name); } public static void main(String[] args) throws Throwable { MethodHandle sayHelloHandle = MethodHandles.lookup().findVirtual( InvokeExample.class, "sayHello", MethodType.methodType(void.class, String.class)); sayHelloHandle.invoke(new InvokeExample(), "Morgan"); } }
A kívánt objektumot "kötni" (bind) is lehet a metódus handle-höz, így megspóroljuk az átadását a többszörös invokációnál: A fenti main metódus ez esetben így néz ki (a lookup változatlan):
public static void main(String[] args) throws Throwable { MethodHandle sayHelloHandle = MethodHandles.lookup().findVirtual( InvokeExample.class, "sayHello", MethodType.methodType(void.class, String.class)); MethodHandle binded = sayHelloHandle.bindTo(new InvokeExample()); binded.invokeWithArguments("T-Rex"); }
Mivel a MethodHandle immutable, ezért új példány készül belőle amikor megadjuk neki a használandó objektumot, aztán onnantól kezdve már lehet durvulni az invokeWithArguments metódussal ahol ezt már nem kell újra megtenni. Ha esetleg ezzel bind nélkül próbálkoznánk, akkor egy szépséges java.lang.invoke.WrongMethodTypeException lesz a jutalmunk.
Következzen egy icipicit trükkösebb példa egy String hashCode metódusának meghívásához:
Object rcvr = "baromijó"; MethodType mt = MethodType.methodType(int.class); MethodHandles.Lookup l = MethodHandles.lookup(); MethodHandle mh = l.findVirtual(rcvr.getClass(), "hashCode", mt); int ret = (int) mh.invoke(rcvr); System.out.println(ret);
Egy példa a getterek, setterek használatára (getterek és setterek esetén MethodType-ot nem kell megadni, csak a mező típusát):
package hu.egalizer.java8; import java.lang.invoke.MethodHandle; import java.lang.invoke.MethodHandles; public class InvokeGetterExample { String eztKapdKi; public static void main(String[] args) throws Throwable { InvokeGetterExample iex = new InvokeGetterExample(); iex.eztKapdKi = "első"; MethodHandle getterHandle = MethodHandles.lookup(). findGetter(InvokeGetterExample.class, "eztKapdKi", String.class); System.out.println(getterHandle.invoke(iex));// első MethodHandle setterHandle = MethodHandles.lookup(). findSetter(InvokeGetterExample.class, "eztKapdKi", String.class); setterHandle.invoke(iex, "második"); System.out.println(getterHandle.invoke(iex));// második } }
A metódus handle-öket tömbökkel is meghívhatjuk, ekkor az asSpreader() metódussal készíteni kell belőle egy új példányt, majd azt már bombázhatjuk tömbökbe rejtett paraméterekkel. A tömböt mindig a paraméterlista végén kell megadni és a paramétereknek csak egy részét is tartalmazhatja, a paraméterszámot az asSpreader()-nek kell megadni. Meghíváskor az aktuális paraméterek pozícióinak természetesen igazodni kell a metódus aláírásához. Egy példa:
package hu.egalizer.java8; import java.lang.invoke.MethodHandle; import java.lang.invoke.MethodHandles; import java.lang.invoke.MethodType; public class SpreaderExample { String content; public boolean equals(SpreaderExample a, SpreaderExample b) { return a.content.equals(b.content) && b.content.equals(content); } public SpreaderExample(String content) { super(); this.content = content; } public static void main(String[] args) throws Throwable { MethodHandle equals = MethodHandles.lookup().findVirtual(SpreaderExample.class, "equals", MethodType.methodType(boolean.class, SpreaderExample.class, SpreaderExample.class)); // minden paramétert tömbbe teszünk MethodHandle methodHandle = equals.asSpreader(Object[].class, 3); System.out.println( (boolean) methodHandle.invokeExact(new Object[] { new SpreaderExample("java"), new SpreaderExample("java"), new SpreaderExample("java") })); // true // csak a paraméterek egy részét adjuk át tömbként methodHandle = equals.asSpreader(Object[].class, 1); System.out.println( (boolean) methodHandle.invokeExact(new SpreaderExample("java"), new SpreaderExample("java1"), new Object[] { new SpreaderExample("java") })); // false } }
Bonyolultabb feladatok esetén a metódus handle-ök sokkal tisztább módszert kínálnak a dinamikus programozási feladatok megoldásához, mint a reflection. Ráadásul a metódus handle-öket már a kezdetektől úgy tervezték, hogy jól működjenek a JVM alacsony szintű végrehajtási modelljével és ezért bizony sokkal jobb teljesítményt is nyújthatnak. (Bár a teljesítmény kérdése eléggé komplex dolog ez esetben. A teljesítménybeli javulás egyik oka az, hogy a jogosultságellenőrzés a metódus handle-öknél létrehozási időben történik, reflection esetén pedig hívási időben.)
Szintén még a Java 7-ben jelent meg a lambda kifejezések működéséhez másik alapvető fontosságú összetevő. Ez pedig az első új bájtkód a Java 1.0 óta: az invokedynamic. Ez a bájtkód eredetileg arra lett tervezve, hogy dinamikus működést biztosítson olyan JVM-en futó nyelveknek, mint például a JRuby. Java 7-es fejlesztőknek ezt szinte lehetetlen kihasználni, mert a 7-es javac semmilyen körülmények között nem generál olyan class fájlt, ami tartalmazná. Az invokedynamic kezdeti munkálatai még 2007-re nyúlnak vissza, az első sikeres dinamikus meghívás pedig 2008. augusztus 26-án történt. Ez még a Sun felvásárlását is megelőzte, tehát ezen a tulajdonságon elég régóta dolgoztak, legalábbis informatikai mércével mérve. Az volt a szándék, hogy a felhasználói kód határozza meg a vezérlésátadást a metódus handle API-val de úgy, hogy az ne szenvedjen a reflection teljesítménybeli és biztonsági problémáitól. Konkrét cél volt, hogy amikor rendesen kiforrott lesz, ugyanolyan gyors legyen mint a szokványos metódushívás (invokevirtual).
Egy átlagos Java metódushívás olyan bájtkóddá fordul, amit hívási helynek (call site) hívnak. Ez tartalmaz egy vezérlésátadási opkódot (például invokevirtual a példánymetódusok híváshoz) és egy konstanst (egy offszet az osztály konstanskészletében), ami megmutatja, hogy melyik metódust kell meghívni. A különböző vezérlésátadási opkódoknak különböző szabályai vannak, de a Java 7-ig a konstans mindig egyértelmű útmutatást adott arra nézvést, hogy melyik metódust kell meghívni.
Az invokedynamic a már létező metódushívást vezérlő bájtkódokhoz csatlakozik. Ez a négy opkód implementált minden metódushívást, amit a Java programozók használtak a Java 7-ig, vagyis:
Felmerülhet a kínzó kérdés: miért van szükség négy opkódra? Nézzünk egy egyszerű példát, ami olyan zseniális, hogy a négyből három opkódot tartalmaz:
package hu.egalizer.java8; import java.util.ArrayList; import java.util.List; public class TestInvoke { public static void main(String[] args) { TestInvoke test = new TestInvoke(); test.run(); } private void run() { List<String> list1 = new ArrayList<>(); list1.add("Kirk"); ArrayList<String> list2 = new ArrayList<>(); list2.add("Spock"); } }
A javap eszközzel fejtsük vissza a bájtkódot:
javap.exe -c -private hu.egalizer.java8.TestInvoke
Compiled from "TestInvoke.java"
public class hu.egalizer.java8.TestInvoke {
public hu.egalizer.java8.TestInvoke();
Code:
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: new #1 // class hu/egalizer/java8/TestInvoke
3: dup
4: invokespecial #16 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokespecial #17 // Method run:()V
12: return
private void run();
Code:
0: new #23 // class java/util/ArrayList
3: dup
4: invokespecial #25 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: ldc #26 // String Kirk
11: invokeinterface #28, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
16: pop
17: new #23 // class java/util/ArrayList
20: dup
21: invokespecial #25 // Method java/util/ArrayList."<init>":()V
24: astore_2
25: aload_2
26: ldc #34 // String Spock
28: invokevirtual #36 // Method java/util/ArrayList.add:(Ljava/lang/Object;)Z
31: pop
32: return
Ez a négyből három opkódot bemutat (a kimaradt invokestatic pedig elég triviálisan előhozható). Elsőként nézzük meg a következő két hívást (a run metódus 11. és 28. bájtjánál):
list1.add("Kirk"); list2.add("Spock");
Ezek a forráskódban hasonlónak tűnnek, de a bájtkódban már első látásra különböznek. A javac számára a list1-nek statikus List<String> típusa van és a List egy interface. Ez esetben nem lehet meghatározni fordítási időben a metódustábla indexet. Az invokeinterface a metódus kikeresését futási időre halasztja. A list2.add("Spock"); hívást viszont már a list2-n kell elvégezni, ami osztály típusú: ArrayList<String>. Ez azt jelenti, hogy a metódus indexe már fordítási időben ismert. A fordító tehát egy invokevirtual utasítást tud generálni a pontos vtable bejegyzéshez. A metódus végleges kiválasztása természetesen most is csak futásidőben fog megtörténni, hiszen ezzel van biztosítva a metódus felüldefiniálás, de a vtable bejegyzés indexe már fordítási időben meghatározható. A példa ezeken kívül az invokespecial lehetséges felhasználási eseteit is bemutatja. Ez az opkód olyan esetekben használatos, amikor a metódusfelülírás vagy nem kívánatos vagy nem lehetséges. A mintakód által bemutatott két példa a privát metódusokat és a super hívásokat mutatja (ezeken kívül még a konstruktorokat is így hívjuk).
Nem kell megrémülni a fenti címtől, csak egy őrült hajnalon született meg a billentyűim között amint az alább elmesélendő történeten dolgoztam.
Azt még az egyszeri ember is tudja, hogy Javában a metódusok alapértelmezetten - néhány kivételtől eltekintve - virtuálisak. Ez azt jelenti, hogy egy leszármazott osztályban azonos aláírással rendelkező metódus felülírhatja, vagyis megváltoztathatja a metódus "viselkedését". (Ezért nincs is külön virtual kulcsszó a nyelvben, mint például a C++-ban vagy a szép emlékű Delphi/Object Pascalban.) A virtuális metódushívások belső megvalósításához a JVM (legalábbis a HotSpot) sok más nyelvhez hasonlóan egy ún. virtuális metódustáblát használ. Ez a metódustábla hivatkozásokat tartalmaz az osztály összes metódusának bájtkódjára és metódushíváskor ezt használja fel a JVM, hogy tudja, hová kell ugrania a vezérlésnek. Ezt a táblát minden osztály az ősétől örökli és kiterjeszti saját metódusainak bejegyzéseivel.
Egy példa többet ér ezer szónál ér ezért tekintsük a következő két osztályt:
package hu.egalizer.java8; class BaseClass { public void method1() { } public void method2() { } public void method3() { } } public class ChildClass extends BaseClass { public void method2() { }// felülírja a BaseClass metódusát public void method4() { } }
Ebben az esetben a virtuális metódustábla logikailag valahogy így néz ki:
BaseClass
ChildClass
A BaseClass metódustáblájának 1. indexe a method1() metódus bájtkódjára hivatkozik, és így tovább. A ChildClass metódustáblája megtartja ("lemásolja") ősének a tartalmát és sorrendjét és csak a method2() hivatkozást írja abban felül (a method4()-et pedig hozzáfűzi). Az invokevirtual bájtkód implementációját így optimalizálni lehet azért, mert a method3() metódus mindig a 3. bejegyzés a virtuális metódustáblában bármely olyan objektum esetén amelyen ez a metódus valaha meg fog hívódni. A tábla indexe már fordítási időben meghatározható, a hívás egyszerű és gyors.
Az invokeinterface esetén viszont ilyen optimalizálás nem lehetséges! Tekintsük a következő példát:
package hu.egalizer.java8; public interface MyInterface { void ifaceMethod(); } class AnotherClass extends ChildClass implements MyInterface { public void method4() { }// a ChildClass felülírása public void ifaceMethod() { } } class MyClass implements MyInterface { public void method5() { } public void ifaceMethod() { } }
Ez esetben a virtuális metódustábla valahogy így fog kinézni:
AnotherClass
MyClass
Látható, hogy az AnotherClass az interfész implementált metódusát az 5. bejegyzésen tárolja, a MyClass pedig a másodikon. A kívánt interfész metódus meghívásához az invokeinterface implementációjának mindig végig kell néznie a teljes metódustáblát és az invokevirtual-hoz hasonló optimalizálás nem lehetséges. Ezen kívül vannak még egyéb különbségek is, amelyek további hátrányt okoznak az invokeinterface esetén a teljesítményben. Az invokeinterface például olyan objektum referenciákkal is használható, amelyek valójában nem is implementálják az interface-t, így azt is mindig futásidőben meg kell vizsgálni, hogy egy metódus létezik-e egyáltalán a táblában és ha nem akkor kivételt kell dobni. A modern JVM-implementációk persze számos varázslatot bevetnek annak érdekében, hogy az invokeinterface és invokevirtual között ne legyen számottevő teljesítménybeli különbség, de mivel nem JVM-kézikönyvet írok, erről a témakörről talán elég is ennyi ízelítő.
Az invokevirtual bájtkód egy kétbájtos paramétert használ, ami egy index az osztály futásidejű konstanskészletéhez (constant pool). Azon az indexen található egy szimbolikus referencia a kívánt metódushoz (ezt a javap szépen ki is írja nekünk: java/util/ArrayList.add:(Ljava/lang/Object;)Z). Azt a JVM feloldja és azután történik a metódushívás. Az invokestatic és invokespecial is egy konstanskészlet-indexet kap paraméterként. Az invokeinterface-nek három paramétere van. Első ezek közül szintén konstanskészlet-index. A második paraméter a paraméterek méretét határozza meg, a negyedik pedig konstansként 0, ennek a két plusz paraméternek ma már nincs jelentősége, csak történelmi okokból szerepel és a visszamenőleges kompatibilitás miatt van megtartva.
Az invokedynamic eltér a korábbi metódushívási módszerektől. Ahelyett, hogy egy olyan referenciára hivatkozna a konstanskészletben, ami közvetlenül megmutatja, hogy melyik metódust kell meghívni, az invokedynamic egy indirekciós mechanizmust valósít meg, ami lehetővé teszi, hogy a felhasználói kód döntse el futásidőben, melyik metódust kell meghívni.
Az invokedynamic utasításoknak nincs fogadó objektumuk, hanem az invokestatic-hoz hasonlóan viselkednek: egy statikus, ún. bootstrap metódust (BSM) hívnak meg, ami egy CallSite típusú objektumot ad vissza. Ez egy (target-nek hívott) metódus handle-t tartalmaz, ami azt a metódust reprezentálja, amit majd végre kell hajtani az invokedynamic utasítás eredményeként. De maga az invokedynamic csak ennek az előállításáért felel a BSM-en keresztül. Amikor egy invokedynamic-ot tartalmazó osztály betöltődik, a Java terminológia azt mondja, hogy a hívási helyek még nincsenek befűzve (unlaced állapot), de miután a BSM visszatér, az eredményül kapott CallSite és metódus handle már a hívási helyre "befűzött" (laced) állapotban van.
A Java 8 fordítója már generál invokedynamic-ot és ez használatos a motorháztető alatt a lambda kifejezések és alapértelmezett metódusok implementálására és ez az elsődleges hívási módszer a Nashorn (JavaScript motor) számára. (Egyébként a Java 8 korai prototípusaiban a lambda kifejezések még anonim belső osztályokká fordítódtak.)
A BSM-nek elvileg bármilyen neve lehet, Java 8-ban a lambda kifejezésekhez az osztálykönyvtár biztosít egy ún. lambda metafactory-t BSM-ként. Ezt a java.lang.invoke.LambdaMetafactory.altMetafactory() metódus valósítja meg. Ennek az aláírása valahogy így néz ki:
static CallSite altMetafactory(MethodHandles.Lookup caller, String invokedName,
MethodType invokedType, Object... args);
Tehát amikor a vezérlés elsőként ér el egy invokedynamic bájtkódot, meghívódik a BSM, ami visszaad egy CallSite objektumot. Ez egy metódus handle-t tartalmaz, ami már tartalmazza az invokedynamic hívás valódi eredményét, vagyis hogy valójában melyik metódust kell majd meghívni. Így a bootstrap metóduson keresztül tudja a felhasználói kód megadni a hívandó metódust.
A fordító a lambda kifejezést átalakítja egy ún. "szintetikus metódussá", aminek megvan a megfelelő aláírása és tartalmazza a lambda törzsét is. A lambda metafactory BSM-jének a paraméterei között kell egy metódus handle erre a szintetikus metódusra és a lambda megfelelő aláírására. Egy kifejezés tehát mint ez:
Function<Integer, Integer> fn = x -> x + 2;
erre az invokedynamic hívásra fog lefordulni:
0: invokedynamic #19, 0 // InvokeDynamic #0:apply:()Ljava/util/function/Function;
5: astore_1
Amikor egy invokedynamic utasítás befejeződik, egy objektum áll a verem tetején, ami implementálja a Function interface-t és amely tartalmazza a lambda kifejezést a saját apply() metódusának törzseként. A kód további része ezek után szokványosan fut tovább.
A szintetikus metódust a Java 8 fordító privátként gyártja le a fenti kód esetén a következő bájtkóddal (látható, hogy ennek megvan a szükséges metódus aláírása: egy egészet vár és azzal tér vissza):
private static java.lang.Integer lambda$0(java.lang.Integer);
Code:
0: aload_0
1: invokevirtual #40 // Method java/lang/Integer.intValue:()I
4: iconst_2
5: iadd
6: invokestatic #46 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
9: areturn
A non-capturing lambdák egyszerű statikus metódussá fordítódnak, aminek pontosan olyan aláírása van mint a lambda kifejezésnek és ugyanabban az osztályban készül el amiben a lambda kifejezés használatban van. Az ilyen metódusok nevében a $0, $1, stb... nem belső osztályt jelent, hanem csak azt mutatja, hogy ez egy fordító által generált kód. A capturing lambda esete kicsit összetettebb mert a használt változókat a lambda formális paramétereivel együtt át kell valahogyan adni a generált metódusnak. Ez esetben a használt változók is paraméterként kerülnek átadásra (ezért is final típusúak logikailag a lambda kifejezésnek) és a metódus aláírásában megelőzik a lambda kifejezés paramétereit. Ez a megoldás egyébként nincs kőbe vésve, mert az invokedynamic bájtkód használata révén a jövőben más megoldás is lehetséges.
Ha esetleg az egész invokedynamic még mindig zavaros lenne, lássuk Java kód szintaxissal is, hogy működik logikailag a dolog. Legyen mondjuk a következő kódrészletünk:
void printElements(List<String> strings) { strings.forEach(item -> System.out.printf("Item = %s", item)); }
Amikor ezt a Java fordító lefordítja, akkor logikailag valami ennek megfelelő dolog készül belőle:
private static void lambda_forEach(String item) { // ezt a Java fordító generálja System.out.printf("Item = %s", item); } private static CallSite bootstrapLambda(Lookup lookup, String name, MethodType type throws LambdaConversionException, NoSuchMethodException, IllegalAccessException { // lookup : a VM biztosítja // name : "lambda_forEach", a VM biztosítja // type : String -> void MethodHandle lambdaImplementation = lookup.findStatic(lookup.lookupClass(), name, type); return LambdaMetafactory.metafactory(lookup, "accept", MethodType.methodType(Consumer.class), // a lambda factory aláírása MethodType.methodType(void.class, Object.class), // a Consumer.accept metódus aláírása a típustörlés után lambdaImplementation, // a lambda törzsét tartalmazó metódusra hivatkozó referencia type); } void printElements(List<String> strings) { Consumer<String> lambda = // invokedynamic# bootstrapLambda, #lambda_forEach strings.forEach(lambda); }
Az invokedynamic utasítást pedig a következő Java kódrészlet mutatja be:
private static CallSite cs; void printElements(List<String> strings) throws Throwable { Consumer<String> lambda; // begin invokedynamic if (cs == null) { cs = bootstrapLambda(MethodHandles.lookup(), "lambda_forEach", MethodType.methodType(void.class, String.class)); } lambda = (Consumer<String>) cs.getTarget().invokeExact(); // end invokedynamic strings.forEach(lambda); }
A LambdaMetafactory létrehoz egy call site-ot az abban lévő "target" metódus handle-lel. Az ebben lévő gyártómetódus az invokeExact-on keresztül visszaad egy funkcionális interfész implementációt. Ha a lambdának vannak változói, akkor az invokeExact elfogadja ezeket a változókat paraméterként. A LambdaMetafactory valódi kódja egyébként JVM-implementációfüggő.
Természetesen a Java fordító és a JVM sem tökéletes, ezek is tartalmaznak néhány korlátozást és hibát, mint mindjárt látni is fogjuk. (Ezek a cikk elején megjelölt JDK esetén reprodukálhatók.)
Lambdák gyártása metódus handle-ökből
Láttuk, hogy a lambdákat a LambdaMetafactory-val dinamikusan is előállíthatjuk. Ehhez kell egy olyan MethodHandle ami egy funkcionális interfész által deklarált metódus implementációjára mutat. Nézzük ezt a példát:
package hu.egalizer.java8; import java.lang.invoke.CallSite; import java.lang.invoke.LambdaMetafactory; import java.lang.invoke.MethodHandles; import java.lang.invoke.MethodType; import java.util.function.Supplier; public class LambdaGetterClass { private String value = ""; public String getValue() { return value; } public void setValue(final String value) { this.value = value; } public static void main(String[] args) throws Throwable { LambdaGetterClass lambdaGetter = new LambdaGetterClass(); lambdaGetter.setValue("Hello world!"); MethodHandles.Lookup lookup = MethodHandles.lookup(); CallSite site = LambdaMetafactory.metafactory(lookup, "get", MethodType.methodType(Supplier.class, LambdaGetterClass.class), MethodType.methodType(Object.class), lookup.findVirtual(LambdaGetterClass.class, "getValue", MethodType.methodType(String.class)), MethodType.methodType(String.class)); Supplier<String> getter = (Supplier<String>) site.getTarget().invokeExact(lambdaGetter); System.out.println(getter.get()); } }
A fenti main metódus kódja ezzel ekvivalens:
LambdaGetterClass lambdaGetter = new LambdaGetterClass(); lambdaGetter.setValue("Hello world!"); final Supplier<String> elementGetter = () -> lambdaGetter.getValue(); System.out.println(elementGetter.get());
Már láttuk, hogy a MethodHandles.Lookup-nak van egy findGetter nevű metódusa is, ami egy nemstatikus mezőhöz tartozó gettert hoz létre. Nézzük meg mi történik ha lecseréljük a getValue-ra mutató metódus handle-t egy olyanra amit ez hozott létre!
CallSite site = LambdaMetafactory.metafactory(lookup, "get", MethodType.methodType(Supplier.class, LambdaGetterClass.class), MethodType.methodType(Object.class), lookup.findGetter(LambdaGetterClass.class, "value", String.class), MethodType.methodType(String.class));
Ennek a kódnak működnie kellene mert a findGetter probléma nélkül visszaad egy mező getterre mutató metódus handle-t és érvényes aláírása is van. Ha viszont lefuttatjuk a kódot akkor a következő kivételnek örülhetünk:
Exception in thread "main" java.lang.invoke.LambdaConversionException: Unsupported MethodHandle kind: getField hu.egalizer.java8.LambdaGetterClass.value:()String
Érdekes módon a getter létrehozás viszont egész jól működik ha MethodHandleProxies-t használunk (a CallSite helyett):
Supplier<String> getter = MethodHandleProxies.asInterfaceInstance(Supplier.class, lookup.findGetter(LambdaGetterClass.class, "value", String.class) .bindTo(lambdaGetter));
Az asInterfaceInstance metódus létrehozza a megadott funkcionális interfész egy példányát, ami redirektálja a hívását a megadott metódus handle-höz. Meg kell adni neki a kívánt interfészt és a cél MethodHandle-t. A példában a Supplier-ből készít egy új példányt, aminek a hívásait a lookup.findGetter által adott metódus handle-höz továbbítja.
A MethodHandleProxies egyébként nem a legjobb módja a lambdák dinamikus létrehozásának mert csak egy proxy osztályba csomagolja a MethodHandle-t és delegálja az InvocationHandler.invoke hívást a MethodHandle.invokeWithArguments-hez. Ez a módszer reflection-t használ és nagyon lassan működik. Egyébként nem minden metódus handle használható futásidőben lambdák létrehozására, csak ezek:
Egyéb metódus handle-ök LambdaConversionException-t dobnak. A REF_... azonosítót (a JDK dokumentációja referenciafajta - reference kind - néven hivatkozik rá) egyébként a Java belső működéshez használja és a MethodHandleInfo osztályban vannak deklarálva.
Generikus kivételek
Ez a hiba a Java fordítóban van és a throws záradékban definiált generikus kivételekkel kapcsolatos. Legyen a következő generikus interfészünk:
package hu.egalizer.java8; import java.util.concurrent.Callable; interface ExtendedCallable<V, E extends Exception> extends Callable<V> { @Override V call() throws E; }
Ezt próbáljuk meg így használni:
ExtendedCallable<URL, MalformedURLException> urlFactory = () -> new URL("http://localhost"); urlFactory.call();
Ennek a kódnak sikeresen le kellene fordulnia, mert az URL konstruktor dobja a MalformedURLException-t, de mégsem ez a helyzet. A fordító a következő hibaüzenetet köpi:
hu\egalizer\java8\Test.java:35: error: call() in <anonymous hu.egalizer.java8.Test$> cannot implement call() in ExtendedCallable
ExtendedCallable<URL, MalformedURLException> urlFactory = () -> new URL("http://localhost");
^
overridden method does not throw Exception
where V is a type-variable:
V extends Object declared in interface ExtendedCallable
1 error
Ha a lambda kifejezést anonim osztályra cseréljük, semmi gond nincs:
ExtendedCallable<URL, MalformedURLException> urlFactory = new ExtendedCallable<URL, MalformedURLException>() { @Override public URL call() throws MalformedURLException { return new URL("http://localhost"); } }};
A generikus kivételekhez tartozó típuskövetkeztetések tehát nem működnek rendesen amikor lambdákkal együtt használjuk ezeket. (Egyébként ha valaki Eclipse-ben próbálkozik akkor nem fog hibát kapni, az Eclipse ugyanis nem a javac fordítót használja, hanem saját megoldást ami a JDT Core pluginben van és ECJ - Eclipse Compiler for Java a becsületes neve.)
A Java 8 az interface-ek deklarációját további két újdonsággal egészíti ki: a default és statikus metódusokkal. Java 8 előtt ha egy új metódus került egy már használatban lévő interfészbe, akkor az összes az interfészt implementáló nem absztrakt osztálynak implementálnia kellett az új metódust is. Így ha egy osztálykönyvtárba új metódus került, akkor csak úgy lehetett az új verzióra áttérni, ha a library-t használó kódba is átvezettük a változást. Ha tehát lett egy új babarozsa() nevű metódus az interfészben, akkor a használó alkalmazásnak is implementálnia kellett ezt még akkor is, ha amúgy nem is használta ki.
A default metódusok lehetővé teszik új metódusok hozzáadását létező interfészekhez anélkül, hogy megtörné azon interfészek régebbi verzióihoz készült kóddal való kompatibilitást. A default és absztrakt metódusok közötti különbség az, hogy az absztrakt metódusokat kötelező implementálni, de a default metódusokat nem. Ehelyett minden interfésznek biztosítania kell egy ún. alapértelmezett implementációt és az összes implementáló alapból azt örökli. Igény szerint természetesen felüldefiniálhatja. Nézzünk egy példát:
package hu.egalizer.java8; public interface DefaultExample { default String notRequired() { return "Default implementation"; } }
public class DefaultExampleImpl implements DefaultExample { }
public class DefaultExampleImpl2 implements DefaultExample { @Override public String notRequired() { return "Overridden implementation"; } }
A DefaultExample interfész deklarál egy notRequired() default metódust a metódus definíciójában szereplő default kulcsszóval. Az egyik leszármazott osztály, a DefaultExampleImpl implementálja ezt az interfészt, de meghagyja a default metódus alapértelmezett implementációját. Egy másik, a DefaultExampleImpl2 felülírja a default implementációját a sajátjával. Amikor egy default metódust tartalmazó interfészből származtatunk, akkor a következőket tehetjük:
Egy interfészben definiált absztrakt metódust egy leszármazott interfészben defaulttá is lehet tenni, onnantól kezdve az abból leszármazott interfészek már a default implementációt fogják használni. Object-ből örökölt metódusokra egyébként nem lehet default implementációt adni. Költői kérdés egyébként, hogy minek kellett ehhez a default kulcsszót bevezetni, hiszen ha nem adunk meg törzset, akkor a metódus alapértelmezetten absztrakt lesz egy interfészben, static kulcsszóval statikus, tehát ha van törzse, akkor lehetett volna alapértelmezetten default is, kulcsszó nélkül. De lehet, hogy a jobb olvashatóság oltárán áldoztak a Java tervezői az új kulcsszóval. A default metódusok egyébként valójában szimpla virtuális metódusok, a default kulcsszó csak a fordító számára jelent valamit, a bájtkódba egyáltalán nem kerül be ez az információ. Látni fogjuk, hogy ez nem jár következmények nélkül.
Némi megkötés, hogy a default metódusoknál sajnálatos módon néhány kulcsszó nem használható:
A Java 8 a statikus metódusokat is bevezette az interfészeknél (static default metódust viszont nem tudunk definiálni). Íme egy példa:
package hu.egalizer.java8; import java.util.function.Supplier; public interface DefaultExampleFactory { static DefaultExample create(Supplier<DefaultExample> supplier) { return supplier.get(); } }
Az alábbi kis kódrészlet egyben mutatja meg a fenti példákból a default és a statikus metódusokat:
DefaultExample defaultExample = DefaultExampleFactory.create(() -> new DefaultExampleImpl()); System.out.println(defaultExample.notRequired()); defaultExample = DefaultExampleFactory.create(() -> new DefaultExampleImpl2()); System.out.println(defaultExample.notRequired());
A példát egyébként ennél még lehetne szebben is írni, azonban ehhez kelleni fog a következő fejezeben megismerendő metódus referencia fogalma is:
DefaultExample defaultExample = DefaultExampleFactory.create(DefaultExampleImpl::new); System.out.println(defaultExample.notRequired()); defaultExample = DefaultExampleFactory.create(DefaultExampleImpl2::new); System.out.println(defaultExample.notRequired());
A JVM-ben a default metódus implementáció egyébként eléggé hatékony és a metódushívásra szolgáló bájtkódok is támogatják. A default metódusok lehetővé teszik a létező Java interfészeknek a továbbfejlesztését anélkül, hogy meggátolnák a fejlesztési folyamatot. Jó példa erre a java.util.Collection interfészhez adott sok új metódus: stream(), parallelStream(), forEach(), removeIf()...
Úgy tűnhet, hogy a default és statikus metódusok bevezetésével az interfészek és az absztrakt osztályok lényegében ugyanazok lettek. Ez azonban tévedés, hiszen az absztrakt osztályoknak lehet konstruktoruk, sokkal összetettebbek lehetnek és lehet belső állapotuk. A default metódusokat akár úgy is implementálhatjuk, hogy más metódusokat hívnak meg a saját interfészükön, elérhetik saját metódus paramétereiket (ha vannak), viszont az interfész belső állapotához nem férnek hozzá, lévén az interfészeknek nincs is olyanjuk.
Nem minden arany ami default
Bár a default metódusok csábítóak, nem árt az óvatosság: kétszer is gondoljuk meg mielőtt egy metódust defaultnak deklarálunk, mert komplex rendszerekben kétértelműséghez és fordítási hibákhoz vezethet. Probléma főként a többszörös öröklődésnél jöhet elő. A Java esetén korábban csak definíciós szinten volt többszörös öröklődés, implementáció esetén nem. A default metódusok bevezetése felkavarta az állóvizet. Tegyük fel, hogy egy osztály több interfészt is implementál, amik mind tartalmaznak egy durvasag() metódust. Ha mindegyik interfészben absztrakt a metódus, akkor - akárcsak eddig - az osztálynak implementálnia kell azt. De mi van, ha ezek közül egy vagy több interfész ad default implementációt? Java 8 esetén az osztálynak ez esetben is implementálnia kell a metódust, különben fordítási hibát kapunk. Ha viszont öröklődésen keresztül az osztályban a metódusnak ugyanaz az egy default implementációja jelenik meg örököltként, akkor nincs gond. Tehát ha az A interfész implementálja a durvasag()-ot, majd a B és C interfészek kiterjesztik az A-t és a D osztály implementálja B-t és C-t, akkor örökli a durvasag() implementációját is. Tehát egy osztály pontosan egy default implementációt tud örökölni akár több leszármazási úton keresztül is de csak akkor ha ugyanezt a metódust nem örökli absztraktként is. Természetesen ha az osztálynak implementálnia kell a metódust, akkor az történhet magában az osztályban, de örökölheti az implementációt kiterjesztett osztályból is.
Mi van azonban abban az esetben, ha a programunk korábban lefordult olyan interfész verziókkal, amik még nem okoztak gondot a fordítónak, majd az interfészből kijön egy új verzió amivel már nem fordulna le? Nos a lefordított verzió valószínűleg továbbra is futni fog, de a Java 8 nem túl egyértelmű ebben az esetben.
Tekintsük a következő példát:
Ebben az esetben az osztály futni fog, bár a kód már nem fog újra lefordulni. Íme egy példán keresztül:
InterA.java
package hu.egalizer.java8.mess; public interface InterA { }
InterB.java
package hu.egalizer.java8.mess; public interface InterB { default public void durvasag() { System.out.println("Durva dolgok mennek."); } }
InterABImpl.java
package hu.egalizer.java8.mess; public class InterABImpl implements InterA, InterB { public void goTrabi() { durvasag(); } public static void main(String[] args) { new InterABImpl().goTrabi(); } }
Fordítsuk le és futtassuk a kódot:
javac.exe hu/egalizer/java8/mess/*.java java.exe hu.egalizer.java8.mess.InterABImpl Durva dolgok mennek.
Ezután módosítsuk az InterA.java-t:
InterA.java
package hu.egalizer.java8.mess; public interface InterA { public void durvasag(); }
Fordítsuk le majd futtassuk a kódot:
javac.exe hu/egalizer/java8/mess/InterA.java java.exe hu.egalizer.java8.mess.InterABImpl Durva dolgok mennek.
A dolgok működnek, pedig az InterABImpl-ből még az előző lefordított verziót futtattuk. Próbáljuk most lefordítani újra, és így járunk:
javac.exe hu/egalizer/java8/mess/InterABImpl.java
hu\egalizer\java8\mess\InterABImpl.java:3: error: InterABImpl is not abstract and does not override abstract method durvasag() in InterA
public class InterABImpl implements InterA, InterB {
^
1 error
Most pedig
InterA.java
package hu.egalizer.java8.mess; public interface InterA { default public void durvasag() { System.out.println("Ütközni fogunk!"); } }
javac.exe hu/egalizer/java8/mess/InterA.java
java.exe hu.egalizer.java8.mess.InterABImpl
Exception in thread "main" java.lang.IncompatibleClassChangeError: Conflicting default methods: hu/egalizer/java8/mess/InterA.durvasag hu/egalizer/java8/mess/InterB.durvasag
at hu.egalizer.java8.mess.InterABImpl.durvasag(InterABImpl.java)
at hu.egalizer.java8.mess.InterABImpl.goTrabi(InterABImpl.java:6)
at hu.egalizer.java8.mess.InterABImpl.main(InterABImpl.java:10)
Ha két olyan interfész is van az öröklődési láncban, amelyik default implementációt ad egy metódusra, akkor az implementáló osztályban nem lehet meghívni a metódust, ha az nincs definiálva expliciten az osztályban vagy egy ősosztályban. A lefordított .class továbbra is használható és futni fog egészen addig, míg nem történik hívás arra a metódusra, amelyet többszörösen definiálnak az interfészek.
Láttuk, hogyan jönnek létre a lambda kifejezésekkel anonim metódusok. Néha azonban egy lambda kifejezés semmit nem csinál, csak meghív egy másik, már létező metódust. Ilyenkor egyszerűbb lenne a létező metódusra lambda nélkül csak névvel hivatkozni. A metódus referenciák pont ezt teszik lehetővé: java osztályok vagy objektumok létező metódusaira vagy konstruktoraira közvetlenül hivatkozó eszközök. Tegyük fel hogy legót gyűjtünk és készítünk egy legónyilvántartó programot. Egy legókészletet az alábbi osztály reprezentál:
package hu.egalizer.java8.lego; import java.time.LocalDate; public class LegoSet { private int yearReleased;// megjelenés éve private String name;// név private int pieceCount;// elemek száma private LocalDate addedToCollection;// gyűjteménybe kerülés dátuma public static int compareByAdded(LegoSet a, LegoSet b) { return a.addedToCollection.compareTo(b.addedToCollection); } public LocalDate getAddedToCollection() { return addedToCollection; } public void setAddedToCollection(LocalDate addedToCollection) { this.addedToCollection = addedToCollection; } public int getYearReleased() { return yearReleased; } public void setYearReleased(int yearReleased) { this.yearReleased = yearReleased; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getPieceCount() { return pieceCount; } public void setPieceCount(int pieceCount) { this.pieceCount = pieceCount; } }
Tegyük fel, hogy a legó nyilvántartó alkalmazásunk a készleteket egy tömbben tárolja és azt a tömböt a készlet hozzáadásának dátuma szerint akarjuk rendezni. Eljárhatunk így:
public class LegoDatabase { private List<LegoSet> mySets; public LegoSet[] orderSets() { LegoSet[] setsAsArray = mySets.toArray(new LegoSet[mySets.size()]); Arrays.sort(setsAsArray, new LegoAddedComparator()); return setsAsArray; } class LegoAddedComparator implements Comparator<LegoSet> { @Override public int compare(LegoSet a, LegoSet b) { return a.getAddedToCollection().compareTo(b.getAddedToCollection()); } } }
A fenti sort metódus aláírása:
static <T> void sort(T[] a, Comparator<? super T> c)
Vegyük észre, hogy a Comparator egy funkcionális interfész! Erről már tudjuk, hogy lambda kifejezésekkel szépen lehet használni, nem kell föltétlenül létrehozni egy Comparator-t implementáló osztályból új példányt. Tehát:
Arrays.sort(setsAsArray, (a, b) -> a.getAddedToCollection().compareTo(b.getAddedToCollection()));
A készlet gyűjteménybe való bekerülésének dátumára ugyanakkor már a LegoSet is tartalmaz egy statikus metódust: LegoSet.compareByAdded. Ezt is meghívhatjuk a lambda kifejezés törzsében:
Arrays.sort(setsAsArray, (a, b) -> LegoSet.compareByAdded(a, b));
Ez a lambda kifejezés csupán egy létező metódust hív meg, itt jön be a metódus referencia, amit ez esetben használhatunk a lambda helyett (a metódusreferenciát a dupla kettőspont hivatkozza az osztálynév és a metódus között):
Arrays.sort(setsAsArray, LegoSet::compareByAdded);
A LegoSet::compareByAdded metódusreferencia szemantikusan ugyanaz, mint a (a, b) -> LegoSet.compareByAdded(a, b) lambda kifejezés. Mindkettő a következőképpen viselkedik:
Gondolom most már mindenki a körmét rágja abbéli izgalmában, hogy milyen metódusreferenciák vannak pontosan. Nem kell tovább várni, a titokra fény derül: négyféle metódusreferencia létezik:
| Típus | Formátum |
|---|---|
| referencia statikus metódusra | TartalmazoOsztaly::statikusMetodusNeve |
| referencia objektum példánymetódusára | tartalmazoObjektum::peldanyMetodusNeve |
| referencia tetszőleges objektum adott típusának példánymetódusára | TartalmazoTipus::metodusNeve |
| referencia konstruktorra | OsztalyNeve::new |
A nyájas olvasó természetesen nem ússza meg példák nélkül:
Referencia statikus metódusra: a LegoSet::compareByAdded referencia egy statikus metódusra
Referencia objektum példánymetódusára: az alábbi példa rávilágít:
package hu.egalizer.java8.lego; public class ComparisonProvider { public int compareByName(LegoSet a, LegoSet b) { return a.getName().compareTo(b.getName()); } public int compareByAdded(LegoSet a, LegoSet b) { return a.getAddedToCollection().compareTo(b.getAddedToCollection()); } }
ComparisonProvider myComparisonProvider = new ComparisonProvider();
Arrays.sort(setsAsArray, myComparisonProvider::compareByName);
A példában a myComparisonProvider::compareByName metódusreferencia a myComparisonProvider objektum compareByName metódusát hívja meg. A JRE kikövetkezteti a metódus paramétertípusait, ami (LegoSet, LegoSet).
Referencia tetszőleges objektum adott típusának példánymetódusára: egy példa többet mond ezer szónál:
String[] stringArray = { "Misi", "Joci", "Robert", "Pisti", "Morgan", "Viktor", "Zoli" };
Arrays.sort(stringArray, String::compareToIgnoreCase);
A String::compareToIgnoreCase metódusreferenciának megfelelő lambda kifejezés a (String a, String b) formális paraméterlistával rendelkezne (a és b hasraütéses változónevek). Ez a metódusreferencia az a.compareToIgnoreCase(b) hívást eredményezi.
Referencia konstruktorra: Ugyanúgy lehet konstruktorra referenciát létrehozni, mint statikus metódusra, csak a new kulcsszót kell használni. Az alábbi példa elemeket másol egyik kollekcióból egy másikba:
public static <T, SOURCE extends Collection<T>, DEST extends Collection<T>> DEST transferElements(SOURCE sourceCollection, Supplier<DEST> collectionFactory) { DEST result = collectionFactory.get(); for (T t : sourceCollection) { result.add(t); } return result; }
A Supplier funkcionális interfész egy get metódust tartalmaz, ami nem kap paramétert és visszaad egy objektumot. Ezért meg lehet hívni a transferElements metódust lambda kifejezéssel is így:
Set<LegoSet> setsLambda = transferElements(mySets, () -> {
return new HashSet<>();
});
A lambda helyett pedig lehet használni konstruktor referenciát is a következőképpen:
Set<LegoSet> setsSet = transferElements(mySets, HashSet::new);
A Java fordító kikövetkezteti, hogy egy HashSet-et akarunk létrehozni ami LegoSet típusú elemeket tartalmaz. Más módon így is meg lehet egyébként ugyanezt adni:
Set<LegoSet> setsSet = transferElements(mySets, HashSet<LegoSet>::new);
Szivárgó metódusreferenciák
A Java-ban a metódusreferenciáknak van egy érdekes (vagy inkább bosszantó) tulajdonságuk amit nem árt észben tartani, nehogy kellemetlen meglepetés érje az embert. Ez röviden így fogalmazható meg:
obj::method != obj::method
Kétszer meghatározott metódus referencia nem fog megegyezni! A többi gyakran használt programnyelvben a metódus referenciák általában nem ilyenek, de a Java kivétel. A szomorú helyzetet bizonyára a Java tervezői is látták, ezért a metódus referenciákat nem lehet közvetlenül összehasonlítani. De közvetetten már igen:
String s = "galiba"; Supplier<Integer> sup1 = s::length; Supplier<Integer> sup2 = s::length; System.out.println(sup1 == sup2);// false // System.out.println(s::length == s::length); - nem fordul le
Miért jelenthet ez problémát?
Tegyük fel hogy van egy osztályunk, ami sorba állított feladatokat futtat adott idő elteltével. Ebbe egy add metódussal tudjuk betenni a Runnable feladatokat, remove metódussal pedig kiszedni belőle őket.
public interface RunnableQueue { /** * Betesz egy Runnable osztályt a sorba, ami a megadott idő elteltével fog lefutni. */ boolean add(Runnable r, long delayMillis); /** * Eltávolít a várakozó Runnable osztályt a sorból. */ void remove(Runnable r); }
A probléma abból adódik, hogy minden alkalommal amikor leírom a this::doSomething kifejezést, a Java új példányt hoz létre egy anonim osztályból, vagyis a this::doSomething != this::doSomething, még ha ezt Java-ban nem is lehet így leírni. Ezért aztán például a várakozó Runnable-ök sosem lesznek kivéve a sorból, a végén pedig memóriaszivárgás lesz. Ez a problémakör tulajdonképpen a Java 8 egyik tervezési hibájának is tekinthető. Bár a this::doSomething ártatlan referenciának tűnik egy metódusra, valójában a Runnable egy új példányát hozza létre, ráadásul a Runnable egy referenciát tartalmaz az őt befoglaló objektumra is! A megoldás persze egyszerű: meg kell tartani egy referenciát a létrehozott Runnable-höz és így ugyanazt a referenciát tudjuk átadni a remove-nak. De így ezt már mindig észben kell tartani és nem írhatjuk önkéntelenül azt ami eszünkbe jutna. A történet tanulsága: a metódusreferenciák helyett gyakran érdemesebb inkább lambdákat használni. (Vagy ha nem, akkor legyünk mindig tisztában azzal, hogy mi történik.) A metódusreferenciák használata mellett szól viszont az a tény, hogy ezekből csak egy invokevirtual hívást fog a fordító csinálni, míg a lambdákból minden esetben készül a fent már említett láthatatlan privát "lambda$0" metódus.
Miután a Java 5 bevezette az annotációk támogatását, ez a nyelvi tulajdonság nagyon népszerű és széles körben használatos lett. Volt viszont ezen annotációk használhatóságának egy korlátozása is: ugyanazt az annotációt nem lehetett egynél többször használni ugyanazon a helyen. A Java 8 megszünteti ezt és bevezeti az ismétlő annotációkat. Ezzel lehetővé válik, hogy ugyanazt az annotációt a deklaráció helyén többször is kiadjuk.
Tegyük fel, hogy egy időzítő szolgáltatást használó olyan kódot írunk. Az időzítő lehetővé teszi, hogy egy metódus adott időpontban vagy pedig valamilyen időzítéssel fusson. Mondjuk szeretnénk, hogy az induljonABanzaj metódus minden hónap utolsó napján és minden pénteken este 11-kor fusson. Az időzítő beállításához egy @Schedule annotáció tartozik és a feladathoz kétszer kell az induljonABanzaj metódushoz alkalmazni. Ez Java 8 esetén semmilyen problémát nem okoz. Az első használat a hónap utolsó napját adja meg, a második pedig a péntek 11-et:
@Schedule(dayOfMonth="last") @Schedule(dayOfWeek="Fri", hour="23") public void induljonABanzaj() { ... }
Annotációkat bárhol lehet többszörözni ahol normál annotációkat egyébként is írhatunk.
Ismétlő annotációk létrehozása
Kompatibilitási okokból az ismétlő annotációk egy konténer annotációban tárolódnak, amit a Java fordító automatikusan legenerál. De ahhoz, hogy ezt meg tudja tenni, a kódban két deklaráció szükséges hozzá. (Ez a tulajdonság egyébként valójában nem is igazán nyelvi módosítás, hanem csak egy fordítóprogram-szintű trükk, hiszen a technológia ugyanaz maradt.)
A ismétlő annotációk meg kell jelöljék magukat a @Repeatable annotációval (különben a kutya se hiszi el róluk, hogy tényleg ismétlőek). Nézzünk egy példát:
package hu.egalizer.java8; import java.lang.annotation.Repeatable; @Repeatable(Schedules.class) public @interface Schedule { String dayOfMonth() default "first"; String dayOfWeek() default "Mon"; int hour() default 12; }
A @Repeatable meta-annotációnak a zárójelek között megadott érték annak a konténer annotációnak a típusa, amit majd a Java fordító arra fog használni, hogy az ismétlődő annotációkat abban tárolja. Ebben a példában a tartalmazó annotáció típusa Schedules, tehát az ismétlődő @Schedule annotációk egy @Schedules annotációban fognak tárolódni. Ha egy annotációt anélkül próbálunk többször megadni egy deklarációhoz, hogy elsőként ismétlődőként deklarálnánk, rövid úton fordítási hibához fog vezetni. Azt pedig senki se szereti.
A tartalmazó annotációban egy tömb típusú value mezőnek kell lenni. A tömb típus komponens típusának az ismétlődő annotáció típusúnak kell lennie. A Schedules tartalmazó annotáció típus deklarációja a következőképp néz ki:
public @interface Schedules { Schedule[] value(); }
A Java 8 bővíti az anotációk használatának lehetőségeit: most már szinte bármit annotálhatunk, amire csak gusztusunk támad: lokális változókat, generikus típusokat, ősosztályokat és implementáló interfészeket, sőt még egy metódus kivétel deklarációját is. Néhány példa:
package hu.egalizer.java8.anno; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; import java.util.ArrayList; import java.util.Collection; public class SokSokAnnotacio { @Retention(RetentionPolicy.RUNTIME) @Target({ ElementType.TYPE_USE, ElementType.TYPE_PARAMETER }) public @interface NonEmpty { } public static class Holder<@NonEmpty T> extends @NonEmpty Object { public void method() throws @NonEmpty Exception { } } @SuppressWarnings("unused") public static void main(String[] args) { final Holder<String> holder = new @NonEmpty Holder<String>(); @NonEmpty Collection<@NonEmpty String> strings = new ArrayList<>(); } }
Az annotáció definíciójában a @Target metaannotáció segítségével lehet megadni azt a kontextust ahol az annotációt használni lehet majd. A Java 8-ban két új típus jelent meg:
Természetesen az annotációfeldolgozó API-ba is bevezették ezen típusú annotációk kezelését.
Annotációk megszerzése
Amint azt bizonyára mindenki tudja, az annotációk bekerülhetnek egy osztály vagy interfész bináris reprezentációjába is (egyszerűbben szólva: a .class fájlba). Ha pedig mág bekerülnek akkor elérhetőek (vagy nem) futásidőben is reflection segítségével. Az annotációk definícióját a @Retention metaannotációval meg lehet jelölni és ezen belül a RetentionPolicy enum konstansaival lehet megadni, hogy az adott annotáció meddig legyen megtartva:
A fentiektől függetlenül a helyi változókra vonatkozó annotációkat a fordító mindig eldobja akármit csinálunk is. A .class fájlokba többek között az annotációra vonatkozó információk is ún. attribútumok formájában kerülnek be. Ezekről most elég itt annyit tudni, hogy hatféle van belőlük:
A RuntimeVisibleTypeAnnotations és RuntimeInvisibleTypeAnnotations attribútumok Java 8 esetén újdonságként kerültek a .class fájl definíciójába.
A reflecion API-ban több metódus található arra nézvést, hogy futásidőben is elérhető annotációkat megszerezzünk. Az AnnotatedElement interfész ki lett bővítve az ismétlő annotációk bevezetése miatt. (Ezt az interfészt implementálják a reflection API azon elemei amelyekhez lehet annotációt társítani, mint például a Method, Class, Constructor, Field, stb.) Azon metódusok működése, amelyek egy annotációt adnak vissza, mint például az AnnotatedElement.getAnnotation(Class<T>) változatlan maradt, de egy megszorítással: továbbra is mindig csak egy annotációt adnak vissza, tehát ismétlő annotáció esetén nem az ismétlő annotációt, hanem annak konténerét kell lekérdeznünk (akkor is ha csak egy van belőle). Így lehetett elérni a visszamenőleges kompatibilitást. A Java 8-ban három további metódus került az interfészbe a meglévő négy mellé, kettő ezekből már az ismétlő annotációkat is visszaadja. Ha a paraméter ismétlő annotáció, akkor a getAnnotationsByType(Class<T>) és a getDeclaredAnnotationsByType(Class<T>) metódus végigmegy a konténer annotációkon, ha van olyan és visszaadja a konténerek tartalmát is.
A Java 8 az AnnotatedElement használatához bevezette a directly present, indirectly present, present és associated fogalmakat. Ezek pontosan meghatározzák, mely annotációt mely metódus ad vissza. Vigyázat, definíció következik!
(Vegyük észre, hogy - az öröklődés miatt - a present és az associated rekurzív definíció.)
Az alábbi táblázat megmutatja hogy mely típusú annotáció jelenlétet mely metódussal lehet megvizsgálni. Bár ez a hivtalos Oracle dokumentációból származik, a valóságban a definíciók egymásba ágyazottsága miatt a present típusú annotációkat visszaadó metódus nyilvánvalóan a directly present típust is vissza fogja adni.
| Metódus | Típus | |||
|---|---|---|---|---|
| Directly present | Indirectly present | Present | Associated | |
| T getAnnotation(Class<T>) | X | |||
| Annotation[] getAnnotations() | X | |||
| T[] getAnnotationsByType(Class<T>) | X | |||
| T getDeclaredAnnotation(Class<T>) | X | |||
| Annotation[] getDeclaredAnnotations() | X | |||
| T[] getDeclaredAnnotationsByType(Class<T>) | X | X | ||
Egy getAnnotationsByType(Class<T>) vagy getDeclaredAnnotationsByType(Class<T>) meghívása esetén az E elemen lévő directly vagy indirectly present típusú annotációk sorrendje úgy számolódik mintha az E-n lévő indirectly present annotációk is directly present lennének az E-n (a konténer annotáció helyett) és abban a sorrendben ahogyan a konténer annotáció value mezőjében megjelennek.
Az alábbi példa bemutatja a különböző típusokat és lekérdezéseket:
AnnotationRootAncestor.java
package hu.egalizer.java8.anno; import java.lang.annotation.ElementType; import java.lang.annotation.Inherited; import java.lang.annotation.Repeatable; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; import hu.egalizer.java8.anno.AnnotationRootAncestor.SimpleAnni; @SimpleAnni public class AnnotationRootAncestor { @Inherited @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) public @interface Books { Book[] value(); } @Inherited @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Repeatable(Books.class) public @interface Book { String value(); }; @Inherited @Retention(RetentionPolicy.RUNTIME) public @interface SimpleAnni { }; }
AnnotationPresenceAncestor.java
package hu.egalizer.java8.anno; import hu.egalizer.java8.anno.AnnotationRootAncestor.Book; @Book("Java 8 for dummies") @Book("C# for experts") public class AnnotationPresenceAncestor extends AnnotationRootAncestor { }
AnnotationPresence.java
package hu.egalizer.java8.anno; import java.lang.annotation.Annotation; import java.lang.reflect.AnnotatedElement; public class AnnotationPresence extends AnnotationPresenceAncestor { @Book("Memories") @Book("War and peace") public interface Bookshelf { } @SimpleAnni public void anniTest() { System.out.println("Hahó"); } public static void main(String[] args) throws NoSuchMethodException, SecurityException { System.out.println("----------- Directly present:"); annotatedMethods(AnnotationPresence.class.getMethod("anniTest"), SimpleAnni.class); System.out.println("----------- Indirectly present:"); annotatedMethods(Bookshelf.class, Book.class); System.out.println("----------- Present:"); annotatedMethods(AnnotationPresence.class, SimpleAnni.class); System.out.println("----------- Associated:"); annotatedMethods(AnnotationPresence.class, Book.class); } public static void annotatedMethods(AnnotatedElement element, Class<? extends Annotation> annotation) { printAnnotation("getAnnotation(Class<T>)", element.getAnnotation(annotation)); printAnnotation("getAnnotations()", element.getAnnotations()); printAnnotation("getAnnotationsByType(Class<T>)", element.getAnnotationsByType(annotation)); printAnnotation("getDeclaredAnnotation(Class<T>)", element.getDeclaredAnnotation(annotation)); printAnnotation("getDeclaredAnnotations()", element.getDeclaredAnnotations()); printAnnotation("getDeclaredAnnotationsByType(Class<T>)", element.getDeclaredAnnotationsByType(annotation)); } public static void printAnnotation(String methodName, Annotation anno) { System.out.print(methodName + " invocation "); if (anno != null) { System.out.println("found annotation type " + anno.toString()); } else { System.out.println("found nothing!"); } } public static void printAnnotation(String methodName, Annotation[] annoArray) { System.out.print(methodName + " invocation "); if (annoArray.length > 0) { StringBuilder sb = new StringBuilder("found annotation types: "); for (Annotation an : annoArray) { sb.append(an.toString()); sb.append(", "); } System.out.println(sb.toString()); } else { System.out.println("found nothing!"); } } }
A program kimenetele:
----------- Directly present: getAnnotation(Class<T>) invocation found annotation type @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni() getAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), getAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), getDeclaredAnnotation(Class<T>) invocation found annotation type @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni() getDeclaredAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), getDeclaredAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), ----------- Indirectly present: getAnnotation(Class<T>) invocation found nothing! getAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$Books(value=[@hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Memories), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=War and peace)]), getAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Memories), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=War and peace), getDeclaredAnnotation(Class<T>) invocation found nothing! getDeclaredAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$Books(value=[@hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Memories), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=War and peace)]), getDeclaredAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Memories), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=War and peace), ----------- Present: getAnnotation(Class<T>) invocation found annotation type @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni() getAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), @hu.egalizer.java8.anno.AnnotationRootAncestor$Books(value=[@hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Java 8 for dummies), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=C# for experts)]), getAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), getDeclaredAnnotation(Class<T>) invocation found nothing! getDeclaredAnnotations() invocation found nothing! getDeclaredAnnotationsByType(Class<T>) invocation found nothing! ----------- Associated: getAnnotation(Class<T>) invocation found nothing! getAnnotations() invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$SimpleAnni(), @hu.egalizer.java8.anno.AnnotationRootAncestor$Books(value=[@hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Java 8 for dummies), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=C# for experts)]), getAnnotationsByType(Class<T>) invocation found annotation types: @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=Java 8 for dummies), @hu.egalizer.java8.anno.AnnotationRootAncestor$Book(value=C# for experts), getDeclaredAnnotation(Class<T>) invocation found nothing! getDeclaredAnnotations() invocation found nothing! getDeclaredAnnotationsByType(Class<T>) invocation found nothing!
Olyan helyzet is előfordulhat amikor egy korábban nem ismétlő annotációból egyszer csak ismétlőt csinálunk. Ilyenkor kompatibilitási kérdések merülnek fel, amikre a Java 8 tervezői az alábbi válaszokat adták. (A leírásban T az annotáció, TC pedig annak a konténerannotációja.)
Az első pontban van egy érdekes kitétel ami talán másoknak is szemet szúrt. A TC már azelőtt konténerként tud viselkedni, hogy a T-ből ismétlőt csinálnánk? Nézzük a következő példát:
Oldanno.java
package hu.egalizer.java8.anno.kompa; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.ElementType.METHOD; import static java.lang.annotation.ElementType.TYPE; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Retention; import java.lang.annotation.Target; @Retention(RUNTIME) @Target({ TYPE, FIELD, METHOD }) public @interface Oldanno { String magic(); }
OldannoContainer.java
package hu.egalizer.java8.anno.kompa; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.ElementType.METHOD; import static java.lang.annotation.ElementType.TYPE; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Retention; import java.lang.annotation.Target; @Retention(RUNTIME) @Target({ TYPE, FIELD, METHOD }) public @interface OldannoContainer { }
Test1.java
package hu.egalizer.java8.anno.kompa; public class Test1 { @Oldanno(magic = "Magic Method") public static void statikus1() { System.out.println("irgum"); } @OldannoContainer public static void statikus2() { System.out.println("burgum"); } public static void main(String[] args) throws NoSuchMethodException, SecurityException { System.out.println("Annotációk lekérdezése"); System.out.println(Test1.class.getMethod("statikus1").getAnnotation(Oldanno.class).magic()); System.out.println(Test1.class.getMethod("statikus2").getAnnotation(OldannoContainer.class)); System.out.println("Metódushívás"); statikus1(); statikus2(); } }
Fordítsuk le a három osztályt:
javac.exe hu\egalizer\java8\anno\kompa\*.java
Ha elindítjuk a Test1-et akkor szépen le fog futni. Ezután módosítsuk az Oldanno annotációt ismétlőre. Ahhoz, hogy leforduljon csinálni kell neki konténert is, ez lesz az OldannoContainer, ezt is és a forrást is módosítani kell ennek megfelelően. Ezután fordítsuk le csak az Oldanno.java-t!
Oldanno.java
package hu.egalizer.java8.anno.kompa; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.ElementType.METHOD; import static java.lang.annotation.ElementType.TYPE; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Retention; import java.lang.annotation.Target; @Retention(RUNTIME) @Target({ TYPE, FIELD, METHOD }) @Repeatable(OldannoContainer.class) public @interface Oldanno { String magic(); }
OldannoContainer.java
package hu.egalizer.java8.anno.kompa; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.ElementType.METHOD; import static java.lang.annotation.ElementType.TYPE; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Retention; import java.lang.annotation.Target; @Retention(RUNTIME) @Target({ TYPE, FIELD, METHOD }) public @interface OldannoContainer { Oldanno[] value(); }
Test1.java
package hu.egalizer.java8.anno.kompa; public class Test1 { @Oldanno(magic = "Magic Method") public static void statikus1() { System.out.println("irgum"); } @OldannoContainer(value = {}) public static void statikus2() { System.out.println("burgum"); } public static void main(String[] args) throws NoSuchMethodException, SecurityException { System.out.println("Annotációk lekérdezése"); System.out.println(Test1.class.getMethod("statikus1").getAnnotation(Oldanno.class).magic()); System.out.println(Test1.class.getMethod("statikus2").getAnnotation(OldannoContainer.class)); System.out.println("Metódushívás"); statikus1(); statikus2(); } }
javac.exe hu\egalizer\java8\anno\kompa\Oldanno.java
Látni fogjuk, hogy a Test1 továbbra is ugyanúgy fut ezután is, pedig azt a régi Oldanno annotációval fordítottuk. Vagyis a korábban lefutott OldannoContainer már azelőtt konténerként tud viselkedni, hogy az Oldanno-ból ismétlőt csinálnánk.
A Java 8 fordítója sokat fejlődött a típusok kezelése tekintetében. A típus paramétereket sok esetben ki tudja következtetni, így a kód tisztább lehet. Tekintsük az alábbi két osztályt!
package hu.egalizer.java8; public class GenericValue<T> { public static <T> T defaultValue() { return null; } public T getOrDefault(T value, T defaultValue) { return (value != null) ? value : defaultValue; } }
public class GenericTest { public static void main(String[] args) { final GenericValue<String> value = new GenericValue<>(); value.getOrDefault("Próba", GenericValue.defaultValue()); } }
A Value.defaultValue() típus paramétere ki lesz következtetve és nem szükséges expliciten megadni. Java 7-ben a fenti példa nem fordulna le csak ha átírnánk Value.<String>defaultValue() formára.
Régóta próbáltak már kerülőmódszereket találni arra, hogy a metódus paraméter nevek bekerüljenek a bájtkódba és elérhetőek legyenek futásidőben. A Java 8 ezt a problémát is megoldja. A javac kapott kapott egy -parameters kapcsolót amivel elérhetjük, hogy a nevek bekerüljenek a .class fájlba, a reflection API-ban pedig megjelent a Parameter.getName() metódus amivel lekérdezhetjük futásidőben. (Természetesen a paramétereket a fájlméret és az osztály futásidejű memóriafoglalásának kárára tarthatjuk meg.) A reflection-ön keresztül a Parameter.isNamePresent() metódussal azt is ellenőrizni lehet, hogy ez a kapcsoló fordításkor meg volt-e adva. (A JDK-t enélkül fordították, tehát a gyári API-kban a paraméterneveket hiába keressük.)
A híres NullPointerException magasan a legnépszerűbb kivétel a Java nyelvben. Népszerűsége abban áll, hogy a programozók szeretnének vele minél kevesebbet találkozni. Ezért aztán folyamatosan nullvizsgálatokat kénytelenek írni a kódba. A Google Guava projekt a NullPointerException elkerülésére már réges-régen (egy messzi-messzi galaxisban) bevezette az Optional nevű megoldását. Ez lecsökkenti a null ellenőrzések kódot teleszemetelő hatását és lehetővé teszi tisztább kód írását. A Guava-ból inspirálva az Optional immár a Java 8 osztálykönyvtárnak is része.
Az Optional valójában csak egy (generikus) konténer. Bármilyen T típusú értéket vagy null-t tud tárolni. Számos hasznos metódusa van, így az explicit nullvizsgálat már nem föltétlenül szükséges többé.
Optional létrehozása
Üres, null-t tartalmazó Optional létrehozása:
Optional<T> str = Optional.empty();
Az empty szó egyébként kicsit megtévesztő, hiszen általában az üres sztringeket is ("") empty-nek hívják, sok osztálykönyvtárnak van isEmpty() vagy hasonló metódusa az üres sztringek vizsgálatára. Ha viszont egy üres sztringet egy Optional objektumba teszünk, akkor az Optional nem lesz "empty". (Régi magyar programozás szakkönyvek egyébként a sztringeket előszeretettel nevezték "füzér"-nek. Szép szó, de én mégis inkább maradok a sztringnél.)
Az ofNullable() metódussal olyan Optional-t hozhatunk létre ami a paraméterétől függően lehet üres vagy tartalmazhat null-tól eltérő értéket:
String s = ... //az s korábban kaphatott értéket de lehet null is
Optional<String> name = Optional.ofNullable(s);
Az of() gyártófüggvény ezzel szemben mindenképpen nem null paramétert vár, különben NullPointerException-t dob!
Optional<String> name = Optional.of("Jancsi");
Az Optional használata
Ha van Optional példányunk akkor a metódusain keresztül közvetlenül tudjuk kezelni érték jelenlétét vagy hiányát. Tekintsük a következő példát:
LocalDate date = LocalDate.now(); if (date != null) { System.out.println(date); }
Az Optional esetén a fenti feltételvizsgálatot az ifPresent() metódussal már így is írhatjuk:
Optional<LocalDate> date = Optional.of(LocalDate.now()); date.ifPresent(System.out::println);
Ebben a formában nem kell explicit nullvizsgálat. Ha az Optional üres lenne, akkor semmi nem íródna ki. Az isPresent() metódussal viszont megvizsgálhatjuk, hogy van-e az Optional objektumpéldányunkban érték. Sőt, van egy get() metódus is, ami vissza is adja azt (ha nincs, akkor meg NoSuchElementException kivételt dob). Ezzel a két metódussal újra behozhatjuk az ifet ha nagyon hiányozna, bár ez a fajta használat kerülendő, mert nem használja ki az Optional előnyeit:
if (date.isPresent()) { System.out.println(date.get()); }
Ha viszont jobban megnézzük a fenti kódot, akkor egyből felmerül a kérdés, hogy és mi van, ha az Optional<LocalDate> típusú date lesz null? Ezt semmi sem tiltja és akkor innentől kezdve egyáltalán nem száműztük a NullPointerException-t, sőt! Nos az Optional sem tökéletes megoldás, a hátrányairól később még lesz szó.
Alapértelmezett értékek
Tipikus programozási eset például hogy adjunk vissza valami alapértelmezett értéket ha azt tapasztaljuk hogy egy művelet eredménye null. Használhatjuk ilyenkor a háromoperandusú operátort is:
LocalDate datum = bizonytalanDatum != null ? bizonytalanDatum : LocalDate.now();
Az Optional orElse() metódusa visszaad egy alapértelmezett értéket ha az Optional null-t tartalmaz. Ezzel a fenti esetet így is átírhatjuk:
Optional<LocalDate> bizonytalanDatum = ... //nem tudjuk, mi történt
LocalDate datum = bizonytalanDatum.orElse(LocalDate.now());
Az orElseGet() majdnem ugyanezt csinálja, csak az alapértelmezett értéket ott egy Supplier funkcionális interfész állítja elő, például:
LocalDate datum = bizonytalanDatum.orElseGet(LocalDate::now);
Az orElseThrow() metódus pedig nem foglalkozik alapértelmezett értékkel; ha az Optional üres, akkor a megadott kivételt dobja:
LocalDate datum = bizonytalanDatum.orElseThrow(IllegalStateException::new);
Műveletek
Gyakran szükség van egy objektumon valamilyen mezőt metódushívással ellenőrizni. Például megnézzük, hogy a dátum újév napja-e:
LocalDate date = ... if (date != null && date.getDayOfYear() == 1) { System.out.println("Újév!"); }
Ezt az Optional filter() metódusával a következőképpen lehet megtenni:
lehetsegesDatum.filter(date -> date.getDayOfYear() == 1)
.ifPresent(date -> System.out.println("Újév!"));
A filter metódus egy Predicate funkcionális interfészt vár. Ha az Optional tartalmaz valamilyen értéket és az megfelel a predikátumnak, akkor a visszaadott új Optional objektumpéldány azt az értéket tartalmazza, egyébként pedig üres lesz (hasonló megoldást fogunk látni majd a Stream API-ban is).
Nézzük most egy összetettebb példát! Tegyük fel, hogy van egy internetes boltunk, ahol minden rendeléshez (Order) tartozhat egy szállítási cím (Address), amin van egy flag, ami megmondja, hogy egyben ez-e a számlázási cím is (billingAddress). Cím (és számla) viszont nem kötelező, ha személyes átvételt választ a vásárló. Hogyan vizsgáljuk meg hogy a számlázási cím megegyezik-e a szállítási címmel?
if (order != null) { Address address = order.getAddress(); if (address != null && address.isBillingAddress()) { System.out.println("Számlázási cím!"); } }
Az Address lekérdezését át tudjuk írni az Optional map metódusának használatával így:
Optional<Order> possibleOrder = ... Optional<Address> address = possibleOrder.map(Order::getAddress);
Az Optional objektumban tárolt érték egy új Optional objektummá "alakul" a paraméterként átadott függvény használatával (itt egy metódusreferenciával, ami lekérdezi az address-t). A map() tehát megváltoztat(hat)ja az eredeti Optional generikus típusát is. Ha az Optional üres, akkor egy üres Optional a map visszatérési értéke is. Kombinálni is tudjuk a map-et a filter metódussal, hogy csak olyan címeket fogadjunk el ahol a cím egyben a számlázási cím is:
possibleOrder.map(Order::getAddress)
.filter(address -> address.isBillingAddress())
.ifPresent(address -> System.out.println("Mehet!"));
A map többszörösen egymásba ágyazott adatszerkezetek esetén is hasznos. Tegyük fel, hogy az Address objektumon van egy címzett (Recipient) és annak egy keresztneve (firstName). Hogyan kérdezzük ezt le szokványos megoldással?
String name = order.getAddress().getRecipient().getFirstName();
Mi a helyzet, ha el szeretnénk kerülni a NullPointerException kivételeket (mondjuk lehet bolti átvétel, ilyenkor nincs cím, stb.)?
String name = ""; if (order != null) { Address address = order.getAddress(); if (address != null) { Name recipient = address.getRecipient(); if (recipient.getFirstName() != null) { name = recipient.getFirstName(); } } }
A lusta kiértékelést kihasználva ezt persze egyetlen ifbe is meg lehet írni, de így most szemléletesebb. Viszont ha megnézzük az eredeti egysoros kifejezést, akkor azt látjuk, hogy a kód csupán egy objektumot kivesz egy másikból és pont erre való a map metódus is. Az Optional használatával alakítsuk át az osztályokat így (a Name marad változatlan):
public class Order { private Optional<Address> address; public Optional<Address> getAddress() { return address; } ... } public class Address { private Optional<Name> recipient; private boolean billingAddress; public Optional<Name> getRecipient() { return recipient; } ... } public class Name { private String firstName; public String getFirstName() { return firstName; } ... }
A fenti adatszerkezet így már mutatja, hogy egy adott érték akár hiányozhat is (opcionális), bár csak a példa kedvéért készült, mezők típusának nem ajánlatos Optional típust adni. Az Optional fentebb bemutatott metódusaival pedig közvetlenül kezelhetjük az érték hiányzó vagy meglévő eseteit. A null referenciákhoz képesti előny, hogy az Optional kikényszeríti, hogy elgondolkodjunk rajta, mi van akkor amikor egy érték nincs jelen. Az Optional-nak nem célja lecserélni minden egyes referenciát, de segítséget adhat sokkal egyértelműbb kód írásához azzal, hogy már egy metódus aláírását elolvasva látni fogjuk, hogy nem kötelező értéket ad vissza. A fenti egymásba ágyazott ifeket Optional használatával eztán így is írhatnánk:
String name = order.map(Order::getAddress)
.map(Address::getRecipient)
.map(Recipient::getFirstName)
.orElse("Ismeretlen");
Sajnos ez a kód nem fog lefordulni. Az order típusa Optional<Order>, tehát azon minden gond nélkül meg lehet hívni a map metódust. A getAddress() metódus viszont egy Optional<Address> típusú objektumot ad vissza. Ez azt jelenti, hogy a map művelet eredményének típusa Optional<Optional<Address>> lesz. Ezen nem lehet meghívni a getRecipient metódust, hiszen a külső Optional értékként egy másik Optional-t tartalmaz aminek persze nincs getRecipient metódusa.
A probléma megoldásához az Optional bevezette a flatMap metódust. Ez a fenti helyzetek kezelésére szolgál: "kilapítja" a műveletek eredményeként előálló kétszintű Optional struktúrákat. A kódot tehát át kell írni a flatMap használatára:
String name = order.flatMap(Order::getAddress)
.flatMap(Address::getRecipient)
.map(Name::getFirstName)
.orElse("Ismeretlen");
Az első flatMap biztosítja, hogy Optional<Address> legyen visszaadva Optional<Optional<Address>> helyett, a második pedig ugyanezt megteszi az Optional<Name> esetén. Harmadszorra viszont már elég egy map is, mert a getFirstName String-et ad vissza, nem pedig egy Optional<String>-et.
Problémák és tanácsok
Amikor először találkoztam ezzel az Optional-dologgal, felmerült bennem a kérdés, hogy mi szükség volt erre az egészre? Ez csak egy szimpla konténer ami referenciát tárol egy másik objektumra. Az a referencia attól még továbbra is lehet null (ha nem az of-fal gyártottuk le az Optional-t). A válasz filozófiai mélységekbe (vagy magasságokba) vezet!
Nos, a null érdekes dolog. A Java megpróbál a null-al valami hiányzó dolgot reprezentálni, de valójában egy hiány még nem feltétlenül kellene, hogy null-t jelentsen. Ráadásul a Java erősen típusos nyelv, a null-t viszont bármilyen referencia típusú változónak értékként tudjuk adni, tehát típus nélküliként viselkedik. Ha egy fejlesztő nem tudja, hogy a visszatérési érték mi legyen, akkor null-t ad vissza. A hívóra hárul a null ellenőrzés terhe, különben NullPointerException dobódhat. Nézzünk egy egyszerű példát (a rövidítés kedvéért egy osztályba vettem a logikát de érthető lesz):
package hu.egalizer.java8; import java.util.ArrayList; import java.util.List; public class OptionalPhilosophy { private static List<String> allLegoTheme = new ArrayList<String>(); static { allLegoTheme.add("Castle"); allLegoTheme.add("Pirates"); allLegoTheme.add("Classic Space"); allLegoTheme.add("Star Wars"); } public String findTheme(String theme) { return allLegoTheme.contains(theme) ? allLegoTheme.get(allLegoTheme.indexOf(theme)) : null; } public static void main(String[] args) { String themeName = new OptionalPhilosophy().findTheme("Star Trek"); System.out.println("Theme name is " + themeName.toUpperCase()); } }
A legó témakörökből egy adott téma nevének kikereséséhez az API fejlesztője bevezet egy findTheme metódust ami suttyomban null-t ad vissza ha a téma nevét nem találta. A hívó megbízik az API-ban és meghívja a findTheme-et majd a visszaadott értéket megpróbálja nagybetűsre konvertálva kiíratni. Csakhogy NullPointerException-t kap. Ez kinek a hibája? A hívóé vagy az API fejlesztőjéé?
Az API fejlesztője így gondolkodik: amikor a hívó megad egy nevet és az nem található a listában, akkor mit kéne csinálni? Visszaadjak egy üres vagy valami speciális sztringet? De ha a hívó esetleg nem akar üres sztringet, sem pedig valami meghatározott sztringet, akkor mit tehetnénk? Egyszerűbb ha null-t adunk vissza.
A hívás fejlesztője így gondolkodik: a findTheme egy API metódus és az API felelőssége, hogy kezelje a speciális eseteket amibe az is beletartozik, ha a keresett téma nem található. Ilyenkor üres sztringet kellene visszaadnia. Engem nem kell, hogy a null ellenőrzés érdekeljen, nem az én felelősségem.
Na most akkor kinek a hibája?
Saját szemszögéből a hívónak és a hívottnak is igaza lehet. A zavar ott van, hogy az API fejlesztője nem jelzi a hívónak, hogy a visszatérési érték lehet jelenlévő vagy hiányzó. A null azt jelenti, hogy nincs referencia, de nem eléggé kifejező hozzá, hogy jelezze a hívónak, hogy egy érték jelen van vagy hiányzik. Na itt lép be az Optional. Ez jelzi, hogy az érték jelen is lehet meg hiányozhat is, tehát a hívó felelőssége leellenőrizni, hogy ott van-e. Null visszaadásakor nincs meg ez az információ az érték természetéről.
Az Optional bevezetésétől egyébként nem volt mindenki elragadtatva. Kifogásolták például azt, hogy ha az Optional-ban nincs érték akkor az Optional.get() NoSuchElementException-t dob. Vagyis csak annyi történt, hogy kicseréltek egy nem ellenőrzött kivételt egy másikra. És a legtriviálisabb dolog: az Optional referencia is lehet null! Ha teljesen biztonságos kódot akarunk írni, akkor továbbra is írhatunk nullvizsgálatokat - az isPresent mellett. Hiszen nincs rá 100% garancia, hogy az Optional típusú visszatérési érték sosem lesz null, így szükség van egy kiegészítő feltételvizsgálatra és még egy további indirekció bejött egy érték elérésében. Egyébként ha egy már meglévő kódot Optional-osítunk, akkor a fordító nem is fog szólni érte, ha valahol egy metódusban a korábbi return null-t elfelejtettük return Optional.empty()-re kicserélni.
A null referencia hibákra egyébként a Sun már 2006-ban megpróbált megoldást keresni, de akkor még statikus kódanalizáló eszközökben gondolkodtak. Ez néhány szabványos annotáció lett volna, ami segítené a statikus analizáló eszközöket a nulleferencia hibák kiszűrésében. Ugyanazt a problémát próbálták megoldani mint amit az Optional típus, de anélkül, hogy nagy változásokat vezettek volna be a típuskezelési rendszerben. Ma már ilyen eszközök csak harmadik féltől származó eszközkészletben találhatóak meg, a szabványos Java-ba nem kerültek be.
Az Optional-t ért kritikákra Brian Goetz, a Java nyelv egyik fentebb is idézett tervezője egy Stack Overflow bejegyzésben így reagált: "Az emberek persze azt csinálnak vele amit akarnak. De nekünk egyértelmű volt a szándékunk amikor ezt hozzáadtuk a nyelvhez. Ez pedig nem az volt, hogy valamiféle általános célú dolgot csináljunk, mint egy Maybe vagy Some típus, amit többen szerettek volna. Az volt a célunk, hogy egy korlátozott lehetőséget biztosítsunk a könyvtári metódusok visszatérési értékeinek típusaihoz akkor amikor szükség volt, hogy egyértelműen ábrázoljuk a »nincs visszatérési érték« esetet és amikor ilyen esetekben a null használata túlnyomórészt feltehetően hibákat okozott volna. Ezt nem ajánlatos használni olyan esetben amikor valami tömböt vagy listát ad vissza, ilyen esetekben üres tömböt vagy üres listát érdemes visszaadni. Ugyanígy nem ajánlatos használni mezőként vagy metódusparaméterként. Szerintem ha ezt rutinszerűen getterek visszatérési értékeként használják, az túlhasználat. Semmi baj nincs az Optionallal, ami miatt esetleg el kellene kerülni, ez egyszerűen csak nem az a dolog, aminek az emberek szeretnék. [...]"
Eszerint a nyelv tervezőinek eredeti célja nem általános Optional bevezetése volt, viszont ezt igazából nem dokumentálták. Ez a Java dokumentációjában nincs benne, csak egy Stack Overflow válaszban. De már késő, mert általános célokra is elkezdték használni a fejlesztők, ezért itt van néhány jótanács, hogy ha már használjuk akkor hogyan is használjuk:
És egy kiegészítő tanács:
String nev = Optional.ofNullable(legoSet.getName()).orElse(DEFAULT_NAME);
Az új Stream API (java.util.stream) a Java 8 legösszetettebb újdonsága, egyben a lambdák mellett a második legfontosabb újítás és a funkcionális programozási stílus bevezetése a Java-ba. A Stream API nagyon dióhéjban egyszerűbbé és hatékonyabbá teszi a Java egyik legfontosabb összetevőjének, a collection-öknek a feldolgozását a feladatokat deklaratív módon leírhatóvá téve.
A Stream API bamutatására szintén a metódusreferenciáknál már látott legógyűjtemény-nyilvántartó példát fogom használni. Akárcsak korábban, ismét a LegoSet osztály fogja tárolni az adatbázisunkban egy készlet adatait. A következő ciklus Java 7 módon kiírja az adatbázisban lévő összes készlet nevét:
for (LegoSet ls : mySets) { System.out.println(ls.getName()); }
Az alábbi sor ugyanezt teszi, de már a Stream API-t, mégpedig a forEach aggregáló műveletet használva:
mySets.stream().forEach(e -> System.out.println(e.getName()));
A forEach paramétere egy lambda kifejezés, ami meghívja az e objektum getName metódusát és kiírja a visszatérési értékét. (A fordító kikövetkezteti, hogy az e objektum típusa LegoSet.) Bár ebben a példában az aggregáló műveletet használó megoldás hosszabb, mint a foreach, látni fogjuk, hogy az összetett adatkezelést igénylő feladatok sokkal tömörebben leírhatóak ezen a módon. A következő példa kiírja a collection-ben lévő legókészletek közül azokat amiknek az elemszáma nagyobb 2000-nél:
mySets.stream().filter(e -> e.getPieceCount() > 2000).forEach(e -> System.out.println(e.getName()));
Hasonlítsuk ezt össze azzal ami ciklust használ:
for (LegoSet set : mySets) { if (set.getPieceCount() > 2000) { System.out.println(set.getName()); } }
A filter visszaad egy új stream-et ami olyan elemeket tartalmaz, amik megfelelnek a metódus paramétereként átadott predikátumnak. Ebben a példában a predikátum a lambda kifejezés: e -> e.getPieceCount() > 2000. Ez boolean típusú értéket ad vissza, ami true, ha az e objektumban a pieceCount mező értéke 2000-nél nagyobb. A stream műveletei mindig új stream-et gyártanak, így a filter is, az új stream pedig az összes 2000 elemnél nagyobb készletet tartalmazza.
Az ezer mérföldes út az első lépéssel, a Stream fejezet pedig az alapfogalmakkal kezdődik:
(adat)forrás: a stream-ek adatokat biztosító forráson dolgoznak. Ilyen lehet egy collection, tömb vagy I/O erőforrás.
stream: egy steam adott típusú egymás után következő elemek sorozatához biztosít műveletvégző interfészt. A stream-ek nem tárolnak elemeket, csak igény szerint számítanak egy forrásból egy pipeline-on keresztül. Egy stream-nek nincs kötött, "véges" mérete, mint egy collection-nek. Olyan műveletek mint például a limit(n) vagy a findFirst() elméletben végtelen stream-eken is véges idő alatt képesek eredményt produkálni. Stream-ek létrehozására a Java 8 a következő lehetőségeket nyújtja:
Pipeline (csővezeték): sok stream művelet maga is stream-eket ad eredményül, ami lehetővé teszi, hogy az aggregáló műveletek sorozatát egy csővezetékké rendezzük. Ez lehetővé tesz bizonyos optimalizációkat, amiket később majd látni fogunk. Egy pipeline a következő összetevőket tartalmazza:
Aggregáló műveletek: funkcionális programozáshoz hasonló leírást lehetővé tévő műveletek. Két típusuk van:
Rövidzár műveletek: néhány műveletet ún. rövidzár műveletnek (short-circuiting) nevezünk. Egy közbülső művelet akkor rövidzár, ha véges stream-et tud produkálni eredményként akkor is amikor végtelen bemenettel látják el. Egy lezáró művelet akkor rövidzár, ha végtelen bemenet esetén is befejeződik véges idő alatt. Egy csővezetékben szükséges, de nem elégséges, hogy legyen rövidzár művelet ahhoz, hogy egy végtelen stream esetén is véges idő alatt befejeződjön a feldolgozása.
Lusta kiértékelés: minden közbülső művelet lusta kiértékelésű vagyis csak akkor hajtódik végre amikor szükség van rá. (Ellenkező esetben mohó.) A közbülső műveletek addig nem kezdik el a stream tartalmának a feldolgozását amíg a lezáró művelet végrehajtása el nem indul. A stream-ek lusta feldolgozása lehetővé teszi a Java fordítónak és futtatókörnyezetnek, hogy optimalizálja a stream-ek feldolgozását.
Escape-hatch műveletek: fentebb azt írtam, a lezáró műveletek majdnem mindig mohó kiértékelésűek. Két kivétel van: az iterator() és az spliterator(), amit escape-hatch műveleteknek hívunk. Ez a két lezáró művelet iterátort biztosít a stream-ekhez, ezzel lehetőséget ad arra, hogy saját magunk programozzuk le egy stream bejárását, ha a létező lezáró műveletek nem volnának elegendőek. Ez a két escape-hatch művelet abban is eltér a normál lezáró műveletektől, hogy lusta feldolgozású: ezeknél a stream-en lévő műveletek csak a következő elem lekérdezésekor hajtódnak végre.
Belső iteráció: a collection-ökön való iterálást expliciten nekünk kell leprogramoznunk, a stream műveletek az iterációkat maguk végzik el a színfalak mögött.
Most pedig, hogy az alapfogalmakat már ismerjük, merüljünk el a különböző típusú stream-ek és a stream-műveletek ingoványában.
Ha már a funkcionális interfészeknél és az Optional-nál is bevezettek a boxing/unboxing elkerülésére primitív típusokat közvetlenül kezelő osztályokat, a streamek se maradhattak ki. Három speciális stream típus létezik: IntStream, LongStream és DoubleStream. Ezek is a BaseStream interfészt implementálják és ezen kívül minden olyan metódust tartalmaznak, amit az általános Stream, néhány speciális aritmetikai művelettel kiegészítve.
Nézzük, hogy tudunk ilyen stream-et létrehozni például int tömbből:
IntStream intstream = Arrays.stream(new int[] { 42, 3, 67, 89, 12 }); intstream.min().getAsInt(); // 3-at ad eredményül
De itt is használhatjuk a Stream létrehozó függvényeit, mint például az of() a következő példában (a max() itt OptionalInt-et ad vissza):
int maxInt = IntStream.of(42, 68, 3, 89, 99).max().getAsInt(); // 99 lesz az eredmény
A "primitív" és az általános streamek között oda-vissza is tudunk konvertálni, ha nagyon szeretnénk. Primitív típusok boxingjához például:
List<Integer> parosak = IntStream.rangeClosed(1, 100)
.filter(i -> i % 2 == 0).boxed().collect(Collectors.toList());
A példa IntStream-mel indít, a boxed() közbülső művelet vált át Stream<Integer> típusra (a rangeClosed()-ról pár sorral lejjebb lesz szó, a collect(Collectors.toList()) pedig kigyűjti egy listába az eredményt, a collector-ról külön fejezet később). Az általános Stream pedig mapTo... és flatMapTo... közbülső műveletekkel teszi lehetővé az unboxingot:
DoubleStream dstream = Arrays.asList(49, 53, 78, 34).stream().mapToDouble(i -> i);
A három primitív típust alkalmazó stream azon lezáró műveletei amelyek mindenképpen adnak visszatérési értéket, már eleve primitív típust adnak vissza, tehát nem kell getAs... metódusokat hívni. Például:
int sum = IntStream.of(5, 7, 11, 13, 17).sum(); // eredmény: 53
Az IntStream és LongStream két olyan statikus generátor függvényt is tartalmaz, amikkel egészek sorozatát tartalmazó stream-et generálhatunk:
LongStream stream1 = LongStream.range(1, 100); LongStream stream2 = LongStream.rangeClosed(1, 100);
A különbség talán sejthető: a range esetén a záró érték már nem szerepel a stream forrásában, míg a másik esetben igen.
Az a szép ezekben, hogy így akár for ciklusokat is kiválthatunk velük, a párhuzamosítás pedig ezek után csak egy csuklómozdulat. Persze nem érdemes mindenhol ész nélkül használni, hiszen a hagyományos for gyakran olvashatóbb és hatékonyabb lehet mint a stream-ekkel megvalósított változat. A stackoverflow-n fel is merült a kérdés, hogy miért érdemes használni a range függvényeket?
Nos több ok miatt is.
IntStream.range(0, N).forEach(this::dolgozdFel);
int[] tombom = IntStream.range(0, N).toArray();
Ez utóbbi esetben is kérdéses, nem hatékonyab-e for ciklust használni? Nos kis tömböknél vélhetően elhanyagolható a stream hátránya, nagy tömböknél pedig valószínűleg nem az implementáció lesz a szűk keresztmetszet hanem a memória sávszélesség és a GC esetleges működése.
Akkor is hasznos a range, ha olyan problémát kell megoldani ahol a tömbindexek és az értékek is részt vesznek a számításban. Például egy tömbben meg akarjuk határozni azon indexeket ahol növekvő sorozatok indulnak (persze ezeket a feladatokat is meg lehet oldani ciklussal, de lehet olyan eset amikor a stream célszerűbb):
int[] elemek = { 1, 2, 4, 8, 9, 3, 5, 6, 7, 8, 0 };
int[] novekvok = IntStream.range(0, elemek.length)
.filter(i -> i == 0 || elemek[i - 1] > elemek[i]).toArray();
System.out.println(Arrays.toString(novekvok));
A program kimenete:
[0, 5, 10]
Nagy elemszámú bemenő tömbnél pedig az egyszerű párhuzamosíthatóság által kinyerhető teljesítménybeli plusz még további előnyt adhat a stream esetén.
Bizonyára mindenkinek azonnal szemet szúrt, hogy akárcsak az Optional és a funkcionális interfészek esetén, háromnál több primitív típus mintha itt se létezne. Brian Goetz a következőket mondta arról, miért döntöttek a többi kihagyása mellett:
"A specializált primitív típusok (például IntStream) megléte mögötti filozófia tele van csúnya kompromisszummal. Rengeteg benne a kódduplikáció és az interfész-szennyezés. (Interfész-szennyezés: amikor látszólag fölösleges dolgokra szánt interfészek lepik el az egyébként egyszerűnek és átláthatónak szánt API-nkat.) A boxed operandusokon végzett bármiféle aritmetika eleve elég nyűgös, de rossz lett volna ha nem lenne megoldásunk az int-ek méretének csökkentésére. Úgyhogy sarokba voltunk szorítva és megpróbáltuk a helyzetet nem rontani tovább. Két elv mentén haladtunk:
1. nem foglalkoztunk mind a nyolc primitív típussal. Csak az int, long és double típusokkal, a többi ezekkel már szimulálható. Akár még az int-től is megszabadulhattunk volna, de úgy véltük, a Java fejlesztők erre még nincsenek felkészülve. Volt igény a Character-re is, de erre az a válaszunk, hogy tegyétek bele egy int-be. Mindegyik specializáció nagyjából 100 KB növekedést okozott volna a JRE memóriafoglalásában.
2. primitív stream-eket használunk a primitív környezetben legmegfelelőbb dolgok elvégzéséhez (rendezés, redukció), de nem próbálunk meg duplikálni mindent amit egyébként a boxing világban is meg lehet csinálni. Tehát például nincs IntStream.into(). (Ha lenne akkor a következő kérdés az lenne, hogy hol az IntCollection, IntArrayList, IntConcurrentSkipListMap? A szándék az volt, hogy sok stream referencia stream-ként indulhat és végül primitív stream-ként végzi, de fordítva nem. Ezzel nincs gond és ez csökkenti a szükséges konverziókat (például nincs map túlterhelés az int -> T esetre és nincs specializáció a Function-ből az int -> T esetre, stb.)."
Az összetettebb műveletek izgalmaihoz az egyszerűbb műveleteken keresztül vezet az út, ezeket is át kell tekintenünk. A Stream interfész az alábbi általános közbülső műveleteket biztosítja a feldolgozáshoz.
filter(Predicate<? super T> predicate): egy stream elemeinek szűrése. Egy Predicate objektumot vár paraméterként és az eredmény stream-be csak azon elemek kerülnek át a forrásból amelyek megfelelnek a predikátumnak. Fentebb már több példa volt rá.
distinct(): a forrás stream-ből csak az egyedi elemeket hagyja meg. Az összehasonlításhoz az elemek equals() metódusát használja. Például:
List<String> lista = Arrays.asList("A", "B", "C", "A", "D", "C"); lista.stream().distinct().forEach(System.out::print);
A példa eredménye az "ABCD". Sokszor persze pont nem az equals szerint szeretnénk egyediséget vizsgálni, főleg nem saját objektumoknál. Ha tetszőleges mező szerinti distinct funkcionalitásra vágyunk akkor azt a filter() segítségével és egy kis kódolással lehet megoldani. Mivel a distinct alapvetően állapottartó művelet, nem ördögtől való dolog kiegészítő osztályt használni a filterhez:
/** * Állapottartó szűrő ahol T a stream elemeinek típusa. */ public class DistinctByKey<T> implements Predicate<T> { Map<Object, Boolean> seen = new ConcurrentHashMap<>(); Function<T, Object> keyExtractor; public DistinctByKey(Function<T, Object> ke) { this.keyExtractor = ke; } @Override public boolean test(T t) { return seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null; } }
A példában a DistinctByKey osztályt egyből a Predicate-ből származtattuk, ezért a filter-nek közvetlenül át lehet adni, vagyis:
mySets.stream().filter(new DistinctByKey<LegoSet>(LegoSet::getName));
Itt név alapján szűrjük le az egyedi készleteket a legó adatbázisunkban, vagyis csak egyet hagyva meg azokból amelyekből azonos néven több is szerepel. Viszont (láss csodát!) a feladatot külön osztály nélkül is meg lehet oldani ha kiemeljük a Predicate létrehozást egy metódusba:
public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Set<Object> seen = ConcurrentHashMap.newKeySet();
return t -> seen.add(keyExtractor.apply(t));
}
Ez így ugyanazt az eredményt adja mint a fenti megoldás:
mySets.stream().filter(distinctByKey(LegoSet::getName));
Első látásra (főleg Java 7-es szemmel) kissé érthetetlen a metódus működése. Minden egyes meghívásra új seen objektumot hoz létre? Akkor hol az állapottartó működés és hogyan tudja eltárolni a már megvizsgált elemeket? Nos a válasz a metódustörzs második sorában van: a metódus valójában csak egyszer hívódik meg, egyetlen seen objektumot hoz létre és egy Predicate objektumot ad vissza a lambda kifejezésből. A filter már ennek a Predicate objektumnak a test() metódusát fogja hívogatni, annak a törzse pedig a lambda kifejezés.
A megoldásnak persze van néhány apróbb problémája. Mivel a költő a párhuzamos streamekre is gondolt, a ConcurrentHashMap-et használja. Ez soros stream-eknél jelent némi (bár elhanyagolható) pluszmunkát. Párhuzamos stream-eknél viszont nem garantálható, hogy a megadott azonosnak tekintett objektumok közül mindig az elsőt tartja meg, mint a distinct. És nem szabad elfelejteni, hogy a metódus által visszaadott Predicate objektum nem újrahasznosítható, tehát értelemszerűen több stream-re ugyanaz nem fog működni, mindig újat kell létrehozni a distinctByKey meghívásával. A megoldásnak igazából csak egy csúnya tulajdonsága van: megsérti a Java 8 API filter-re vonatkozó kitételét, miszerint a Predicate paraméter nem lehet állapottartó. Bár Java 8 esetén működik és megfelel a célnak, későbbi Java verziók esetén esetleg okozhat kellemetlen meglepetést, ha az API máshogy implementálja a filter-t.
peek(Consumer<? super T> action): az eredeti stream minden egyes elemére elvégzi a paraméterként átadott műveletet, ami egy Consumer objektum. Főként debug célokra szánt művelet, például kiírathatjuk vele az aktuálisan feldolgozott elemet.
limit(long maxSize): ez a rövidzár művelet olyan streamet ad vissza, ami az eredeti streamből a maxSize méretnél nem több elemet tartalmaz.
skip(long n): ez a közbülső művelet olyan streamet ad vissza, emiből elhagyja az eredeti stream első n elemét. Ha az eredeti stream n-nél kevesebb elemet tartalmaz, akkor üres streamet ad vissza.
Ha nem vagyunk teljesen tisztában a stream csővezeték működésével, akkor olyan meglepetések érhetnek a skip és a limit kapcsán, mint a stackoverflow kérdezőjét. Mi is történt? Nézzük ezt a streamet:
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.peek(e -> System.out.print("\nA" + e))
.limit(3)
.peek(e -> System.out.print("B" + e))
.forEach(e -> System.out.print("C" + e));
A limit művelettel az elemek száma 3-ra van korlátozva, a fenti kódsor ezt az eredményt adja:
A1B1C1 A2B2C2 A3B3C3
Nézzük most a skip műveletet, itt átugorjuk az első 6 elemet:
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.peek(e -> System.out.print("\nA" + e))
.skip(6)
.peek(e -> System.out.print("B" + e))
.forEach(e -> System.out.print("C" + e));
Ezt az eredményt kapjuk:
A1 A2 A3 A4 A5 A6 A7B7C7 A8B8C8 A9B9C9 A10B10C10
A stackoverflow kérdezője meglepődött, hogy skip esetén miért lesz A1-A6 kiírás is? Mi már tudjuk a választ: a kulcs a lusta kiértékelés. Az elemekre a csővezetékben csak akkor van szükség amikor a lezáró művelet elkezd működni. Amint elkezdi feldolgozni a stream-et, a közbülső elemek feladata, hogy minden lépésnél a forrásból újra és újra előállítsák a szükséges elemet. Az első példában amikor a forEach lekéri az első elemet, a "B" peek-nek szüksége lesz egy elemre, így lekéri a limit kimeneti streamjéből. A limitnek tehát meg kell kérnie az "A" peek-et, ez pedig visszamegy a forráshoz egy elemért. Onnan visszajön egy elem, majd az egész folyamat visszafelé felmegy a forEach-ig és megvan az első sor:
A1B1C1
A forEach kérésére minden további alkalommal oda-vissza végigmegy a kérés az egész csővezetéken. Amikor a forEach a negyedik elemnél tartana, amint a kérés eléri a limit műveletet, az már tudja, hogy az öszes szükséges elemet átadta amit lehetett. Nem kér tehát újabb elemet az "A" peektől, hanem jelzi, hogy nincs több elem, a feldolgozás ezért befejeződik.
A második példában picit más a helyzet. A forEach itt is elkezdi lekérni az elemeket. A kérés végigfut a csővezetéken visszafelé. Amikor eléri a skip műveletet, annak előbb 6 elemet el kell kérni a forrás streamjétől és csak az azokat követő elemeket tudja továbbadni az eredmény steram felé. Tehát hat kérés fut a forrás felé az "A" peeken keresztül, de ezeket az elemeket a skip egyenként elnyeli anélkül, hogy továbbadná az eredmény stream felé. A hat kérés miatt 6 kiírás is megtörténik az "A" peek-ben:
A1 A2 A3 A4 A5 A6
A 7. kérésnél a skip már továbbadja az elemet a "B" peek felé és innen továbbmegy a forEach-hez, tehát a teljes kimenet megjelenik:
A7B7C7
A helyzet ezt követően hasonló az előző esethez; a kérések oda-vissza átmennek a csővezetéken amíg a teljes forrás el nem használódik.
Bár a párhuzamos streameket csak egy későbbi fejezetben fogom bemutatni, már most elárulom, hogy a skip és a limit a soros streameknél viszonylag kis költségű művelet, de nem így a párhuzamos streameknél. Azoknál elég költséges is lehet, különösen az n és a maxSize nagy értékeire, hiszen ezek a stream első n elemét mindenképpen fel kell hogy dolgozzák. Párhuzamos streameknél a rendezettség megszüntetése (például a BaseStream.unordered()), ha a feladat engedi jelentős teljesítménybeli növekedést eredményezhet.
A rendezés és rendezettség kérdésköre egy picit összetettebb a streamek világában, ezért megérdemel egy külön fejezetet. A rendezettség alapvetően meghatározza azt, hogy milyen sorrendben dolgozza fel a stream az adatokat, de még a feldolgozás teljesítményét is befolyásolja. De még mielőtt bővebben megnéznénk a rendezést, nagyon fontos tisztázni két dolgot. A Stream API gyakran használja az ordered fogalmat, ami magyarul rendezettet jelent. Csakúgy, mint a sorted. De a kettő nem ugyanazt jelenti (legalábbis a Java 8 API-ban)!
Ordered: azt jelenti, hogy bizonyos adatstruktúrák elemei között egymásutániság, sorrendiség értelmezett. Vagyis meg lehet határozni, hogy ez a 0., ez az 1., ez pedig az n. elem. Ilyen például a tömb vagy a lista de nem ilyen például a halmaz. A Stream API tárgyalásakor az ordered fogalmat "rendezett"-nek fordítottam, de fontos látni, hogy ez nem ugyanaz, mint a sorbarendezett:
Sort(ed): sorbarendezés, sorbarendezett. Az elemek sorrendje valamilyen reláció által meghatározott, például névsor szerint rendezett. Ezt a fogalmat sorbarendezésnek és sorbarendezettnek fordítottam. A sorbarendezett egyben rendezettet is jelent, de a rendezett még nem biztos, hogy sorbarendezett is.
Hacsak másként nem egyértelmű a szövegből hogy mikor melyikről van szó, akkor a rendezettség és a sorbarendezettség fogalmak olvasásakor a fenti két dologra kell gondolni. Ezek után pedig lássuk a lényeget. A stream az adatokat a forrásból veszi (és a vízbűl veszi ki a zoxigént), itt pedig máris szembejön egy új fogalom:
Encounter order: az elemek azon sorrendje (order), ahogyan a stream számára elérhetővé válnak feldolgozásra. Hogy egy stream rendezett-e, az függ a forrástól és az esetleges megelőző közbülső műveletektől. Bizonyos források (a List vagy tömbök) természetükből adódóan rendezettek, mások (mint például a Set) nem.
A rendezettséggel két közbülső művelet foglalkozik:
A rendezést az unordered metódussal a csővezeték bármely pontján megszüntethetjük. Az alábbi példában a később tárgyalandó párhuzamos streameket használom, mert párhuzamos feldolgozásnál jobban szembetűnő a rendezettség kérdése:
Set<Integer> set = new TreeSet<>(Arrays.asList(2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83)); Object[] result = set.stream().parallel().limit(5).toArray(); // A tömbbe ez fog kerülni: 2, 3, 5, 7, 11 Object[] result = set.stream().unordered().parallel().limit(5).toArray(); // A tömb tartalma meghatározatlan
Ha egyszer már meghívtuk az unordered() metódust, akkor nincs mód visszaállítani az eredeti rendezettséget. Egy sorted persze sorbarendezettséget hozhat a stream életébe, de az nem feltétlenül fog megegyezni az eredeti sorrenddel.
Ha egy stream rendezett, akkor a legtöbb művelet ezt meg is tartja függetlenül attól, hogy a stream típusa párhuzamos vagy soros. Ha egy stream forrása egy List, ami az [1,2,3] elemeket tartalmazza, akkor a map(x -> x*2) végrehajtásának eredménye [2, 4, 6] kell, hogy legyen. Ha viszont a forrásnak nincs encounter order-je akkor a [2, 4, 6] bármely permutációja is lehetséges eredmény. De ahhoz, hogy a rendezettség egy teljes csővezetéken keresztül fennmaradjon, tudnunk kell, hogy a forrás és minden közbülső valamint a lezáró művelet megtartja-e a rendezettséget vagy nem. A forEach például nem tartja meg a rendezettséget. Ha erre mégis szükség van akkor a forEachOrdered lezáró műveletet kell használni.
Soros stream-eknél az encounter order megléte vagy hiánya nem befolyásolja a teljesítményt, csak a determinizmust. Ha a stream rendezett, akkor azonos stream csővezetékek ismételt végrehajtása azonos forráson azonos eredményt ad. Ha nem rendezett, akkor ismételt végrehajtások során különböző eredményeket kaphatunk. Párhuzamos stream-eknél viszont a rendezés elhagyása néha sokkal hatékonyabb végrehajtást tesz lehetővé. Bizonyos aggregáló műveletek, mint a duplikátumok kiszűrése (distinct()) vagy a csoportosított redukciók (Collectors.groupingBy()) sokkal hatékonyabban implementálhatók, ha az elemek sorrendje lényegtelen. Azon műveleteknek amelyek eredendően kötődnek az encounter orderhez, mint például a limit(), szükségük lehet pufferelésre a megfelelő sorrend biztosításához. Ez viszont eltünteti a párhuzamosság előnyeit. Ha a stream-nek van encounter orderje, de a felhasználót igazából ez nem érdekli, akkor a rendezettség explicit megszüntetése (de-ordering az unordered() metódussal) növelheti a párhuzamos teljesítményt bizonyos állapottartó vagy lezáró műveleteknél. De a legtöbb stream csővezeték hatékonyan párhuzamosítható még a rendezettségi feltételek megléte esetén is.
A következő példa bemutatja, hogyan is néz ki a (sorba)rendezettség a stream-ek feldolgozásánál:
Integer[] intArray = { 1, 2, 3, 4, 5, 6, 7, 8 };
List<Integer> integerList = Arrays.asList(intArray);
System.out.println("integerList:");
integerList.stream().forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("integerList visszafelé rendezve:");
Comparator<Integer> normal = Integer::compare;
Collections.sort(integerList, normal.reversed());
integerList.stream().forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("Parallel stream");
integerList.parallelStream().forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("Újabb parallel stream:");
integerList.parallelStream().forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("forEachOrdered-del:");
integerList.parallelStream().forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
A példa 5 csővezetéket tartalmaz és a következő eredményt adja:
integerList: 1 2 3 4 5 6 7 8 integerList visszafelé rendezve: 8 7 6 5 4 3 2 1 Parallel stream 3 4 1 2 6 7 5 8 Újabb parallel stream: 3 7 1 6 2 8 4 5 forEachOrdered-del: 8 7 6 5 4 3 2 1
Az eredményből a következő megfigyeléseket tehetjük:
A rendezettség után nézzük a sorbarendezettség kérdését. A stream elemeinek sorbarendezésére két metódus áll rendelkezésre:
sorted(): rendezés az elemek "természetes" sorrendjében (natural ordering). A következő egyszerű példa sztringeket rendez ábécérendbe:
Stream<String> rendezetlen = Arrays.asList("C", "A", "D", "B", "F", "E").stream(); rendezetlen.sorted().forEach(System.out::println);
sorted(Comparator<? super T> comparator): rendezés egy Comparator segítségével. A következő példa a sztringeket a hosszuk szerinti növekvő sorrendbe rendezi:
Stream<String> rendezetlen = Arrays.asList("egy", "kettő", "három", "négy", "öt", "hat", "hét", "nyolc", "kilenc", "tíz").stream(); rendezetlen.sorted((s1, s2) -> s1.length() - s2.length()).forEach(System.out::println);
A lambda kifejezés helyett ebben a példában is használhatunk metódusreferenciát:
rendezetlen.sorted(Comparator.comparingInt(String::length)).forEach(System.out::println);
A sorted rendezett streameknél stabil, vagyis a rendezés feltételére nézve azonos kulcsú elemek a rendezett kimenet encounter orderjében ugyanolyan sorrendben fognak szerepelni mint a forrás encounter orderjében.
Gondolom az előzőekből mindenkinek egyértelmű, hogy a sorted() közbülső művelet semmiféle módosítást nem végez a forráson. A stackowerflow-n ugyanis felmerült olyan kérdés, ahol a kérdező azt hitte, a Stream.sorted() a Collection-t rendezi.
Java 8-ban a java.util.Comparator funkcionális interfész lehetőségei jócskán megszaporodtak default és statikus metódusokkal. Az új metódusok mindig új Comparator példányt adnak vissza, így a Comparator-ok összefűzésével lehetővé válik összetettebb rendezési kifejezések leírása is, a lambdákkal pedig sokkal egyszerűbben is használható, mint korábban anonim belső osztállyal.
Emellett a List interfész is kiegészült egy sort(Comparator<? super E> c) metódussal a collection rendezéséhez, az Arrays osztály pedig a már eddig is meglévő tömb-rendező sort mellé kapott egy sor parallelSort függvényt is különböző típusú tömbök párhuzamos rendezéséhez. Ezek egy részében szintén használhatunk komparátort. Érdemes áttekinteni a Comparator újdonságait mert ezt a fentiek mellett a stream-ek rendezésére is fel tudjuk használni (lásd: sorted(Comparator<? super T> comparator)).
A Comparator új metódusai:
comparing(Function<? super T,? extends U> keyExtractor): egy T típusú Comparator-t ad vissza ami a keyExtractor által adott értékeket fogja összehasonlítani (ezeknek értelemszerűen a Comparable interfészt implementálniuk kell). Ha például a legókészleteinket név szerint rendező comparator-t szeretnénk előállítani, akkor ezt így tehetjük meg:
Comparator<LegoSet> byName = Comparator.comparing(LegoSet::getName);
comparing(Function<? super T,? extends U> keyExtractor, Comparator<? super U> keyComparator): az előző metódus kiegészítve egy keyComparator paraméterrel, ami a keyExtractor által adott értékek összehasonlítását végzi, ha esetleg az nem implementálná a Comparable interfészt vagy nem a természetes rendezését szeretnénk használni.
A természetes rendezés (natural ordering) azon osztályokon végezhető el, amelyek implementálják a Comparable interfészt. Ilyenkor a rendezést autmatikusan ezen Comparable interfész implementációjának megfelelően végzi el a Java osztálykönyvtár. De ha mi nem ezt szeretnénk, akkor jönnek jól a Comparator interfész keyComparator paraméteres metódusai. Így például tudunk rendezni sztringeket névsor helyett akár a hosszuk alapján:
Comparator<LegoSet> byNameLength = Comparator
.comparing(LegoSet::getName, (s1, s2) -> s1.length() - s2.length());
A már ismerős filozófia alapján természetesen itt is kitüntettt szerepe van az int, double és long primitív típusoknak, ezért létezik comparingDouble, comparingInt és comparingLong metódus is, amelyek ugyanúgy comparatort adnak vissza, csak keyExtractor paraméterként olyan lambda kifejezést (metódusreferenciát) várnak, ami az adott primitív típussal tér vissza.
naturalOrder(): Comparable-t implementáló osztályokhoz természetes sorrendbe rendező Comparator előállítása.
nullsFirst(Comparator<? super T> comparator): null-barát Comparator, ami a null-t kisebbnek tekinti a nem-nullnál. (Két null azonos.) Ha az összehasonlítandó értékek egyike sem null akkor a paraméterként megadott comparator segítségével lesznek összehasonlítva. Paraméterként egyébként trükkös módon null-t is megadhatunk, ekkor a létrejövő Comparator minden nemnull értéket azonosnak fog tekintetni.
nullsLast(Comparator<? super T> comparator): ugyanaz mint a fenti csak annyi különbséggel, hogy a nullokat itt nagyobbnak tekinti a nemnulloknál.
reversed(): az aktuális Comparator példány visszafelé rendező változata.
reverseOrder(): a természetes rendezés visszafelé rendező változata.
thenComparing(Comparator<? super T> other): új Comparator példánnyal újabb rendezési kulcs hozzáadása Comparator láncunkhoz. A thenComparing úgy működik, hogy ha az aktuális Comparator két elemet azonosnak talál (vagyis compare(a,b)==0) akkor az other-t hívja meg a sorrend meghatározásához. Például egy String típusú collection-t először hossz majd pedig (azonos hosszak esetén) nagybetű-kisbetű független természetes sorrendbe rendező Comparator előállításához ezt kell begépelnünk:
Comparator<String> comp = Comparator
.comparingInt(String::length)
.thenComparing(String.CASE_INSENSITIVE_ORDER);
thenComparing(Function<? super T,? extends U> keyExtractor): a keyExtractor-t használó T típusú Comparator előállítása. Ha az aktuális Comparator két elemet azonosnak talál (vagyis compare(a,b)==0) akkor ez az új lesz felhasználva a sorrend meghatározásához. A legókészleteinket rendezhetjük például kiadás éve, az azonos évben kiadottakat pedig névsor szerint így:
Comparator<LegoSet> byYearThenName = Comparator
.comparingInt(LegoSet::getYearReleased)
.thenComparing(LegoSet::getName);
Akárcsak a comparing(Function<? super T,? extends U> keyExtractor) metódusból, a thenComparing(Function<? super T,? extends U> keyExtractor) metódusból is létezik thenComparingDouble, thenComparingInt és thenComparingLong változat.
thenComparing(Function<? super T,? extends U> keyExtractor, Comparator<? super U> keyComparator): az előző metódus kiegészítése azzal, hogy azonos elemek esetén a keyComparator comparatorral rendezünk a keyExtractor szerint. A fenti példát ezzel módosíthatjuk úgy is, hogy az azonos évben kiadott készleteinket névsor szerint visszafelé rendezzük:
Comparator<LegoSet> byYearThenName = Comparator
.comparingInt(LegoSet::getYearReleased)
.thenComparing(LegoSet::getName, Comparator.reverseOrder());
A visszafelé rendezésre egyébként a már megismert reversed() is eszünkbe juthatna - mégpedig jogosan. Viszont vigyázat! Új Comparator láncba fűzése az egész megelőző láncra vonatkozik, tehát a fenti helyett ezt írva:
Comparator<LegoSet> byYearThenName = Comparator
.comparingInt(LegoSet::getYearReleased)
.thenComparing(LegoSet::getName)
.reversed();
az egész listánk fog visszafelé rendeződni nem pedig az egy évben kiadott készletek listája. Ha ezt írjuk:
Comparator<LegoSet> byYearThenName = Comparator
.comparingInt(LegoSet::getYearReleased)
.reversed()
.thenComparing(LegoSet::getName);
akkor pedig az évek szerint visszafelé, de egy éven belül névsor szerint növekvő listát kapunk.
Közbülső műveletek esete a rendezettséggel
skip(long n): igen költséges művelet a rendezett párhuzamos stream-eknél (pláne nagy n-eknél), mert a szálaknak várniuk kell egymásra. Az eredmény kiszámításához figyelembe kell venni az encounter order-t, hiszen ez nem akármelyik, hanem az első n elemet hagyja el a stream-ből. Ha a forrás eleve rendezetlen, vagy a stream-et rendezetlenné tesszük (unordered()) az jelentős sebességnövekedést okoz a műveletben, bár így már nem lehet első n elemről beszélni.
limit(long maxSize): párhuzamos stream-eknél a fentebb részletezett okokból szintén költséges művelet. A rendezetlenné tétel itt is növelheti a teljesítményt.
peek(Consumer<? super T> action): a Stream és leszármazottaiban (IntStream, LongStream és DoubleStream) lévő peek művelet nem foglalkozik a rendezettséggel, tehát párhuzamos streamek esetén bármilyen sorrendben végrehajtódhat.
distinct(): rendezett steameknél a stabilitás biztosítása miatt a distinct igen költséges. A rendezettség megszüntetése növelheti a párhuzamos végrehajtás sebességét, de onnantól kezdve a stabilitás nem biztosított: amelyik duplikátum később jön, az lesz kihagyva függetlenül attól, hogy mi volt az encounter order.
Az alábbi példa szépen bemutatja, mit is jelent a stabilitás a rendezettségnél:
package hu.egalizer.java8; import java.util.Arrays; import java.util.stream.Stream; public class DistinctExample { private static int i = 1; private int id = i++; private String s; public static void main(String[] args) { Object[] exampleObjects = generateStream().parallel().distinct().toArray(); System.out.printf("ordered distinct: %s%n", Arrays.toString(exampleObjects)); DistinctExample.i = 1; exampleObjects = generateStream().unordered().parallel().distinct().toArray(); System.out.printf("unordered distinct: %s%n", Arrays.toString(exampleObjects)); } public static Stream<DistinctExample> generateStream() { DistinctExample[] de = new DistinctExample[] { new DistinctExample("a"), new DistinctExample("b"), new DistinctExample("c"), new DistinctExample("b"), new DistinctExample("c"), new DistinctExample("a") }; return Stream.of(de); } public DistinctExample(String value) { s = value; } @Override public int hashCode() { return s != null ? s.hashCode() : 0; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null || getClass() != obj.getClass()) return false; DistinctExample other = (DistinctExample) obj; if (s == null) { if (other.s != null) return false; } else if (!s.equals(other.s)) return false; return true; } @Override public String toString() { return "DistinctExample [id=" + id + ", s=" + s + "]"; } }
A futtatás eredménye:
ordered distinct: [DistinctExample [id=1, s=a], DistinctExample [id=2, s=b], DistinctExample [id=3, s=c]] unordered distinct: [DistinctExample [id=1, s=a], DistinctExample [id=4, s=b], DistinctExample [id=3, s=c]]
Rendezett esetben azok a karakterek kerülnek az eredmény streambe amelyek a forrásban elsőként következtek (az id szolgál a sorrend meghatározására). Rendezetlen esetben meghatározatlan.
map(Function<? super T,? extends R> mapper): a művelet egy új streamet ad vissza ami az eredeti stream elemeire alkalmazott mapper eredményeit tartalmazza. Az Optional-hoz hasonlóan a map itt is megváltoztat(hat)ja a stream generikus típusát. Az alábbi példában a sztringek stream-jéből a sztringhosszak stream-je lesz:
Stream<String> source = Arrays.asList("ec", "pec", "kimehetsz").stream(); Stream<Integer> mapped = source.map(s -> s.length());
Három speciális map művelet is van, ezek közvetlenül primitív típusú stream-et adnak vissza:
flatMap(Function<? super T,? extends Stream<? extends R>> mapper): lehetővé teszi összetett adatszerkezetek esetén a Stream<Stream<R>> szerkezetek elkerülését (hasonlóan mint az Optional.flatMap()). A flatMap szintén egy Function paramétert vár, csak ennek a visszatérési típusa nem az eredeti stream elemeinek a T típusa, hanem egy újabb stream, ami R típusú elemeket tartalmaz (bár R lehet azonos a T-vel):
<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper)
Vagyis a map művelethez képest annyi az eltérés, hogy itt nem R hanem Stream<? extends R> a mapper visszatérési értéke. Amikor ezt a mappert az eredeti stream elemeire alkalmazzuk, minden egyes elemre egy új elemeket tartalmazó stream-et ad eredményül. Ezen új stream-ek elemei aztán tovább másolódnak egy újabb stream-be és ez lesz aztán a flatMap tényleges visszatérési értéke.
Ha ez így kissé komplikáltan hangzik, csak semmi pánik, a példák során rögtön meg fogunk világosodni! Tegyül fel, hogy van egy sztringlistákat tartalmazó lista forrásunk:
[[egy, kettő, három], [négy, öt, hat], [hét, nyolc, kilenc]]
A sztring elemeket a map művelettel nem célszerű feldolgozni, mert ebben az esetben az sztringlistákat fog megkapni, nem pedig sztringeket. Ha viszont a listák listáját "kilapítjuk" így, akkor már egész jól lehet kezelni:
[egy, kettő, három, négy, öt, hat, hét, nyolc, kilenc]
Kódügyileg ez a következőképp néz ki:
List<List<String>> lapitsKi = Arrays.asList(Arrays.asList("egy", "kettő", "három"), Arrays.asList("négy", "öt", "hat"), Arrays.asList("hét", "nyolc", "kilenc")); lapitsKi.stream().flatMap(num -> num.stream()).forEach(System.out::println);
A forEach() már egy Stream<String>-en megy végig, nem pedig egy Stream<Stream<String>>-en (ezt tenné ha a flatMap helyett a map műveletet használnánk). Ha az eredményt el szeretnénk tárolni, akkor használhatjuk a collect lezáró műveletet (és a num -> num.stream() helyett a flatMap paramétereként ebben a példában ezt is írhatnánk: Collection::stream):
List<String> eredmeny = lapitsKi.stream().flatMap(num -> num.stream()).collect(Collectors.toList());
A collect műveletről később bővebben lesz szó.
Figyeljük meg, hogy a flatMap paraméterében a Collection.stream() állítja elő az új rész-streameket, amelyek alapján a flatMap majd elvégzi a "kilapítást". Egyes példák hibásan a num -> Stream.of(num) formát használják ehelyett. Az itt csak akkor működne ha az eredeti adatszerkezet List<String> lenne (akkor meg nincs szükség a flatMap-re). Mégpedig azért mert a két stream létrehozó függvény eltérő:
A Collection<E> esetén:
default Stream<E> stream()
A Stream esetén:
static <T> Stream<T> of(T... values)
Mivel a példában a num típusa List<String>, ezért a stream() függvény eredményének típusa: Stream<String>
A Stream.of() eredményének típusa pedig: Stream<List<String>>
Az eddigi példákban az eredmény generikus típusa nem tért el a forrástól, lássunk egy másik példát ahol igen. Egészítsük ki a LegoSet osztályt egy listával ami a készletben lévő elemeket tartalmazza. Egy elemet a LegoBrick osztály tartalmaz, ennek belső szerkezete most itt igazából lényegtelen. A LegoSet ezzel egészül ki:
package hu.egalizer.java8.lego; import java.time.LocalDate; import java.util.List; public class LegoSet { ... private List<LegoBrick> bricks;// a készlet elemei ... public List<LegoBrick> getBricks() { return bricks; } public void setBricks(List<LegoBrick> bricks) { this.bricks = bricks; } ... }
Ki szeretnénk gyűjteni a teljes gyűjteményünk, vagyis az adatbázisban lévő összes készlet összes elemét egy listába. A flatMap használatával ez már pofonegyszerű:
List<LegoBrick> myBricks = mySets.stream()
.flatMap(legoset -> legoset.getBricks()
.stream())
.collect(Collectors.toList());
A List<LegoSet> adatszerkezetből egy List<LegoBrick> lett.
Levezetésként pedig még egy utolsó flatMap példa, többdimenziós tömbbel, ami kigyűjti a forrásból a páratlan számokat:
Integer[][] ints = { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
Arrays.stream(ints)
.flatMap(row -> Arrays.stream(row))
.filter(num -> num % 2 == 1)
.forEach(System.out::println);
Itt - mivel tömbökről van szó és a Stream.of paramétere is tömb - a flatMap(row -> Stream.of(row)) forma is megfelelő lenne az átalakításhoz.
Ja, és el ne felejtsem: flatMap-ből is létezik értelemszerűen flatMapToDouble, flatMapToInt és flatMapToLong, ahol a Function paraméternek a visszatérési típusa a megfelelő primitív típusú stream kell legyen.
Végül pedig egy érdekességet mutatok be a filter és map műveletekkel. Metódusreferenciaként ugyanis akár a class osztály metódusait is használhatjuk! Legyen egy jó kis vegyes stream-ünk:
Stream<Object> csalamade = Stream.of("hurkapiszka", 123, new LegoSet(), "Java 8"); List<String> stringjeink = csalamade .filter(String.class::isInstance) .map(String.class::cast) .collect(Collectors.toList());
A filter metódusban a sztringeket szűrjük ki, majd a map metódusban saját magukra castoljuk, hogy Stream<String>-ünk legyen. Azt nem árt azért tudni, hogy a Class<T>::isInstance csak azt nézi, hogy a paraméterként átadott érték adható-e T típusú változónak, vagyis Object.class.isInstance("valami") is true-t fog visszaadni, mert Object típusú változónak is adhatjuk a "valami" értéket. Ha a filterben pontosan egy kívánt típusra (mondjuk épp String-re) szeretnénk szűrni, akkor azt így tehetjük meg (esetleg egy nullvizsgálattal is kiegészíthetjük ha a streamünk tartalmazhat null-t):
filter(e -> e.getClass().equals(String.class))
Eddigi példáinkban a forrás mindig ismert volt már a stream létrehozása előtt. Mi a helyzet, ha úgy szeretnénk stream csővezetéket végrehajtani, hogy a forrás elemek és azok száma csak végrehajtás közben válik ismertté? Java 8-cal ez is lehetséges! Ebben az esetben ún. végtelen (más néven nem korlátozott - unbounded) stream-eket tudunk használni. A végtelen stream-ek használata a lusta feldolgozás miatt lehetséges, hiszen a forrás elemeit így elég csak a lezáró művelet végrehajtásakor ismerni. A Stream interfész két módszert ad végtelen stream-ek létrehozására:
generate(Supplier<T> s): soros, rendezetlen stream-et állít elő. Paramétereként egy Supplier-t kell megadnunk. Ez minden egyes alkalommal meghívódik amikor új stream elemre van szükség. Egy faék egyszerűségű példa:
Stream<Double> infinite = Stream.generate(Math::random);
A példában a Math::random a Supplier, ami az infinite stream használatakor majd mindig visszaad egy új véletlenszámot. Végtelen streamek használatakor alkalmaznunk kell egy olyan rövidzár műveletet ami egyszer majd lezárja a feldolgozást, különben a stream feldolgozása valóban az idők végezetéig tartana. Leggyakoribb módszer a limit metódus, ami a streamből legföljebb a megadott számú elemet hagyja meg. Ennek a segítségével a következő példában 10 véletlenszámból álló tömböt állítunk elő:
double[] randoms = infinite.limit(10).mapToDouble(i -> i).toArray();
Állapottartó művelettel generálhatunk például Fibonacci-számokat:
private static class FibonacciSupplier implements IntSupplier { int previous = 1; int current = 0; @Override public int getAsInt() { int result = current; current = previous + current; previous = result; return result; } } ... IntStream stream = IntStream.generate(new FibonacciSupplier()); stream.parallel().limit(30).forEach(System.out::println);
(Ha a previous és a current kezdő értékeit megcseréljük 1,0 helyett 0,1-re akkor a régebben elfogadott 1,1,2,... sor kapjuk a 0,1,1,2 helyett.)
Ha állapottartó műveletet használunk Supplier-ként akkor párhuzamos stream-ek használatakor meghatározatlan eredményt kaphatunk.
A generate függvénnyel tetszőleges típusú elemeket állíthatunk elő. Például ha a legókészlet adatbázisunkat tesztelés miatt generált készletekkel szeretnénk feltölteni és már van egy constructLegoSet() metódusunk ami véletlenszerűen előállít egy új készletet, akkor azt használhatjuk a következőképpen:
Supplier<LegoSet> legoSetSupplier = StreamExample1::constructLegoSet;
List<LegoSet> randomSets = Stream.generate(legoSetSupplier)
.skip(10)
.limit(10)
.collect(Collectors.toList());
A skip metódussal kihagyjuk az első 10 generált készletet majd a következő 10-et berakjuk egy listába.
iterate(T seed, UnaryOperator<T> f): soros, rendezett stream-et állít elő. Két paramétert vár: egy kezdeti, seed-nek nevezett elemet és egy függvényt, ami mindig legenerálja az előző elem alapján a következőt. Egy újabb faék egyszerűségű példa:
Stream<Integer> parosSzamok = Stream.iterate(2, i -> i + 2);
Az iterate generáló függvényt se érdemes egyébként párhuzamos streameknél használni.
Mint mondottam, végtelen stream-ek csővezetékében valóban legyen valahol egy rövidzár művelet (lezáró vagy közbülső), különben nem csak elméletben hanem a gyakorlatban is végtelen lesz. És bizony nem árt az éberség, mert teljesen észrevétlenül is írhatunk végtelen stream-eket, mint például:
IntStream.iterate(0, i -> (i + 1) % 2).distinct().limit(10).forEach(System.out::println);
A példa váltakozó nullákat és egyeket generál, aztán csak az egyedi értékeket, vagyis egy 0-t és 1-et tart meg. Eztán korlátozzuk a stream-et 10 elemre, majd felhasználjuk az elemeket. És a kód végtelenségig akar majd futni, ugyanis a distinct nem tudja, hogy az iterate metódusnak átadott függvény soha nem generál kettőnél több különböző elemet, hanem többet vár. És csak vár. (Ha a limit és distinct műveleteket megcseréljük, akkor ugyan szemantikailag más kódot kapunk, viszont már nem fog végtelenségig futni.) A kódot még szebbé tehetjük ha párhuzamosítjuk:
IntStream.iterate(0, i -> (i + 1) % 2)
.parallel()
.distinct()
.limit(10)
.forEach(System.out::println);
Így az összes elérhető processzormagot a végtelen futás szolgálatába lehet állítani!
A Stream interfészen kívül a Random osztály metódusaival is lehet végtelen stream-eket előállítani:
A két ints metódusnak megvan a doubles és longs párja is. A SplittableRandom osztály a Random párhuzamos feldolgozáshoz optimalizált változata, szintén rendelkezik ezekkel a végtelen stream előállító metódusokkal. A Random használatára egy egyszerű példa (megállunk 10-nél):
new Random().ints().limit(10).forEach(System.out::println);
Az ints-nek van paraméterezhető változata is aminek megadhatjuk a kívánt számú véletlemszám mennyiségét, ha nem végtelent szeretnénk. Többszálú programokban a ThreadLocalRandom.current() hívással érdemes Random objektumhoz jutni.
A stream API-ban nagyon csábító, hogy a közbülső műveleteket bármilyen sorrendben írhatjuk, de ha jót akarunk, akkor érdemes átgondolni egy csővezeték létrehozását. Tekintsük a következő példát:
valamilyenCollection.stream()
.map(e -> valamilyenFunction(e))
.collect(Collectors.toList())
.subList(0, 10);
Első ránézésre nincs vele semmi gond; valamilyen függvénnyel leképezzük a collectiont, majd listába szervezzük az eredményt, abból pedig vesszük az első 10 elemet. De adjunk csak annak a map-ben használt függvénynek egy kicsit beszédesebb nevet:
valamilyenCollection.stream()
.map(e -> marhaKoltsegesFunction(e))
.collect(Collectors.toList())
.subList(0, 10);
Minek is végezzük el a collection minden egyes elemére a költséges műveletet, ha aztán csak az első 10 eleme kell az eredménynek? Ha feltesszük, hogy az explicit rendezés nem lényeges, akkor a fenti sort sokkal hatékonyabbra is írhatjuk:
valamilyenCollection.stream()
.limit(10)
.map(e -> marhaKoltsegesFunction(e))
.collect(Collectors.toList());
A tanulság: érdemes előbb mindig lecsökkenteni a stream által használt elemek számát és csak aztán mappelni!
A példa kitalálója persze kicsit trükkös volt, mert a subList nem stream művelet (de az elv attól még helyes). De várjunk csak! Nem arról volt szó, hogy a stream lusta kiértékelésű? Akkor meg nem mindegy, milyen sorrendben írjuk a közbülső műveleteket? Íme egy példa kétféleképpen írva:
Stream.iterate(0, i -> i + 1)
.map(i -> i + 1)
.peek(i -> System.out.println(i + ". map"))
.limit(5)
.forEach(i -> { });
Stream.iterate(0, i -> i + 1)
.limit(5)
.map(i -> i + 1)
.peek(i -> System.out.println(i + ". map"))
.forEach(i -> { });
Mindkét sor kimenete:
1. map 2. map 3. map 4. map 5. map
Csakhogy nem mindig ez a helyzet! Az optimalizáció ugyanis implementációfüggő és általánosságban mégiscsak bölcsebb ha előbb szűrünk és aztán mappelünk, nem hagyunk mindent az implementációra. Java 8 esetén például a flatMap éppenséggel nem is lusta kiértékelésű. Tekintsük a következő példát:
System.out.println("Limit a végén:"); Stream.iterate(0, i -> i + 1) .flatMap(i -> Stream.of(i, i)) .peek(i -> System.out.println(i + ". map")) .limit(5) .forEach(i -> { }); System.out.println("Limit a közepén:"); Stream.iterate(0, i -> i + 1) .flatMap(i -> Stream.of(i, i)) .limit(5) .peek(i -> System.out.println(i + ". map")) .forEach(i -> { });
A két végtelen stream minden elemét kettővé "lapítjuk", majd kiíratjuk. A két példának elvben ugyanolyan kimenete kellene legyen, mégsem ez a helyzet:
Limit a végén: 0. map 0. map 1. map 1. map 2. map 2. map Limit a közepén: 0. map 0. map 1. map 1. map 2. map
Az első csővezeték rá se hederít a limitre és mind a hat elemet kiírja, a második viszont már csak ötöt. A flatMap a lezáró művelet végrehajtásakor ugyanis mohón feldolgozza a forrást és mindig legenerálja az összes értéket a következő műveletnek. Vagyis ha nem (mondjuk a fenti példában) két elemű hanem végtelen stream-et generálunk benne, akkor kellemetlen meglepetést okoz. Ez még lefut:
Stream.of("").map(x -> Stream.iterate(0, i -> i + 1)).findFirst();
Ez viszont már végtelen ciklusba kerül:
Stream.of("").flatMap(x -> Stream.iterate(0, i -> i + 1)).findFirst();
Ezt a viselkedést egyébként végül hibának találták és a Java 10-ben már kijavították.
Stream-eket össze is lehet fűzni. Persze nem gyöngyöt fűzünk belőlük, hanem újabb streameket. Erre szolgál a Stream osztály statikus concat metódusa:
Stream<String> stream1 = Stream.of("sárga ", "bögre "); Stream<String> stream2 = Stream.of("görbe ", "bögre "); Stream.concat(stream1, stream2).forEachOrdered(System.out::print);
A kód kimenete:
sárga bögre görbe bögre
A művelet a primitív típusú stream-ek esetén is rendelkezésre áll:
IntStream stream1 = IntStream.of(10, 9, 8, 7, 6, 5); IntStream stream2 = IntStream.of(4, 3, 2, 1, 0); IntStream fuzer = IntStream.concat(stream1, stream2);
A fuzer elemei: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
A concat egy lustán összefűzött streamet állít elő a paraméterként megadott két azonos típusú stream-ből. Az új streamben az első paraméter stream elemei vannak, ezeket követik a második stream elemei. Az eredmény stream rendezett, ha mindkét bemeneti stream rendezett és párhuzamos ha bármely bemeneti stream párhuzamos. Amikor a concat eredmény stream-jét lezárják, mindkét bemeneti stream close handler-jei is meghívódnak. A művelet asszociatív és egymásba ágyazható:
Stream<String> fuzer1 = Stream.concat(stream1, Stream.concat(stream2, stream3)); Stream<String> fuzer2 = Stream.concat(Stream.concat(stream1, stream2), stream3);
A fuzer1 és fuzer2 eredménye ugyanaz lesz. Vigyázzunk azonban a stream-ek ismételt összefűzésével. Mélyen összefűzött stream egy elemének elérése mély hívási láncon keresztül történhet és akár StackOverflowException-t is kaphatunk.
Természetesen a stream műveleteket már egyszerűen a concat paraméterlistájában is megadhatjuk, hiszen azoknak is stream a visszatérési értékük. Az alábbi példa összefűzi a CASTLE és a STARWARS témájú készleteinket egy stream-be:
Stream<LegoSet> sets = Stream.concat(
mySets
.stream()
.filter(set -> set.getTheme() == Theme.CASTLE),
mySets
.stream()
.filter(set -> set.getTheme() == Theme.STARWARS));
Az összefűzést egyébként a Stream.of() metódussal is megtehetjük, de ebben az esetben a végeredmény stream-ek stream-je, tehát használnunk kell még a flatMap műveletet:
Stream<LegoSet> sets = Stream.of(
mySets
.stream()
.filter(set -> set.getTheme() == Theme.CASTLE),
mySets
.stream()
.filter(set -> set.getTheme() == Theme.STARWARS))
.flatMap(x -> x);
A lusta kiértékelésnek köszönhetően akár végtelen stream-eket is összefűzhetünk, csak itt is arra kell figyelni, hogy a létrejövő pipeline-ban valahol legyen egy rövidzár művelet.
A tipikus I/O műveletek, mint például szöveges állomány soronkénti olvasása vagy írása is jó pályázó a stream feldolgozás kihasználására. (Ne keverjük össze a Java 8 új stream fogalmát a már korábban létező stream fogalommal, pl. InputStream, OutputStream! A kettőnek nincs köze egymáshoz.) A Java 8-ban a fájlfeldolgozás kiegészült stream-támogatással és innentől kezdve bármely stream-bűvészkedésünket fájlokkal is megcsinálhatjuk.
De még mielőtt bűvészkednénk! Talán eddig még fel se tűnt (nekem legalábbis nem), hogy a java.util.stream.Stream őse, a java.util.stream.BaseStream interfész az AutoCloseable leszármazottja. Ez már a Java 7-ből is ismerős fogalom, a try-with-resource vezérlési szerkezettel jelent meg. A Java 7 API ezt írja róla: "Olyan erőforrás amit be kell zárni miután már nincs rá szükség." Ezt teszi meg automatikusan a try-with-resource. De ha ebből származik a Stream, akkor ez csak nem azt akarja jelenteni, hogy eddig az összes példánál rosszul használtuk és minden esetben minimum try-with-resource szerkezetbe kellene írni (vagy külön lezárni)? Szerencsére nem ilyen rossz a helyzet. Az AutoCloseable Java 8-as dokumentációja ugyanis már sokkal megengedőbb: "Egy objektum, ami foglalhat erőforrásokat (mint például fájl vagy socket), amíg be nem zárják." Tehát nem be kell zárni hanem csak foglalhat is akár. A dokumentáció nem sokkal ezt követően egy érdekes megjegyzést is hozzáfűz: "Elképzelhető, sőt ami azt illeti eléggé általános, hogy egy ősosztály implementálja az AutoCloseable interfészt még akkor is ha nem is minden leszármazottja vagy példánya fog tárolni felszabadítható erőforrásokat. Ha olyan kódról van szó aminek teljes általánosságban kell működnie, vagy amikor ismert, hogy az AutoCloseable példánynak fel kell szabadítania erőforrást, akkor ajánlatos a try-with-resource használata. Amikor viszont olyan dolgot használunk mint a java.util.stream.Stream, ami I/O alapú és nem I/O alapú műveleteket is támogat, akkor a try-with-resource blokkok a nem-I/O alapú esetekben általában szükségtelenek."
Megváltoztatták tehát az AutoCloseable specifikációját, mégpedig pont azért, hogy illeszkedjen a streamek használati eseteihez. A döntést egyébként kiterjedt viták előzték meg a Java 8 fejlesztése közben. Brian Goetz az OpenJDK levelező listájára küldött egyik levelében ki is fejtette hogy milyen megoldási kísérleteik voltak és miért ezt választották végül. (Régebbi Eclipse verziók még warningot is jeleztek minden egyes Stream használatkor, ezért az újabb Eclipse-ekben módosítani kelett a kódellenőrzőt az új specifikációnak megfelelően.)
Szóval a specifikáció alapján általánosságban elmondható, hogy az I/O stream-eket expliciten le kell zárni a használat után, a többit meg nem. Persze ez a döntés sem oldott meg mindent. Mert - teszem azt - mi van ha olyan metódust írunk ami Stream paramétert fogad vagy ami Stream típusú értékkel tér vissza? Kinek a felelőssége a stream lezárása, ha egyáltalán le kell zárni? Nos erre a Java 8 nem ad általános érvényű választ. Jelezhetjük külön a javadocban, hogy olyan I/O streamet adunk vissza amit le kell zárni használat után. Vagy hogy a paraméterként kapott stream lezárása a hívó felelőssége. Ha mi gyártjuk a streamet, akkor lehet akár már a metódus nevében is jelezni, hogy mi a helyzet. Lezárandó stream-eket létrehozó metódus legyen például openStream(), lezárást nem igénylőt pedig createStream(). Bárhogy is, a fejlesztő felelőssége, hogy valamilyen konzisztens megoldást eszeljen ki.
Lezárás
A java.util.stream.BaseStream foglalkozik a lezárás definíciójával, a java.util.stream.Stream ettől örökli az alábbi két metódust:
close(): lezárja a stream-et és minden hozzáadott closeHandler-t meghív. Általánosságban csak az I/O csatorna forrással rendelkező streameknek van szüksége lezárásra (például amit a Files.lines(Path path, Charset cs) ad vissza). A legtöbb stream forrása collection, tömb vagy generáló függvény, ezeknek nincs szükségük speciális erőforráskezelésre. Ha a streamnek szüksége van lezárásra, akkor azt egy try-with-resource kifejezésben is megadhatjuk. A flatMap esetén láttuk, hogy a mapper Function különálló stream-eket állít elő, de ezeket a flatMap automatikusan egyenként lezárja miután összefűzte kimeneti streammé.
onClose(Runnable closeHandler): visszaad egy új streamet amihez hozzáadta a paraméter closeHandler-t. A closeHandler-ek akkor futnak le amikor a close() meghívódik a streamen és abban a sorrendben, ahogyan a streamhez lettek adva. Ha a sorban valamelyik kivételt dob, a többi attól még lefut. Ha több is dob kivételt, azok az első kivételhez lesznek hozzáfűzve. Példa:
package hu.egalizer.java8; import java.util.stream.IntStream; public class CloseTest { public static void main(String[] args) { try (IntStream is = IntStream.range(0, 10)) { is.onClose(() -> System.out.println("Close 1!")) .onClose(() -> generateException("Exception 1")) .onClose(() -> generateException("Exception 2")) .onClose(() -> System.out.println("Close 2!")) .forEach(System.out::println); } catch (TestException ex) { ex.printStackTrace(); } } public static void generateException(String num) throws TestException { throw new TestException(num); } static class TestException extends RuntimeException { public TestException(String message) { super(message); } } }
A példa mind a négy closeHandler-t meghívja, a sikeresek eredménye megjelenik, majd a két összefűzött kivétel is a kimeneten a kivételkezelő ex.printStackTrace(); sorának köszönhetően:
0
1
...
9
Close 1!
Close 2!
hu.egalizer.java8.CloseTest$TestException: Exception 1
at hu.egalizer.java8.CloseTest.generateException(CloseTest.java:17)
...
Suppressed: hu.egalizer.java8.CloseTest$TestException: Exception 2
at hu.egalizer.java8.CloseTest.generateException(CloseTest.java:17)
...
Files
Az I/O streamek kiindulópontja a java.nio.file.Files osztály, ami 4 stream-létrehozó metódust kapott.
walk(Path start, int maxDepth, FileVisitOption... options): visszaad egy Path streamet ami mélységi bejárással (depth-first) végiglépeget a start elérési útjából kiinduló könyvtárakon. A visszaadott streamnek legalább egy eleme mindenképpen lesz: a startként megadott fájl/könyvtár. A stream minden egyes bejárt fájlnál megpróbálja beolvasni a hozzá tartozó BasicFileAttributes objektumot. Ha egy könyvtárról van szó és sikeresen megnyitható, akkor a könyvtár bejegyzései és azok leszármazottai következnek a bejárás során. Amikor minden bejegyzés meg lett vizsgálva, a könyvtár bezáródik. A szimbolikus linkeket a metódus csak akkor járja be, ha az options paraméter tartalmazza a FileVisitOption.FOLLOW_LINKS opciót. Ha a linkek során hurkot talál akkor egy FileSystemLoopException kivétel dobódik. A maxDepth paraméter a bejárandó könyvtárszintek maximális mélységét adja meg. 0 azt mutatja, hogy csak a kiindulási fájlt szeretnénk bejárni. Minden szint bejárásához hívjuk meg Integer.MAX_VALUE-val (a walk-nak létezik egy másik változata is ahol a maxDepth paramétert nem kell megadni, automatikusan így hívódik). A jogosultság miatt nem olvasható fájlokat a stream átugorja.
A példákhoz a 8-as JDK forrásának könyvtárszerkezetét használtam fel, abból csak a jobb oldali ábrán lévőket meghagyva. A könyvtárszerkezet bejárása:
Path path = Paths.get("F:", "jdk_8_05_src"); try (Stream<Path> stream = Files.walk(path)) { stream.forEach(System.out::println); } catch (IOException | UncheckedIOException ioe) { // TODO kivétel feldolgozása }
Ha csak a könyvtárakat szeretnénk bejárni a fájlok nélkül, akkor:
stream.filter(path1 -> path1.toFile().isDirectory()).forEach(System.out::println);
find(Path start, int maxDepth, BiPredicate<Path,BasicFileAttributes> matcher, FileVisitOption... options): visszaad egy streamet ami a start paraméter által megadott fájl könyvtárában kezd el keresni és onnan kiindulva bejárja a teljes könyvtárszerkezetet a kívánt fájlok után kutatva. A metódus pont úgy járja be a könyvtárszerkezetet mint a walk. Minden megtalált fájlra lefut a megadott BiPredicate matcher annak a Path és BasicFileAttributes objektumával. A Path objektum az eredmény streamben az abszolút elérési utat tartalmazza és csak akkor szerepel, ha a BiPredicate true értékkel tér vissza. A működését a walk metódus és a filter közbülső művelettel is lehet reprodukálni, de a find hatékonyabb lehet, mert elkerülhető vele a BasicFileAttributes redundáns megszerzése.
Az alábbi stream csak azokat a fájlokat dolgozza fel amelyek neve "Exception.java"-ra végződik:
Path path = Paths.get("F:", "jdk_8_05_src"); try (Stream<Path> stream = Files.find(path, Integer.MAX_VALUE, (actualPath, attributes) -> actualPath.toFile().isFile() && actualPath.toFile().getName().endsWith("Exception.java"))) { stream.forEach(System.out::println); } catch (IOException | UncheckedIOException ioe) { // TODO kivétel feldolgozása }
A példa kimenete:
F:\jdk_8_05_src\java\lang\annotation\AnnotationTypeMismatchException.java F:\jdk_8_05_src\java\lang\NullPointerException.java
list(Path dir): a paraméterként megadott könyvtár elemeinek streamjét adja vissza. A metódus nem rekurzív, tehát csak abban az egy könyvtárban dolgozik (értelemszerűen a "." és ".." könyvtárakat sem dolgozza fel). Ha csak egy könyvtárat szeretnénk feldolgozni akkor a fenti két metódus helyett ezt célszerű használni.
Az alábbi példa a list.txt fájlba kiírja az F:\jdk_8_05_src\java\lang könyvtárban lévő összes fájl nevét:
Path path = Paths.get("F:", "jdk_8_05_src\\java\\lang"); try (PrintWriter pw = new PrintWriter( Files.newBufferedWriter(Paths.get("F:", "jdk_8_05_src\\list.txt")))) { Stream<Path> stream = Files.list(path); stream.filter(path1 -> path1.toFile().isFile()).forEach(pw::println); stream.close(); } catch (IOException | UncheckedIOException ioe) { // TODO kivétel feldolgozása }
Mindhárom fenti metódusra vonatkozik, hogy egyik sem foglalja le a könyvtárszerkezetet a bejárás során, tehát visszaadhatják a metódusból való visszatérés (vagyis a stream visszaadása) után bekövetkezett fájlrendszer módosításokat is (a JDK ezt gyengén konzisztensnek - weakly consistent - hívja).
lines(Path path, Charset cs): soronként beolvasssa a megadott fájlt a megadott karakterkészlettel. A beolvasás itt is lusta feldolgozással működik, tehát mindig csak a következő sor olvasódik be, nem egyszerre az egész fájl. A metódusnak egyszerűsített lines(Path path) változata ugyanezt csinálja, csak dedikáltan UTF-8 kódolást használva.
Az alábbi példa kiírja a Long.java tartalmát majd amikor végzett, akkor üzenetet is küld erről:
Path path = Paths.get("F:", "jdk_8_05_src\\java\\lang\\Long.java"); try (Stream<String> stream = Files.lines(path)) { stream.onClose(() -> System.out.println("Kész vagyok!")).forEach(System.out::println); } catch (IOException | UncheckedIOException ioe) { // TODO kivétel feldolgozása }
A lines lusta feldolgozása azért is hasznos, mert ha például egy nagy szöveges fájlnak csak az első 10 sorát szeretnénk beolvasni, akkor nem kell az egész fájlt beolvasni előtte, hanem a már ismerős stream műveletekkel egyszerűen és hatékonyan korlátozhatjuk a beolvasást az első 10 sorra.
Minden fenti metódusnál ha IOException dobódik a metódus által visszaadott csővezeték feldolgozása közben akkor az egy UncheckedIOException kivételbe burkolva dobódik tovább a használó felé (ennek okáról később). Ha pedig a fájlrendszer erőforrásainak felszabadítása szükséges, akkor minden esetben a close meghívása vagy a try-with-resources szerkezet használata ajánlatos.
JarFile, ZipFile
A java.util.jar.JarFile jar fájlok feldolgozására szolgáló osztály is kapott egy stream() metódust ami a jar fájl bejegyzéseit adja vissza:
JarFile jarFile = new JarFile(new File("C:\\Program Files\\Java\\jre1.8.0_162\\lib\\rt.jar")); jarFile.stream().forEach((entry) -> System.out.println(entry.getName())); jarFile.close();
Majdnem pont ugyanezt tudja a java.util.zip.ZipFile csak dedikáltan tömörített ZIP fájlokra.
Az eddigi példákban szinte minden közbülső műveletet megismertünk, a stream-ek eredménye viszont majdnem mindig a konzolra került. A stream-ek így még nem lennének túl használhatók, de szerencsére nem csak forEach lezáró műveletből áll a világ. A lezáró műveletek nagyfejezetéhez bevezetésül egy példa: az alábbi kifejezés kiszámolja az összes, mySets collection-ben tárolt 2000 előtt kiadott legókészlet átlagos elemszámát egy filter, mapToInt közbülső és average aggregáló műveletet tartalmazó pipeline-al:
mySets.stream()
.filter(set -> set.getYearReleased() < 2000)
.mapToInt(LegoSet::getPieceCount)
.average()
.getAsDouble();
A filter visszaad egy stream-et ami az összes 2000 előtti legókészletet tartalmazza a mySets collection-ből. A mapToInt műveletet már ismerjük, ez visszaad egy új IntSteam-et. Ez a metódus a bemenő stream minden egyes elemére alkalmazza a paraméterként átadott, int-et előállító műveletet. A példában ez a LegoSet::getPieceCount metódusreferencia, ami visszaadja az adott legókészlet elemszámát. (Persze ehelyett akár az e -> e.getPieceCount() lambda kifejezést is használhatnánk.) Az average művelet kiszámolja az IntStream típusú stream-ben lévő elemek átlagértékét és egy OptionalDouble-t ad vissza. Az Optional fejezetben megismerteknek megfelelően amennyiben a stream-ben nincsenek elemek, akkor az average művelet egy "empty" OptionalDouble-lel tér vissza (ilyenkor a getAsDouble meghívása NoSuchElementException-t dob). Az API sok ilyen lezáró műveletet tartalmaz, ami a stream elemeiből kiszámít egy értéket és visszaadja.
Azokat a lezáró műveleteket, amelyek valamilyen értéket vagy collection-t adnak vissza (average, sum, min, max, count) redukciós műveleteknek (reduction operation) nevezzük. Ezek valamilyen egyszerű műveletet valósítanak meg, ami már a nevükből is kikövetkeztethető:
További egyszerű redukciós műveletek:
findAny(): egy Optional objektumot ad vissza ami a stream valamely elemét tartalmazza vagy üres ha a stream is. A művelet viselkedése nemdeterminisztikus; mind soros mind párhuzamos stream bármely elemét visszaadhatja. Ez egy rövidzár művelet tehát végtelen stream esetén is véges idő alatt végez a csővezeték feldolgozásával. A következő példa visszaadja a legóadatbázisunk bármely 2000 elemnél nagyobb készletét, ha van olyan:
Optional<LegoSet> result = mySets.stream().filter(e -> e.getPieceCount() > 2000).findAny(); result.ifPresent(System.out::println);
findFirst(): egy Optional objektumot ad vissza, ami a stream első elemét tartalmazza vagy üres ha a stream is. Ha a streamnek nincs encounter orderje akkor bármely elemét visszaadhatja. Rövidzár művelet.
anyMatch(Predicate<? super T> predicate): megmondja, hogy a stream valamely eleme megfelel-e a megadott predikátumnak (üres stream esetén false a visszatérési érték). Nem elemzi végig a stream összes elemét ha nem szükséges az eredmény megállapításához, éppen ezért ez is rövidzár művelet.
allMatch(Predicate<? super T> predicate): megmondja, hogy a stream összes eleme megfelel-e a megadott predikátumnak (üres stream esetén true). Nem feltétlenül vizsgálja meg a stream összes elemét, ha nem szükséges az eredmény meghatározásához. Rövidzár művelet.
noneMatch(Predicate<? super T> predicate): true, ha a stream egyetlen eleme sem felel-e meg a megadott predikátumnak (üres stream esetén true). Nem feltétlenül vizsgálja végig a stream összes elemét, ha nem szükséges az eredmény meghatározásához. Rövidzár művelet.
Ez már mind nagyon szép és jó, de még nincs vége az izgalmaknak! Léteznek általános célú redukciós műveletek is: a reduce és a collect.
Stream.reduce
A következő pipeline a Stream.sum redukciós művelettel kiszámolja az összes készlet elemszámának összegét:
mySets.stream()
.mapToInt(LegoSet::getPieceCount)
.sum()
Ez viszont a Stream.reduce redukciós műveletet használja ugyanerre:
mySets.stream()
.map(LegoSet::getPieceCount)
.reduce(0, (a, b) -> a + b)
A fenti példában a redukciós művelet két paramétert vár:
T reduce(T identity, BinaryOperator<T> accumulator)
A reduce-nak létezik három paraméteres változata is:
<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
Ez egy combiner paraméterrel egészült ki, ami két részeredményből állít elő egy újat. Ez különösen párhuzamos redukció esetén fontos. Ott ugyanis a forrást a keretrendszer particionálja, minden partícióra elvégződik egy részleges akkumuláció majd a részeredményeket végeredménnyé kell egyesíteni. Ezt végzi a combiner. A combinernek asszociatívnak, interferencia- és állapotmentesnek kell lennie. Az identity elem a combiner számára mindig kezdeti értéket kell jelentsen, vagyis minden u-ra:
combiner(identity, u)=u
Persze a combiner függvénynek kompatibilisnek kell lenni az accumulatorral is vagyis minden u-ra és t-re:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
A három paraméteres általános reduce művelettel a készletek elemszám-összegző műveletét általánosabb formában így is írhatjuk:
mySets.stream().reduce(0, (sum, b) -> sum + b.getPieceCount(), Integer::sum)
Ebben a formában a map nem szükséges, bár a map-et használó forma általában jobban olvasható, ezért azt ajánlatos használni, kivéve ha a map és a reduce művelet összefűzésével jelentős optimalizáció érhető el.
A reduce művelet végeredményként mindig egy új értéket ad vissza. Ugyanezt teszi az accumulator függvény is: minden egyes alkalommal, amikor a stream egy elemét feldolgozza, új értéket ad vissza. Tegyük fel, hogy redukálni szeretnénk egy stream elemeit egy összetettebb objektummá, mint például egy collection. Ha a reduce műveletünk egy collection-höz való hozzáadást végez, akkor minden egyes alkalommal amikor az accumulator függvény feldolgoz egy elemet, egy új collection-t hozna létre ami nem valami hatékony. Sokkal hatékonyabb lenne egy már létező collection-t bővíteni. Erre való a Stream.collect metódus.
Matematikából bizonyára ismerős fogalom. Egy op operátor vagy függvény asszociatív ha igaz rá a következő állítás:
(a op b) op c == a op (b op c)
Ennek a jelentősége különösen párhuzamos végrehajtásnál jelentkezik, amit akkor láthatunk, ha a fenti állítást négy operandusra kiterjesztjük:
a op b op c op d == (a op b) op (c op d)
Így az (a op b) és (c op d) kifejezést párhuzamosan is kiértékelhetjük, aztán az eredményeken újra meghívjuk az op operátort. Asszociatív operátor például a numerikus összeadás, min, max és a sztring összefűzés.
A stream-ek lehetővé teszik párhuzamos végrehajtású aggregáló műveletek futtatását még olyan nem szálbiztos collection-ök esetén is mint az ArrayList. De ez csak úgy lehetséges, ha a csővezeték futtatása során meg tudjuk gátolni az interferenciát, vagyis azt, hogy a szálak zavarják egymást az adatforráson keresztül. Az iterator() és spliterator() műveletek kivételével a végrehajtás akkor kezdődik amikor a lezáró műveletet meghívják és akkor fejeződik be amikor a lezáró művelet befejeződik. A legtöbb adatforrásnál az interferencia meggátolása azt jelenti, hogy biztosítani kell, hogy az adatforrás nem változik a stream csővezeték végrehajtása során. Egyetlen fontos kivétel az olyan stream-ek amelyek forrásai a konkurens collection-ök, mert ezeket kifejezetten arra tervezték, hogy a konkurens módosítást kezeljék. A konkurens stream forrásoknál az spliterator CONCURRENT karakterisztikát jelez.
A következő kód megpróbálja egy redukciós lezáró művelettel összefűzni a stringList List-ben lévő sztringeket egy Optional<String> értékké, de ehelyett ConcurrentModificationException-t dob (a peek közbülső művelet egy olyan stream-et állít elő, ami a forás elemeit tartalmazza úgy, hogy a stream kiértékelése során minden egyes elemre végrehajtja a paraméterként megadott függvényt):
List<String> stringList = new ArrayList<>(Arrays.asList("egy", "kettő")); String concatenated = stringList.stream() .peek(s -> stringList.add("három")) .reduce((a, b) -> a + " " + b) .get(); System.out.println("Összefűzött sztring: " + concatenated);
A csővezeték meghívja a peek közbülső műveletet, ami megpróbál új elemet hozzáadni a stringList-hez. De mi már tudjuk, hogy a peek - mint minden közbülső művelet - lusta kiértékelésű. A példában lévő csővezeték akkor kezdi a végrehajtást, amikor a get művelet meghívódik és akkor fejezi be amikor a get végetér. A peek paramétere megpróbálja módosítani a stream forrását végrehajtás közben, így a futtatókörnyezet ConcurrentModificationException-t dob. Olyan viselkedési paraméterek tehát, amelyek forrása feltehetően nem konkurens, stream csővezetékben soha ne módosítsák a stream adatforrását! Egy viselkedési paraméter akkor okoz zavart nemkonkurens stream-forrásban, ha közvetlenül vagy közvetetten módosítja azt. Az interferencia-mentesség követelménye nem csak a párhuzamos, hanem minden csővezetékre igaz. Hacsak nem konkurens a stream forrása, akkor annak a csővezeték végrehajtása közbeni módosítása kivételeket, helytelen eredményt vagy nem megfelelő működést okozhat.
Megfelelő tervezésnél a forrás még a lezáró művelet megkezdése előtt módosul és ezek a módosítások meg is jelennek a feldolgozandó elemekben. Tekintsük a következő kódot:
List<String> list = new ArrayList(Arrays.asList("egy", "kettő")); Stream<String> str = list.stream(); list.add("három"); String result = str.collect(Collectors.joining(", "));
Először létrejön egy két sztringből álló lista, amiből aztán egy stream képződik, majd a listához hozzáadódik egy harmadik sztring. Ezután a stream elemeire meghívódik a collect lezáró művelet. Mivel a lista még a collect művelet előtt módosult, az eredmény nem egy kivétel, hanem "egy, kettő, három" lesz.
A stream csővezetékek eredménye nemdeterminisztikus vagy hibás lehet, ha a stream műveleteknek megadott viselkedési paraméterek állapottárolók. Egy állapottároló lambda (vagy a megfelelő funkcionális interfészt implementáló objektum) eredménye függ bármely belső állapottól ami megváltozhat a stream csővezeték végrehajtása során. Egy állapottároló lambda a map() paramétereként:
Set<Integer> seen = Collections.synchronizedSet(new HashSet<>()); stream.parallel().map(e -> { if (seen.add(e)) return 0; else return e; });
Ha itt a map művelet párhuzamosan fut, akkor az eredmény futásról futásra változhat ugyanarra a bemenetre szálütemezési eltérések miatt. Állapotmentes lambda kifejezéssel az eredmény mindig ugyanaz marad. Biztonság és teljesítmény szempontjából elég rossz módszer viselkedési paraméterekből valamely módosítható belső állapot elérése. Ha az adott állatpottároló mezőhöz nem szinkronizáljuk az elérést, akkor hibás működést kaphatunk, ha viszont szinkronizáljuk, az rossz hatással lehet a teljesítményre. A legjobb, ha stream műveleteknél teljesen elkerüljük az állapottároló viselkedési paramétereket.
Stream.collect
A reduce metódustól eltérően, ami egy elem feldolgozásakor mindig új értéket hoz létre, a collect egy már létező változót módosít, ezért is hívják mutable reduction-nek. Nézzük például, hogy tudjuk egy stream-ben értékek átlagát meghatározni! Két adatra van szükség: az értékek összegére és az értékek számára. De akárcsak a reduce és az összes többi redukciós metódus, a collect is csak egy értéket ad vissza. Segítségként létre lehet hozni egy új adattípust ami tartalmaz tagváltozókat az értékek számához és összegéhez. Ilyen például a következő AverageCollector osztály:
package hu.egalizer.java8.lego; import java.util.function.IntConsumer; public class AverageCollector implements IntConsumer { private int total = 0; private int count = 0; public double average() { return count > 0 ? ((double) total) / count : 0; } public void accept(int i) { total += i; count++; } public void combine(AverageCollector other) { total += other.total; count += other.count; } }
Az alábbi pipeline ezt az osztályt használva a collect metódussal kiszámolja az összes 2000 előtt kiadott készlet átlagát:
AverageCollector averageCollect = mySets.stream()
.filter(p -> p.getYearReleased() < 2000)
.map(LegoSet::getPieceCount)
.collect(AverageCollector::new, AverageCollector::accept, AverageCollector::combine);
System.out.println("2000 előtt kiadott készletek átlagos elemszáma: " +
averageCollect.average());
A collect három paraméteres változata:
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
Akárcsak a reduce, a collect metódus absztrakt szerkezete is előnyös a párhuzamosítás során: párhuzamosan össze lehet gyűjteni a részeredményeket, aztán egyesíteni lehet ezeket, legalábbis ha a accumulator és combiner függvények megfelelnek a követelményeknek. Egy stream forrás elemeinek sztring reprezentációit így is összegyűjthetjük egy ArrayList-be:
List<String> strings = new ArrayList<>();
for (T element : sourceCollection) {
strings.add(element.toString());
}
De használhatjuk a párhuzamosítható collect metódust is:
List<String> strings = sourceCollection.stream()
.collect(() -> new ArrayList<>(), (c, e) -> c.add(e.toString()), (c1, c2) -> c1.addAll(c2));
De ha még menőbbek akarunk lenni, kivehetjük az accumulator függvényből a leképező műveletet és sokkal tömörebben így is kifejezhetjük:
List<String> strings = sourceCollection.stream()
.map(Object::toString)
.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
Itt a supplier egyszerűen az ArrayList konstruktora, az akkumulátor hozzáadja a sztringesített elemet az ArrayList-hez, a combiner pedig egyszerűen az addAll-t használja, hogy átmásoljon sztringeket egyik konténerből a másikba.
Vegyük észre, hogy a collect három függvénye szorosan kapcsolódik egymáshoz. Ezt a Java tervezői is észrevették, ezért a három aspektus egységbe zárására kitalálták a Collector absztrakciót. A collect-ből pedig írtak egy másik változatot is, ami egyetlen Collector paramétert vár:
<R,A> R collect(Collector<? super T,A,R> collector)
Egy Collector lehetővé teszi, hogy újrahasznosítsunk collection stratégiákat és hogy összeállítsunk olyan collect műveleteket, mint többszintű csoportosítás vagy particionálás. A JDK sok előre megírt hasznos Collector-t tartalmaz a java.util.stream.Collectors osztályban, érdemes ezeket áttanulmányozni, hátha pont olyan is van bennük amire épp szükségünk van.
Egy Collector példányra referenciát a következőképp tárolhatunk:
Collector<LegoSet, ?, Integer> totalPieceCount = Collectors.summingInt(LegoSet::getPieceCount);
A ? a második típusparaméter helyén azt jelenti, hogy nem érdekel minket a collector által használt közbülső reprezentáció. Néhány Collectors-t használó példa:
// A gyűjteményben lévő készletek neveinek kigyűjtése listába List<String> setNames = mySets.stream().map(LegoSet::getName).collect(Collectors.toList()); // A gyűjteményben lévő készletek neveiből egy sztring összeállítása vesszővel elválasztva String allSetNames = mySets.stream().map(LegoSet::getName).collect(Collectors.joining(", ")); // A gyűjtemény összes elemszámának meghatározása int total = mySets.stream().collect(Collectors.summingInt(LegoSet::getPieceCount));
A groupingBy művelet visszaad egy map-et, aminek a kulcsai a metódus paramétereként átadott kifejezés kiértékeléséből származó értékek lesznek (ezt osztályozási függvénynek - classification function - hívják). A legónyilvántartó programunk tartalmaz egy Theme enumot, ami azt tartalmazza, a készletek milyen témakörökhöz tartozhatnak:
package hu.egalizer.java8.lego; public enum Theme { CASTLE, TOWN, TECHNIC, STARWARS, PIRATES, ADVANCED_MODELS, }
Az alábbi példában a visszaadott map az enum 7 értékét tartalmazza és ezt ki is írja:
Map<Theme, List<LegoSet>> byTheme = mySets.stream()
.collect(Collectors.groupingBy(LegoSet::getTheme));
byTheme.keySet().forEach(System.out::println);
A kód eredménye:
TOWN ADVANCED_MODELS IDEAS STARWARS CASTLE
A kulcshoz tartozó értékek List példányok, amelyek a stream azon elemeit tartalmazzák, amelyek az osztályozási függvény végrehajtása során megfeleltek az adott kulcs értéknek. További, csoportosítást használó példák:
// A gyűjtemény csoportosítása téma szerint Map<Theme, List<LegoSet>> byTheme = mySets.stream() .collect(Collectors.groupingBy(LegoSet::getTheme)); // Téma szerinti összes elemszám meghatározása Map<Theme, Integer> sumByTheme = mySets.stream() .collect(Collectors.groupingBy(LegoSet::getTheme, Collectors.summingInt(LegoSet::getPieceCount))); // Particionális: a 2000 elemnél nagyobb és 2000 elemes vagy annál kisebb elemszámú készletek // szétválasztása. Az eredmény Map kulcsa a feltétel teljesülése vagy nem teljesülése. Map<Boolean, List<LegoSet>> partitionBy2000Pieces = mySets .stream().collect(Collectors.partitioningBy(set -> set.getPieceCount() > 2000));
A következő példa a gyűjtemény minden elemének nevét kigyűjti és téma szerint csoportosítja:
Map<Theme, List<String>> namesByTheme = mySets.stream()
.collect(Collectors.groupingBy(LegoSet::getTheme,
Collectors.mapping(LegoSet::getName, Collectors.toList())));
Ez a groupingBy művelet két paramétert vár: egy osztályozási függvényt és egy Collector példányt.
static <T,K,A,D> Collector<T,?,Map<K,D>> groupingBy(Function<? super T,? extends K> classifier, Collector<? super T,A,D> downstream)
A Collector paramétert downstream collector-nak hívják. Ez egy olyan collector amit a JVM egy másik collector eredményére alkalmaz. Ennek eredményeképp a groupingBy művelet lehetővé teszi, hogy egy collect metódust alkalmazzunk a groupingBy operátor eredményeként előállt List értékeire. Ez a példa a mapping collector-t használja, ami a LegoSet::getName mapping függvényt alkalmazza a stream minden egyes elemére. Ennek megfelelően az eredmény stream csak a tagok nevét tartalmazza. Egy olyan csővezetéket ami egy vagy több downstream collector-t használ, mint a példában is, multilevel reduction-nek hívnak.
A következő példa minden egyes téma tagjainak összesített elemszámát adja vissza a fentebbi, Collectors.summingInt megoldástól eltérő módszert használva:
Map<Theme, Integer> sumByTheme2 = mySets.stream()
.collect(Collectors.groupingBy(LegoSet::getTheme,
Collectors.reducing(0, LegoSet::getPieceCount, Integer::sum)));
A reducing művelet három paramétert vár:
static <T,U> Collector<T,?,U> reducing(U identity, Function<? super T,? extends U> mapper, BinaryOperator<U> op)
Láthatjuk, hogy bizonyos feladatokat a collect és a reduction metódusokkal egyaránt meg lehet oldani, de az egyes megoldások nem ekvivalensek teljesítmény tekintetében. Egy sztring-stream elemeit egyetlen hosszú sztringgé a reduce művelettel is össze tudjuk fűzni:
String concatenated = strings.reduce("", String::concat)
Ez is a kívánt eredményt adja, sőt még párhuzamosan is futtatható, de a teljesítményében nem fog sok örömünk telni! Ez az implementáció rengeteg sztringmásolást csinál, sokkal hatékonyabb a fentebb ismertetett, Collectors.joining()-et használó megoldás.
A Collectors.toMap segítségével a collection elemeit Map-pé képezhetjük le. Ennek van egyébként egy furcsasága. Két Function funkcionális interfészt vár, az első a kulcs, a második az érték mapper-e. Ez önmagában még nem furcsaság, azonban ha az eredeti collection-ünk olyan értékeket tartalmaz, amelyekből a kulcs mapper kétszer képezi le ugyanazt, a collect metódus IllegalStateException-t fog dobni. Nyilvánvaló, hogy az eredmény map kétszer nem tartalmazhatja ugyanazt a kulcsot. A kivétel azonban az üzenetben nem a kulcsot, hanem az értéket fogja megjeleníteni, bár a szövege a kulcsra hivatkozik. Az alábbi példában a legó adatbázisunkhoz hozzáadunk egy készletet még egyszer (legalábbis ami a nevét és a témáját illeti) majd map-pé szeretnénk leképezni, ahol a kulcs a készlet neve, az érték pedig a témája:
LegoSet set = new LegoSet(); set.setName(mySets.get(0).getName());// a neve ugyanaz lesz mint a nulladik készletünké set.setTheme(Theme.ADVANCED_MODELS);// a témája lényegtelen, ez lesz az érték. A többi adata is lényegtelen a példa szempontjából. database.mySets.add(set); // Map-et képezünk, ahol a kulcs a név, az érték pedig a téma lesz: Map<String, Theme> eredmeny = mySets.stream().collect(Collectors.toMap(LegoSet::getName, LegoSet::getTheme));
Ha ezt lefuttatjuk, a következő kivételt kapjuk (azt mondja, hogy duplikálva van a kulcs, ami igaz is, csak aztán nem a kulcsot adja meg hanem az értéket ami lényegtelen):
Exception in thread "main" java.lang.IllegalStateException: Duplicate key ADVANCED_MODELS
A java.util.LongSummaryStatistics további egyszerű eszköz a collector használatához: számosságot, minimum, maximum és átlag értéket tudunk vele egyszerűen számítani. (Bár ezek a funkciók a primitív stream-ekben is benne vannak.)
Stream>Long< longStream;
...
LongSummaryStatistics statistics = longStream.collect(LongSummaryStatistics::new, LongSummaryStatistics::accept, LongSummaryStatistics::combine);
Ezután a statistics objektumból már lekérdezhetjük a kívánt eredményt a következő metódusokkal:
A LongSummaryStatistics redukciós eredményként is használható. A következő kódsor egy menetben összegzi legókészleteink elemszámát, minimális és maximális értékét, öszegét és átlagát.
LongSummaryStatistics statistics = mySets.stream().collect(Collectors.summarizingLong(LegoSet::getPieceCount));
Természetesen az osztálynak létezik DoubleSummaryStatistics és IntSummaryStatistics megfelelője is. (Ahogy a Collectors osztálnyak summarizingLong és summarizingDouble metódusa.)
Ezeket az osztályokat elsősorban stream-ekkel használjuk, de természtesen saját célra is használhatók, hiszen az accept(int value) metódusaal saját kezűleg is adhatunk neki értékeket. A combine(other) metódussal pedig azonos típusú ...SummaryStatistics objektumot tudunk hozzáfűzni.
A párhuzamos programozás - amint azt bizonyára mindenki tudja - a problémát részekre bontja, az alproblémákat pedig külön szálakon egymással párhuzamosan oldja meg, aztán az eredményeket összesíti. A Stream API aggregáló műveleteinél az osztálykönyvtár elvégzi nekünk ezt a részekre bontást (particionálást vagy másnéven felszeletelést), majd az aggreagáló műveletek az al-streameket párhuzamosan feldolgozzák és összesítik az eredményeket. A párhuzamosság implementálásánál az egyik nehézség, hogy a collection-ök általában nem szálbiztosak, tehát több szál büntetlenül nem módosíthatja egyszerre ugyanazt a collection-t. Az aggregáló műveletek és a párhuzamos stream-ek lehetővé teszik, hogy nem szálbiztos collection-ökkel is implementálhassunk párhuzamos feldolgozást, feltéve hogy nem módosítjuk a collection-t a feldolgozás közben. A párhuzamosság persze nem varázsszer, a párhuzamos feldolgozás nem lesz automatikusan gyorsabb mint egy soros. Az aggregáló műveletekkel egyszerűen kihasználhatjuk a párhuzamosságot, de továbbra is a kódoló felelőssége, hogy megvizsgálja, a feladat alkalmas-e párhuzamos feldolgozásra.
Streamek létrehozásához az API négyféle lehetőséget ad, ebből kettő soros, kettő pedig párhuzamos feldolgozású streamhez való:
Az isParallel() metódussal bármely stream-ről lekérdezhetjük, hogy lezáró művelet végrehajtásakor sorosan vagy párhuzamosan dolgozódna-e fel (de lezáró művelet végrehajtása után már eszünkbe ne jusson ezt megtenni, különben az API szerint megjósolhatatlan eredményt kapunk).
A fentiek alapján tehát streamből egy csővezetéken belül is csinálhatunk párhuzamosat vagy sorosat. Soros streamre már több példát is láttunk, a következő kifejezés az összes Castle készletünk átlagos elemszámát párhuzamos feldolgozással számolja ki:
double atlag = mySets.parallelStream()
.filter(s -> s.getTheme() == Theme.CASTLE)
.mapToInt(LegoSet::getPieceCount)
.average()
.getAsDouble();
A soros stream létrehozásban lényegében nincs különbség a fenti két metódus között, a Collection.parallelStream esetén azonban a Java 8 dokumentációja érdekesen fogalmaz: ez a metódus visszaadhat párhuzamos, de soros streamet is. A default implementáció párhuzamos stream-et kreál, akárcsak a Collection osztály JDK-beli leszármazottai is. A kitétel valószínűleg azért került bele a dokumentációba, mert technikailag legalábbis lehetséges olyan Collection leszármazottat gyártani, aminél a parallelStream soros steam-et hoz létre.
Nagyon sok redukciós művelet egyszerű ciklussal is implementálható, például:
int sum = 0; for (int x : numbers) { sum += x; }
Ilyen esetekben mégis célszerűbb redukciós műveletet használni, mert az általában jól párhuzamosítható, legalábbis amíg az elemek feldolgozására használt művelet asszociatív és állapotmentes. Számok stream-jének összegét a fenti helyett így is írhatjuk:
int sum = numbers.stream().reduce(0, (x, y) -> x + y);
vagy
int sum = numbers.stream().reduce(0, Integer::sum);
Ez pedig egy csuklómozdulattal párhuzamossá alakítható:
int sum = numbers.parallelStream().reduce(0, Integer::sum);
Konkurens redukció
Tekintsük a következő példát, ami a készleteinket témakör szerint csoportosítja (már a redukció fejezetben is láttuk). Ez a példa a collect művelettel Map-pé redukálja a legógyűjtemény collection-t:
Map<Theme, List<LegoSet>> byTheme = mySets.stream()
.collect(Collectors.groupingBy(LegoSet::getTheme));
A fenti példával ekvivalens párhuzamos feldolgozású változat:
Map<Theme, List<LegoSet>> byTheme = mySets.parallelStream()
.collect(Collectors.groupingByConcurrent(LegoSet::getTheme));
Ezt a népnyelv konkurens redukciónak (concurrent reduction) hívja. Az osztálykönyvtár akkor végez konkurens redukciót, ha egy collect műveletet tartalmazó csővezetéknél a következő feltételek mindegyike igaz:
Bizonyára mindenkinek feltűnt, hogy a fenti példa valójában egy ConcurrentMap példányt ad vissza, bár ha ez talán nem is, az biztosan, hogy a groupingByConcurrent műveletet hívja meg a groupingBy helyett. Nos, a groupingByConcurrent-től eltérően a groupingBy elég gyengén muzsikál a párhuzamos stream-ekkel. (Mert úgy működik, hogy két map-et a kulcsok alapján fésül össze, ami eléggé számításigényes.) A Collectors.toConcurrentMap is jobban működik párhuzamos stream-ekkel, mint a Collectors.toMap.
Van néhány összetett redukciós művelet, amit akár még hátrányosabb is lehet párhuzamosan futtatni. Ilyen például egy collect() ami Map-et hoz létre, mint például ez:
Map<Theme, List<LegoSet>> setsByTheme = mySets.parallelStream()
.collect(Collectors.groupingBy(LegoSet::getTheme));
Ez azért van mert az összesítő lépés (amikor két Map-et kulcs alapján összefűzünk) eléggé költséges lehet egyes Map implementációknál. Itt segít a konkurens redukció. Ha a redukcióban használt eredménykonténer konkurensen módosítható collection, mint például a ConcurrentHashMap, az akkumulátor párhuzamos meghívásai valóban betölthetik az eredményüket egyidejűleg ugyanabba a megosztott eredménykonténerbe. Így már nem lesz szükség rá, hogy a combiner különböző eredménykonténereket fűzzön össze és ez valóban felgyorsíthatja a párhuzamos végrehajtás teljesítményét. A konkurens redukciót támogató Collector Collector.Characteristics.CONCURRENT karakterisztikával van megjelölve (a karakterisztikákról később bővebben lesz szó).
A konkurens collection-nek is van hátránya: ha több szál rakosgatja eredményeit egyszerre ugyanabba a megosztott eredménykonténerbe, akkor az eredmények sorrendje nemdeterminisztikus lesz. Konkurens redukció tehát csak akkor használható, ha a feldolgozott stream sorrendje nem lényeges.
Összefoglalva: a Stream.collect(Collector<? super T,A,R> collector) csak akkor hajt végre konkurens redukciót, ha
A stream rendezetlenségét a már megismert BaseStream.unordered() metódussal tudjuk biztosítani. Például:
Map<Theme, List<LegoSet>> setsByTheme = mySets.parallelStream()
.unordered()
.collect(Collectors.groupingByConcurrent(LegoSet::getTheme));
ahol a groupingByConcurrent a groupingBy konkurens megfelelője.
Ha lényeges, hogy egy adott kulcshoz tartozó elemek ugyanabban a sorrendben jelenjenek meg, mint ahogyan a forrásban voltak, akkor nem használhatjuk a konkurens redukciót.
Párhuzamos problémák
Azért nem érdemes ám mindent ész nélkül párhuzamosítani még akkor sem, ha a Stream API segítségével a párhuzamosítás alig több egy csuklómozdulatnál. Tekintsük az alábbi példát:
private static long countPrimes(int max) { return IntStream.rangeClosed(1, max).parallel().filter(ThisClass::isPrime).count(); } private static boolean isPrime(long n) { return n > 1 && IntStream.rangeClosed(2, (int) Math.sqrt(n)) .noneMatch(divisor -> n % divisor == 0); }
A countPrimes megszámolja a prímek számát 1 és a max között. A stream-et az IntStream.rangeClosed metódus hozza létre, aztán átváltunk párhuzamos feldolgozásra majd pedig kiszűrjük a stream-ből a nem prímszámokat és a maradékot megszámoljuk. A Stream API-val a megoldás nagyon szépen leírható, a párhuzamosítás egyszerűbb nem is lehetne. Mivel az isPrime metódusunk CPU intenzív és nem valami hatékony, kihasználhatjuk a párhuzamosítás előnyeit és az összes rendelkezésre álló processzormagot. Nézzük egy másik példát:
private List<LegoSet> getLegoInfo(Stream<String> legoNumber) { return legoNumber.parallel().map(this::getLegoSet).collect(Collectors.toList()); }
Megkapunk egy sztringlistát a lekérdezni kívánt legókészletek azonosítóival. Tegyük fel, hogy a getLegoSet metódus hálózaton keresztül kérdezi le valahonnan az adott készlet információit, majd visszaadja egy LegoSet példányban. Itt igazából nem sokáig tartó CPU intenzív művelet miatt párhuzamosítunk, de a párhuzamos hálózati kérések miatt itt is előnyösnek véljük a párhuzamosítást. Ez a példa viszont tartalmaz egy nagy hibát. A párhuzamos stream-ek a ForkJoinPool API-t használják a párhuzamosításhoz és ha ide hosszú ideig futó taszkokat veszünk fel, akkor könnyen blokkolhatjuk a pool-ban lévő többi szál futását. Vagyis az összes taszkot ami párhuzamos stream-eket használ.
Képzeljük el, hogy szerveres környezetben valaki meghívja a countPrimes metódust, egy másik meg a getLegoInfo-t. Az egyik blokkolni fogja a másikat még akkor is ha mindkettőnek más erőforrásokra van szüksége. A párhuzamos stream-eknek nem adhatjuk meg kézzel, hogy milyen thread pool-t használjanak, az osztálybetöltő mindig ugyanazt fogja használni. A VisualVM eszközzel meg is jeleníthetjük a szálakat, a prímszám számoló példánál látható, hogy az én négymagos processzoromnál négy szál fogja a munkát végezni: a main és három worker szál:
A következő példa azt szemléltei, hogy mi történik ha egy folyamat megfogja a szálakat:
package hu.egalizer.java8; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; import java.util.stream.IntStream; public class ParallelPrimes { public static void main(String[] args) throws InterruptedException { try { Thread.sleep(6000); } catch (InterruptedException e) { // do nothing } long kezd = System.currentTimeMillis(); ExecutorService es = Executors.newCachedThreadPool(); int MAX = 1000000; es.execute(() -> countPrimes(MAX, 100)); // sokáig futó es.execute(() -> countPrimes(MAX, 0)); es.execute(() -> countPrimes(MAX, 0)); es.execute(() -> countPrimes(MAX, 0)); es.execute(() -> countPrimes(MAX, 0)); es.execute(() -> countPrimes(MAX, 0)); es.shutdown(); es.awaitTermination(60, TimeUnit.SECONDS); System.out.println((System.currentTimeMillis() - kezd) / 1000); } private static void countPrimes(int max, int delay) { System.out.println(IntStream.range(1, max).parallel().filter(ParallelPrimes::isPrime).peek(i -> { try { Thread.sleep(delay); } catch (InterruptedException e) { // do nothing } }).count()); } private static boolean isPrime(long n) { return n > 1 && IntStream.rangeClosed(2, (int) Math.sqrt(n)).noneMatch(divisor -> n % divisor == 0); } }
Hat folyamatot szimulálunk, mindegyik CPU igényes feladatot végez, az első viszont fogja magát és szépen elalszik egy tizedmásodpercre, miután megtalált egy prímszámot. Ez persze csak egy mesterséges példa, de talán nem nehéz elképzelni egy olyan szálat ami beragad vagy egy blokkoló műveletet végez. A kérdés az, hogy mi fog történni, amikor lefuttatjuk ezt a kódot? Hat taszkunk van, egyiküknek egy egész napig tart hogy befejeződjön, míg a többi sokkal hamarább is befejeződne. Nem meglepő módon a példakód minden egyes futásakor más-más eredményt kapunk. Néha minden egészséges taszk befejeződik, néha több beragad a lassú mögé. Az alábbi VisualVM diagramon egy ilyen esetet látunk:
A pool-1-thread-1-től 6-ig az ExecutorService-nek átadott hat taszk, viszont a közös ForkJoinPool továbbra is négy szálon dolgozik a négymagos processzoron. Négy taszk szerencsés volt és még lefutott (pool-1-thread-2, 4, 5 és 6), de közben a pool-1-thread-1-ben lévő beragadó taszk megkaparintotta mind a három worker szálat és nem eresztette többé. A pool-1-thread-3 pedig némi számolás után már csak várakozik arra, hogy felszabaduljon valamely worker szál.
Nem valószínű, hogy egy éles rendszerben ilyen működést szeretnénk. Két lehetőség van, hogy elkerüljük az ilyen helyzeteket. Az első, hogy nem írunk beragadó taszkokat... Ezt persze könnyebb mondani mint megcsinálni, pláne összetett alkalmazásokban. A párhuzamos taszkoknak viszont meg is adhatunk specifikus thread pool-t amivel függetlenné tehetjük őket egymástól. Saját ForkJoinPool használata:
ForkJoinPool forkJoinPool = new ForkJoinPool(2); System.out.println(forkJoinPool.submit(() -> IntStream.range(1, max).parallel().filter(ParallelPrimesFixed::isPrime).peek(i -> { try { Thread.sleep(delay); } catch (InterruptedException e) { // itt semmi teendő } }).count()).get());
A példa 2 szálat használó ForkJoinPool-t mutat be. Így minden egyes folyamatunk külön thread pool-t kap és nem fogják egymást zavarni. Ha ennek megfelelően módosítjuk a fenti 6 taszkot futtató példaprogramot akkor már sokkal szebb eredményt kapunk: 5 taszk annak rendje és módja szerint lefut és csak a hatodik várakozik szorgalmasan:
Ráadásul a get() metódusnak van olyan változata is aminek timeout-ot adhatunk át, így bebiztosíthatjuk magunkat, hogy egy idő után mindegyik taszk befejeződjön. De talán nem véletlenül nem lehet közvetlenül megadni a stream-eknek saját thread poolt: a Java 8 tervezői feltehetően el akarták kerülni azt az esetet amikor mindenki elkezdi ész nélkül használni a thread poolokat és a végén egy JVM-en belül is kismillió lesz belőle, így a többszálú teljesítmény végül nem javulni hanem romlani fog. Szóval ezt a megoldást nem árt körültekintően használni.
Másik probléma a párhuzamos streamekkel, hogy óvatlan használattal könnyen holtpontot okozhatunk vele a JVM-ben. A legegyszerűbb példa:
package hu.egalizer.java8; import java.util.stream.IntStream; public class DeadlyLock { public static void main(String... args) { synchronized (System.out) { System.out.println("Hello World"); IntStream.range(0, 4).parallel().forEach(System.out::println); } } }
Ha a kódot parallel() nélkül futtatjuk, akkor semmi probléma nincs: megkapjuk, hogy Hello World, aztán pedig 0,1,2,3. A parallel-es változat viszont szemrebbenés nélkül képes megakasztani a JVM-et. A fő szál megszerezte a zárolást a System.out-ra, ami azt jelenti, hogy a thread pool-ból a már föntebb is látott worker szálak blokkolódtak (a println metódus ugyanis egy synchronized(this) utasítással kezdődik):
A fő szál nem tud folytatódni amíg a worker szálak nem végeztek azok viszont a fő szálra várnak. Klasszikus holtponti helyzet. A vicces az, hogy az eredmény sem mindig lesz ugyanaz, a legviccesebb pedig hogy egy thread dump-ból sem fogjuk tudni kideríteni, hogy ez egy Java holtpont. Ilyen egyszerű példákat számolatlanul lehet gyártani, például:
package hu.egalizer.java8; public class DeadlyBlocker { private int sum; public DeadlyBlocker(int defaultSum) { sum = defaultSum; } public void addToSum(int i) { synchronized (this) { sum += i; } } public int getSum() { return sum; } }
package hu.egalizer.java8; import java.util.stream.IntStream; public class DeadLockMe { public static void main(String[] args) { DeadlyBlocker blocker = new DeadlyBlocker(0); synchronized (blocker) { System.out.println(blocker.getSum()); IntStream.range(0, 4).parallel().forEach(blocker::addToSum); } } }
A System.out::println azért is jó példa mert szinte minden párhuzamos Stream-példa tartalmazza valahol. Persze nem árt elkerülni a blokkoló hívásokat a párhuzamos stream-ekben de ezt néha nem olyan egyszerű megcsinálni mint mondani.
Mikor használjunk párhuzamos stream-eket?
Láttuk, hogy a Stream API-nál nekünk kell megadni, mikor szeretnénk párhuzamos és mikor soros feldolgozást. A New York-i Egyetem számítástudományi professzora, Douglas Lea írt egy kis útmutatót a döntés megkönnnyítéséhez. Ezt ismertetem az alábbiakban, mégpedig azért, mert a párhuzamosítás nem varázsszer, bizonyos esetekben még lassabb is lehet mint a soros feldolgozás. Ha az alábbi tanácsokat megfogadjuk, akkor elkerülhetjük az aknamezőt. Vagy legalábbis néhány aknát.
Tegyük fel, hogy az S.parallelStream().operation(F) kifejezés műveletei függetlenek és vagy számításigényesek vagy pedig hatékonyan felszeletelhető adatszerkezet sok elemén dolgoznak. A kifejezésben:
Párhuzamos végrehajtást akkor érdemes választani, ha a soros végrehajtással elérhető futásidő túllép egy adott küszöbértéket. Nincs is szükség a futásidő pontos ismeretére, elég jól meg lehet becsülni. Szorozzuk meg az N-et (elemek száma) Q-val (F költsége elemenként). Ha az N*Q legalább 10000 (gyávábbak hozzáírhatnak még egy-két nullát), akkor érdemes párhuzamos feldolgozást választani. (Q-nak egyszerűen a műveletek vagy kódsorok számát is vehetjük.)
Ha például az F egy apró függvény (mondjuk x -> x+1), akkor az N >= 10000 kell legyen, hogy megérje párhuzamos feldolgozást alkalmazni. Ha az F egy óriási számítás (például meghatározni a következő legoptimálisabb lépést egy sakkjátszmában), akkor a Q tényező már olyan nagy, hogy az N nem is számít (feltéve, hogy a collection teljesen feldarabolható). Ha viszont a számítás nem interferenciamentes, akkor a párhuzamos feldolgozásnak nem sok értelme van.
A fenti elveken kívül még három további feltétel is befolyásolja a párhuzamos futtatást:
Persze nem egyszerű minden fenti összetevő pontos mérése, de az átlagos hatásokat azért könnyű látni és némi gyakorlattal már jól meg tudjuk ítélni, hogy érdemes-e párhuzamosítani. Egy 32 magos tesztgépen például a max() vagy sum() függvények ArrayList-en való futtatásakor a párhuzamosítás optimális határa 10 ezer elem körül van. Ennél kisebb elemszám esetén a futásidők már nem sokkal rövidülnek és esetenként akár lassabbak mint a soros feldolgozás. A legdurvább lassulás akkor következik be, ha 100 elemnél is kevesebbünk van. Ilyenkor egy csomó olyan szál indul el amik úgy végzik be, hogy nem is csinálnak semmit, mert a számítás végetér mire elindulnak. Érdekesség, hogy nem okoz speciális kezelésmódot az sem, ha a programunkat olyan rendszeren fogjuk futtatni, ahol a magoknak általában nagy a kihasználtságuk (feltéve persze ha a párhuzamos feldolgozáshoz szükséges feltételek egyébként teljesülnek). Párhuzamos taszkjaink versengeni fognak a CPU időért a többivel, tehát kisebb gyorsulást tapasztalunk, de ez a legtöbb esetben még mindig jobb lesz mint a soros feldolgozás. Ha már nincsenek elérhető magok, akkor csak egy kis lassulást fogunk tapasztalni a soros feldolgozáshoz képest, kivéve persze ha a rendszer már annyira leterhelt, hogy a CPU idő legnagyobb részét a kontextuskapcsolás veszi el vagy a rendszer alapvetően soros feldolgozáshoz van beállítva (például a rendszergazda valamiért csak egy magot hagyott bekapcsolva a JVM számára).
A mai modern hardvereknél és operációs rendszereknél egyébként szinte lehetetlen előre megmondani, hogy pontosan mennyi gyorsulást fogunk kapni a párhuzamosítástól. Az eredményt befolyásolja a cache jelenlét, szemétgyűjtési teljesítmény, JIT fordítás, memóriaelrendezés, adatelrendezés, operációs rendszer ütemezési beállításai, virtuális gépek, stb. Épphogy csak a Hold állása nem. Persze ezek a tényezők a soros feldolgozást is befolyásolják, de a párhuzamosat még inkább. Egy olyan tényező, ami soros végrehajtásban 10%-os eltérést ad, párhuzamos feldolgozásban ennek a tízszeresét is jelentheti.
A soros feldolgozásnál alkalmazott fogások általában párhuzamos feldolgozásnál is működnek. Többnyire jó módszer ha a Collection-t használó komponens fejlesztője a technikai döntéseket a komponensen belül eldönti és csak az ezeken alapuló műveleteket exportálja a felhasználónak. Legyen például egy komponens, aminek van egy belső counts collection-je. A komponens a párhuzamos/soros döntéshez használatos méretküszöböt belsőleg kezeli (hacsak nem túl költséges az elemenkénti számítás) és a külvilágnak már a megfelelő stream-et adja át:
public long getMaxCount() { return countStream().max(); } private Stream countStream() { return (counts.size() < MIN_PAR) ? counts.stream() : counts.parallelStream(); }
I/O és párhuzamosítás
A JDK-ban az I/O-alapú Stream-ek (például a BufferedReader.lines()) főként soros feldolgozásra lettek kitalálva. Léteznek lehetőségek pufferelt I/O nagy hatékonyságú kötegelt feldolgozására, de ezek egyedi fejlesztést igényelnek. Az általános felhasználású, de I/O-t vagy szinkronizálást használó stream-ek közül egyik végletet azok a függvények jelentik, amelyek belsőleg soros I/O elérést végeznek vagy zárolt szinkronizált erőforrásokat érnek el és nem felelnek meg az interferencia-mentesség kritériumainak. Ezek párhuzamosításának nincs sok értelme. A másik végletet azok a számítások jelentik, amik alkalmankénti átlátszó I/O műveleteket végeznek vagy olyan szinkronizációt ami ritkán blokkoló (ilyen például a legtöbb logolás és a konkurens collection-ök mint például a ConcurrentHashMap használata). Ezek ártalmatlanok. A kettő közötti esetek egyedi elbírálást igényelnek. Ha minden altaszk feltehetően jelentős ideig blokkolódik I/O-ra vagy más erőforrás elérésére várva, akkor a CPU erőforrások kihasználatlanul maradnak. Ezekben az esetekben a párhuzamos stream-ek általában nem jelentenek jó választást.
Egy metódusnak vagy kifejezésnek akkor van mellékhatása, ha az érték visszaadásán vagy létrehozásán kívül a virtuális gép állapotát is módosítja. Ilyen például a mutable reduction, de akár egy System.out.println is. A JDK a csővezeték bizonyos mellékhatásait elég jól kezeli. A collect metódus a legtöbb, mellékhatással rendelkező stream műveletet szálbiztos módon hajtja végre. A forEach és a peek eleve a mellékhatás figyelembe vételével lett tervezve; egy olyan lambda kifejezés pedig, ami void-dal tér vissza (például csak meghívja a System.out.println metódust), gyakorlatilag mást se csinál csak mellékhatást. De azért nem árt, ha az ember a forEach és peek metódust óvatos duhajként használja. Ha ezen műveletek valamelyikét párhuzamos stream-mel használjuk, akkor a futtatókörnyezet konkurensen több szálból is meghívhatja a paraméterként megadott lambda kifejezést. A filter és a map műveletek paramétereiként pedig soha ne adjunk át mellékhatásokat okozó lambda kifejezéseket.
Ha nincs jelezve az ellenkezője, akkor semmi garancia nincs rá, hogy mellékhatásokat okozó viselkedési paraméterek mellékhatásai a többi szál számára is láthatóak, sem pedig arra, hogy különböző műveleteket "ugyanazon" az elemen ugyanaz a szál fogja végrehajtani. Még ha ki is van kényszerítve, hogy a legyártott eredmény sorrendje megfeleljen a stream forrásának encounter order-jével (például az IntStream.range(0, 5).parallel().map(x -> x * 2).toArray() streamnek ezt kell produkálnia: [0, 2, 4, 6, 8]), akkor sincs meghatározva, hogy az egyes elemekre alkalmazott leképezési függvény milyen sorrendben fog végrehajtódni. És az sem, hogy melyik szál hajtja végre egy adott elemhez a viselkedési paramétert. Jobb tehát elkerülni a mellékhatást okozó kifejezéseket, talán csak a debug célokra alkalmazott println kivétel. A csak mellékhatással működő stream műveleteket (forEach() és a peek()) pedig óvatosan kell használni.
Íme egy példa, hogyan tudunk átalakítani egy mellékhatásokat okozó csővezetéket olyanná ami nem csinál ilyet. Ez egy sztring stream-ben olyan mintákat keres, amik megfelelnek egy adott reguláris kifejezésnek és ezeket kigyűjti egy listába.
ArrayList<String> results = new ArrayList<>();
stream
.filter(s -> pattern.matcher(s).matches())
.forEach(s -> results.add(s));
Párhuzamos végrehajtással a nem szálbiztos (szálbizonytalan...) ArrayList rossz eredményeket adna, a szinkronizálással való kiegészítés pedig versengést okozna. Ráadásul a mellékhatás alkalmazása itt teljesen fölösleges. A forEach() metódust egyszerűen le lehet cserélni egy redukcióra, ami sokkal alkalmasabb párhuzamos feldolgozáshoz:
List<String> results = stream
.filter(s -> pattern.matcher(s).matches())
.collect(Collectors.toList());
Az állapotottartó (stateful) lambda kifejezések is okozhatnak mellékhatásokat és inkonzisztens vagy megjósolhatatlan eredményeket, különösen a párhuzamos stream-ekben. A lelki béke megőrzése érdekében ezeket is jobb elkerülni a stream műveletek paramétereiben. Egy lambda akkor állapottartó ha az eredménye függ bármely olyan állapottól, ami megváltozhat a csővezeték végrehajtása közben. A következő példa összead elemeket a listOfIntegers List-ből egy új List példányba a map művelettel. Ezt kétszer teszi meg; először egy soros streammel, aztán egy párhuzamossal:
List<Integer> parallelStorage = Collections
.synchronizedList(new ArrayList<>());
integerList.parallelStream()
// Elkerülendő állapottartó lambda kifejezés
.map(e -> {
parallelStorage.add(e);
return e;
})
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
parallelStorage.stream().forEachOrdered(e -> System.out.print(e + " "));
Az e -> { parallelStorage.add(e); return e; } egy állapottartó lambda kifejezés. Ennek eredménye a kód minden egyes futásakor változhat. A példa a következőt írja ki:
8 7 6 5 4 3 2 1 3 4 7 1 6 8 5 2
A forEachOrdered művelet az elemeket a stream által adott sorrendben dolgozza fel, függetlenül attól, hogy a stream végrehajtása soros vagy párhuzamos. Viszont amikor egy stream párhuzamosan hajtódik végre, akkor a map művelet a stream elemeit a futtatókörnyezet és a fordító által megadott rendben dolgozza fel. Ezért a kód minden egyes futásakor különböző lehet annak sorrendje, ahogy az e -> { parallelStorage.add(e); return e; } kifejezés beleteszi az elemeket a parallelStorage List-be. Determinisztikus és megjósolható eredményhez érdemes biztosítani, hogy a stream műveletek lambda kifejezés paraméterei ne legyenek állapottartóak.
Megjegyzés: ez a példa meghívja a synchronizedList metódust, tehát a parallelStorage List szálbiztos. Emlékezzünk rá, hogy a collection-ök nem szálbiztosak. Ez azt jelenti, hogy több szál nem érhet el egy adott collection-t ugyanabban az időben. Tegyük fel, hogy nem hívjuk meg a synchronizedList metódust a parallelStorage létrehozásakor:
List<Integer> parallelStorage = new ArrayList<>();
Ekkor a példa még kiszámíthatatlanabbul viselkedik mert a parallelStorage-t ütemezést biztosító szinkronizációs mechanizmus nélkül éri el és módosítja több szál.
Az Iterable interfészről bizonyára mindenki hallott már: ez alkotja minden collection-ök ős interfészét és eddig csupán egy metódusa volt ami annyit tett, hogy visszaadott egy Iterator-t. A Java 8 ezt két plusz metódussal háromra egészítette ki:
default void forEach(Consumer<? super T> action)
Iterator<T> iterator()
default Spliterator<T> spliterator()
A forEach egyszerű bejárást biztosít a lambdákkal azokhoz az interfészekhez amelyek implementálják:
List<String> stringList = Arrays.asList("egy", "kettő", "három"); stringList.forEach(s -> System.out.println("Aktuális elem: " + s));
Az Iterator interfész is kiegészült egy hasonló, lambdát fogadó metódussal (forEachRemaining), aminek a neve magáért beszél:
List<String> stringList = Arrays.asList("egy", "kettő", "három"); Iterator<String> iter = stringList.iterator(); if (iter.hasNext()) { iter.forEachRemaining(System.out::println); }
Az Iterator-ról eddig is tudtuk, hogy micsoda, de mi az az spliterator?
Nos a java.util.Spliterator alapvetően arra készült, hogy elemek halmazát több részre szétszedjünk (split, innen jön a split iterator - spliterator), így bizonyos műveleteket, számításokat párhuzamosan külön szálakban is feldolgozhassunk. Az Spliterator lényegében az Iterator párhuzamos megfelelője, leír egy (potenciálisan végtelen) elemekből álló collection-t, ami támogatja az elemeken a szekvenciális előrelépegetést, kötegelt bejárást és azt, hogy a forrás egy részét át lehessen adni másik spliterator-nak, akár párhuzamos feldolgozást is létrehozva. Alacsony szinten minden stream lelke egy spliterator. A collection-ök mellett az Spliterator által feldolgozott források lehetnek például tömb, I/O csatorna vagy generátor függvény. Bár én ebben a cikkben a Spliterator használatát is bemutatom, normál esetben egy Java 8 fejlesztőnek szinte sosem kell ezzel foglalkoznia, csak ha esetleg saját Collection osztályt szeretne fejleszteni.
Az interfész 8 metódust biztosít.
boolean tryAdvance(Consumer<? super T> action)
default void forEachRemaining(Consumer<? super T> action)
A tryAdvance használatával be tudjuk járni az elemeket sorban egyesével. Ha létezik további elem, akkor a metódus végrehajtja rajta az action paramétert és true értékkel tér vissza, egyébként nem csinál semmit, csak false értéket ad vissza. A tryAdvance tehát hasonló az Iterator hasNext() - next() párosához, csak egyben valósítja meg azt a funkcionalitást. A forEachRemaining metódust a soros kötegelt bejáráshoz használhatjuk.
Spliterator<T> trySplit()
A trySplit metódus kettévágja az aktuális spliteratort és visszaad egy újat a szétvágás másik részével:
List<String> stringList = Arrays.asList("egy", "kettő", "három"); Spliterator<String> iter = stringList.spliterator(); Spliterator<String> iter2 = iter.trySplit(); iter.forEachRemaining(System.out::println); System.out.println("Iter2:"); iter2.forEachRemaining(System.out::println);
A kettévágás műveletet "particionálisnak" vagy "dekompozíciónak" hívják. Egy ideális trySplit művelet az elemeket pont fele-fele arányban osztja szét. Ha az aktuális Spliterator példányon már nem lehet további particionálást végezni (a fenti példában ilyen az iter2), akkor a visszatérési értéke null. Ha az Spliterator példányunk a split műveletet nem vagy nem hatékonyan, esetleg aránytalanul valósítja meg, akkor az azt használó műveletek semmi előnyt nem fognak kapni a párhuzamosságból. Bár az Spliterator segít a párhuzamos algoritmusokban, nem elvárás tőlük, hogy szálbiztosak legyenek. A spliterátorokat használó párhuzamos algoritmusoknak kell biztosítani, hogy egy spliterator-t egyszerre csak egy szál használjon. A trySplit()-et hívó szál átadhatja a visszakapott Spliterator-t egy (de csak egy) másik szálnak ami viszont bejárhatja vagy tovább hasíthatja (split) azt az spliterator-t. A split művelet és a bejárás viselkedése meghatározatlan, ha két vagy több szál használja párhuzamosan ugyanazt az spliterator-t. Ha az eredeti szál átadja az spliterator-t feldolgozásra egy másik szálnak, akkor a legjobb, ha az átadás még azelőtt megtörténik mielőtt a tryAdvance() metódussal bármilyen elem feldolgozásába belekezdenénk, mivel bizonyos biztosítékok (mint például az estimateSize() pontossága a SIZED tulajdonságú spliterator-ok esetén) csak a bejárás elkezdése előtt érvényesek. Látható, hogy maga az Spliterator még semmit nem dolgoz fel "párhuzamosan" (nincs köze a ForkJoinPool API-hoz sem), csupán alapvető műveleteket biztosít párhuzamosság implementálásához.
int characteristics()
default boolean hasCharacteristics(int characteristics)
Egy spliterator egy bitmaszkban meg tudja mondani a saját implementációjának jellemzőit, vagy más néven karakterisztikáit az interfészben definiált konstansok képében. A karakterisztikák (néha stream flag-ként is hívják) bevezetésének az volt a célja, hogy lehetővé tegye a stream műveletek számára a fölösleges munka elhagyását. Ha például tudjuk, hogy egy stream már sorbarendezett, akkor a sorted() művelet nem csinál semmit. Ha tudjuk a stream elemeinek pontos számát, akkor a toArray() rögtön a megfelelő méretű tömböt tudja lefoglalni és elkerülhetők a fölösleges tömbmásolások. Vagy ha tudjuk, hogy a forrásnak nincs encounter order-je akkor nem is kell azt megtartanunk; erről a párhuzamos stream-ek esetén volt is szó. Egy stream csővezeték minden egyes fokozatának van adott karakterisztikája. A közbülső műveletek beszúrhatnak vagy törölhetnek karakterisztikát. 8 különböző karakterisztika létezik:
Ha például egy ArrayList-ből csinálunk Spliteratort, az ORDERED, SIZED és SUBSIZED jellemzőkkel fog rendelkezni. Ha ugyanezt egy HashSet-ből tesszük, az DISTINCT és SIZED jellemzőkkel.
Az Spliterator kötése (bind) az a pillanat amikor az lényegében a forráshoz rendelődik. Egy késői kötésű (late-binding) Spliterator nem a példány létrehozásakor, hanem az első bejárás, első split vagy a becsült méret első lekérdezésének pontján lesz kötve az elemek forrásához. Egy nem késői kötésű Spliterator az elemek forrását a létrehozás pillanatában vagy pedig bármely metódus meghívásakor köti. A forrást érintő bármely kötés előtti módosítás megjelenik amikor az Spliterator bejárja a forrást.
A kötés után az Spliterator-nak lehetőség szerint ConcurrentModificationException-t kell dobnia ha szerkezeti interferenciát észlelt. Fail-fast-nak hívjuk az olyan Spliterator-okat amik ezt megteszik. A tömeges bejárási metódus (forEachRemaining()) viszont optimalizálhatja is a bejárást. Ez azt jelenti, hogy nem elemenként ellenőriz és nem dob azonnal hibát, hanem csak miután minden elemet bejárt. Egy olyan Spliterator aminek nincs IMMUTABLE vagy CONCURRENT tulajdonsága, speciális eljárásmódot igényel: a forrás mindenféle szerkezeti interferenciája a kötés után lesz észlelve.
A szerkezeti interferencia a következő módokon kezelhető (nagyjából a csökkenő kívánatosság sorrendjében):
long estimateSize()
default long getExactSizeIfKnown()
Az estimateSize megadja a hátralévő elemek becsült számát, amiket egy adott pontnál még be lehet járni. Ha a tulajdonság SIZED akkor a bejárással elérhető pontos elemszámot adja vissza, de ha az elemek száma végtelen, ismeretlen vagy túl költséges kiszámítani akkor akár Long.MAX_VALUE értéket is visszaadhat (mindenesetre ha felülírjuk akkor lehetőség szerint akkor is érdemes becsülni, ha nem tudunk pontos értéket).
A getExactSizeIfKnown() default metódus csak kényelmi funkciókat lát el, az alapértelmezett implementációja:
return (characteristics() & SIZED) == 0 ? -1L : estimateSize();
Az estimateSize visszatérési értékét adja vissza ha az spliterator jellemzője SIZED, egyébként pedig -1-et. Példaként nézzük a következő kódot:
List<String> stringList = Arrays.asList("egy", "kettő", "három"); Spliterator<String> iter = stringList.spliterator(); iter.tryAdvance(System.out::println); System.out.println(iter.getExactSizeIfKnown());
A kimenete:
egy
2
default Comparator<? super T> getComparator()
Amennyiben az Spliterator példány SORTED jellemzőjű, ez a metódus visszaadja a megfelelő Comparator-t. Ha a forrás természetes sorrendben rendezett, akkor null-t ad vissza, egyébként pedig ha a forrás nem SORTED, akkor IllegalStateException-t dob.
Az Spliterator háromféle primitív típushoz tartozó belső interfészt is definiál:
Ezen alapértelmezett implementációk tryAdvance és forEachRemaining implementációi boxingolnak primitív értékeket a nekik megfelelő wrapper osztályokba. Az OfPrimitive a szülőosztály a primitív típusokat használó speciális osztályokhoz. Ez a boxing alááshatja a primitív specializált osztályok használatából adódó teljesítménybeli előnyöket. A boxing elkerüléséhez a megfelelő primitív-alapú metódusokat ajánlatos használni. Tehát az Spliterator.OfInt.tryAdvance(java.util.function.IntConsumer) és Spliterator.OfInt.forEachRemaining(java.util.function.IntConsumer) ajánlatos az Spliterator.OfInt.tryAdvance(java.util.function.Consumer) és Spliterator.OfInt.forEachRemaining(java.util.function.Consumer) helyett. Egy példa:
int[] ints = { 1, 3, 5, 7 };
Spliterator.OfInt s = Arrays.spliterator(ints);
s.forEachRemaining((IntConsumer) System.out::println);
Stream létrehozása iterátorokból
Az Iterable interfészt az általánosságot szem előtt tartva tervezték meg, ezért nincs stream() metódusa, de nem kell kétségbeesni, mert a StreamSupport osztállyal bármikor tudunk belőle streamet csinálni! Mégpedig így:
Iterable<String> iterable = Arrays.asList("egy", "kettő", "érik", "a", "vessző"); StreamSupport.stream(iterable.spliterator(), false);
A StreamSupport.stream() második paramétere mondja meg, hogy a létrehozott stream párhuzamos legyen-e. A StreamSupport alacsony szintű műveleteket biztosít stream-ek létrehozásához és módosításához, a JDK kifejezetten osztálykönyvtár-íróknak ajánlja a használatát. Az általános célú programoknak a Stream és leszármazottai elegendő lehetőséget biztosítanak. A fenti stream metódus másik változata Spliterator típussal paraméterezett Supplier-t vár paraméterként és a karakterisztikát is meg kell adni neki:
stream(Supplier<? extends Spliterator<T>> supplier, int characteristics, boolean parallel)
A Spliterator-t itt tehát a supplier adja meg, de a Supplier.get() metódus csak egyszer lesz meghívva, mégpedig akkor amikor a stream csővezeték lezáró művelete elkezdi a végrehajtást. A két külön stream metódus tehát arra jó, hogy az egyikkel késői, a másikkal pedig korai kötésű stream-eket tudjunk létrehozni. A Java 8 dokumentációja szerint az IMMUTABLE vagy CONCURRENT karakterisztikájú spliterator-oknak hatékonyabb, ha az egyszerűbb paraméterezésű változatot használják. A második megoldásban a Supplier egyfajta indirekciót biztosít, ami csökkenti a forrással való interferencia valószínűségét. Mivel a supplier csak a lezáró művelet végrehajtásakor hívódik meg, a forrást érintő bármely, a lezáró művelet előtti módosítás megjelenik a stream eredményében. A characteristics paraméternek ebben a második változatban meg kell egyeznie a supplier.get().characteristics() eredményével, különben nem várt eredményt kaphatunk. Egy példa:
package hu.egalizer.java8; import java.util.ArrayList; import java.util.List; import java.util.Spliterator; import java.util.stream.Stream; import java.util.stream.StreamSupport; public class StreamSupportExample { public static void main(String[] args) { List<String> koraiKotesu = new ArrayList<String>() { @Override public Spliterator<String> spliterator() { System.out.println("Early binding!"); return super.spliterator(); } }; koraiKotesu.add("Első"); koraiKotesu.add("Második"); koraiKotesu.add("Harmadik"); Stream<String> str = StreamSupport.stream(koraiKotesu.spliterator(), false); List<String> kesoiKotesu = new ArrayList<String>() { @Override public Spliterator<String> spliterator() { System.out.println("Late binding!"); return super.spliterator(); } }}; kesoiKotesu.add("Első"); kesoiKotesu.add("Második"); kesoiKotesu.add("Harmadik"); Stream<String> str2 = StreamSupport.stream(() -> kesoiKotesu.spliterator(), Spliterator.ORDERED, false); str2 = str2.filter(s -> s.length() > 4); } }
A koraiKotesu listából létrehozott str stream esetén már a létrehozáskor megtörténik a kötés, kiíródik, hogy Early binding!, míg a kesoiKotesu listából létrehozott str2 stream esetén még a filter közbülső műveletnél sem.
A StreamSupport a kétféle stream létrehozó metódust természetesen doubleStream, intStream és longStream formában is tartalmazza. Ezek működése az eddigiek alapján szerintem már könnyen kitalálható.
Spliterators
Ha nincs kéznél megfelelő Spliterator, az Spliterators osztály statikus gyártófüggvényeivel csinálhatunk önálló Spliterator példányokat is (vagyis amiket nem collection-ből generálunk):
Spliterator<T> emptySpliterator(): üres SIZED és SUBSIZED karakterisztikájú Spliterator létrehozása. Ezeknél a trySplit mindig null-t fog visszaadni. Természetesen itt sem maradt ki az emptyIntSpliterator, emptyLongSpliterator és emptyDoubleSpliterator változat.
Spliterator<T> spliterator(Object[] array, int additionalCharacteristics): Spliterator létrehozása, ami az array paraméter elemeit fogja bejárni megadott egyedi karakterisztikával. Kényelmi metódus olyan Spliterator-okhoz, amik tömbökben tárolják az elemeiket és szükség van rá, hogy a karakterisztikát expliciten meg lehessen nekik adni. Ez a metódus mindig beállít SIZED és SUBSIZED karakterisztikát a visszaadott Spliterator-nak, a hívó a paraméterekben ezeket bővítheti (általában IMMUTABLE és ORDERED karakterisztikával). Normál esetben ha tömbhöz való Spliterator-ra van szükségünk, akkor az Arrays.spliterator(Object[]) metódust érdemes használni.
Spliterator<T> spliterator(Object[] array, int fromIndex, int toIndex, int additionalCharacteristics): a megadott tömb elemeinek adott intervallumából csinál Spliterator-t adott karakterisztikával. Ez a metódus is mindig beállít SIZED és SUBSIZED karakterisztikát a visszaadott Spliterator-nak, a hívó a paraméterekben ezeket bővítheti.
A fenti két spliterator() metódusnak természetesen van int[], long[] és double[] tömbökből gyártó változata is, amelyek a fentebb már említett háromféle primitív típusú Spliterator-t gyártanak (Spliterator.OfDouble, Spliterator.OfInt, Spliterator.OfLong).
Spliterator<T> spliterator(Collection<? extends T> c, int characteristics): a megadott c collection Collection.iterator()-jából gyárt Spliterator-t a Collection.size() visszatérési értékével alapértelmezett méretként. Ez kései kötésű lesz és örökli a collection iterátorának fail-fast tulajdonságait, valamint implementálja a trySplit metódust korlátozott párhuzamosság biztosítása céljából. A metódus beállít SIZED és SUBSIZED karakterisztikát is (kivéve ha a hívó CONCURRENT karakterisztikát ad meg), a hívó a paraméterekben ezeket bővítheti.
Spliterator<T> spliterator(Iterator<? extends T> iterator, long size, int characteristics): a paraméterként megadott iterator-ból gyárt spliterator-t size alapértelmezett mérettel. Ez korai kötésű lesz és örökli a forrás iterator fail-fast tulajdonságait, valamint implementálja a trySplit metódust. Fontos észben tartani, hogy ezután az elemek bejárása már a visszaadott spliterator-on keresztül történjen. Ha mégis a paraméter iterátort piszkáljuk, akkor ne csodálkozzunk ha valami zagyvaság lesz a végeredmény. Ajánlatos a size paramétert is pontosan, az iterator elemeinek tényleges méretére megadni. A metódus beállít SIZED és SUBSIZED karakterisztikát is (kivéve ha a hívó CONCURRENT karakterisztikát ad meg), a hívó a paraméterekben ezeket bővítheti.
spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics): a paraméterként megadott iterator-ból gyárt spliterator-t ami korai kötésű, örökli a forrás iterator fail-fast tulajdonságait és implementálja a trySplit metódust. Itt sem ajánlatos az iterator használata miután visszakaptunk belőle egy Spliterator-t. Mivel ez a metódus méret megadását nem igényel, figyelmen kívül hagyja a paraméterként megadott SIZED és SUBSIZED karakterisztikát.
Egyébként a default Iterable.spliterator() metódus is egy Spliterators.spliteratorUnknownSize(iterator(), 0) eredméynét adja vissza. A fenti két metódusnak van olyan változata is, aminél az iterator paraméter PrimitiveIterator.OfInt, PrimitiveIterator.OfLong vagy PrimitiveIterator.OfDouble lehet, ezek primitív típusokat kezelő Iterator interfészek.
Az Spliterators osztály további négy metódusa a Spliterator -> Iterator konverziót végzi el általános, Spliterator.OfInt, Spliterator.OfLong vagy Spliterator.OfDouble típusú spliterator-ból. A Spliterators osztállyal előállított Spliterator-okat a StreamSupport osztállyal pedig már egy csuklómozdulattal stream-ekké alakíthatjuk. De ahogy fentebb is írtam, a Spliterators használatát ajánlatos elkerülni, hacsak nincs rá jó okunk, hogy használjuk. Az Iterable implementációk (mint például a collection-ök) rendelkeznek spliterator() metódussal ami szinte mindig célszerűbb megoldást és esetenként jobb implementációt is biztosít.
Láthattuk, hogy sokféle lehetőség van Spliterator létrehozására, bár szinte mindegyik valamilyen kompromisszum az implementáció egyszerűsége és az Spliterator-t használó stream teljesítménye között. A legegyszerűbb, de legrosszabb teljesítményű megoldás a Spliterators.spliteratorUnknownSize. Ez azért muzsikál gyengén párhuzamos feldolgozásnál, mert elvész a méretezési információ (mekkora az alatta lévő adathalmaz) és egyszerű particionálási algoritmusra lesz korlátozva. Egy nagyobb teljesítményű spliterator kiegyensúlyozott és ismert méretű szeleteket (split) ad pontos méretezési információval és számos egyéb jellemzővel, hogy optimalizálni lehessen a végrehajtást.
A módosítható adatforrásokhoz való Spliterator-oknak további kihívás a kötés időzítése. Az az ideális, amikor a stream-hez tartozó spliterator IMMUTABLE vagy CONCURRENT karakterisztikájú. Ha nem így van, akkor kései kötésűnek kell lennie. Ha egy forrás közvetlenül nem támogatja az ajánlott spliterator-t, akkor indirekt módon esetleg tudunk csinálni egyet a StreamSupport Supplier-t elfogadó metódusaival. Az spliterator csak a lezáró művelet indulása után szerezhető meg a supplier-től.
Ezek a követelmények (feltéve persze ha a közbülső viselkedési műveletek követelményeit is betartjuk) csökkentik a lehetséges interferenciát a forrás módosulásai és a stream csővezeték végrehajtása között. Az spliterator-okon alapuló stream-ek a kívánt karakterisztikával (vagy amelyek használják a Supplier-alapú gyártófüggvényeket) immunisak a forrásnak a lezáró művelet indulását megelőző módosításaira.
Karakterisztikus problémák
A karakterisztikával kapcsolatos működés szépnek és kereknek tűnhet, de ha megnézzük az egyes stream műveletek által generált stream-ek tényleges karakterisztikáját, érdekes megfigyeléseket tehetünk. (A karakterisztikát úgy kapjuk meg, hogy a streamen meghívjuk a .spliterator().characteristics() műveletet.)
1. A Stream.empty() és a paraméterek nélkül meghívott Stream.of() is üres streamet adnak eredményül, de nem ugyanazzal a karakterisztikával:
És miért nincs például NONNULL karakterisztikája egyiknek sem? Az lenne a logikus, ha a Stream.empty() nem csak pluszban IMMUTABLE és ORDERED lenne hanem még DISTINCT és NONNULL is. És annak is lenne értelme ha mondjuk a Stream.of() metódust egy paraméterrel meghívva DISTINCT lenne az eredmény.
2. A paraméterekkel vagy azok nélkül meghívott IntStream.of() (de ugyanúgy a LongStream és DoubleStream) által visszaadott stream-nek nincs NONNULL karakterisztikája. Miért nincs ha természete alapján eleve úgyse tud referencia típust tárolni?
3. A boxed() művelettel elvesznek karakterisztikák a primitív streamekből, pedig semmi ok nem lenne rá:
4. Az üres peek() művelettel elvész a NONNULL és IMMUTABLE karakterisztika, pedig semmi ok nem lenne rá.
5. A skip(), limit() elveszti a SUBSIZED, IMMUTABLE, NONNULL, SIZED karakterisztikákat, pedig a méret meghatározható.
6. a filter() művelet elveszti a SUBSIZED, IMMUTABLE, NONNULL, SIZED karakterisztikát. A másik ketttőnek még van is értelme, de miért veszti el az IMMUTABLE és NONNULL karakterisztikát is?
Sajnos a Java 8 fejlesztői részéről ezekre a felvetésekre nem érkezett válasz. De azért nem maradtunk teljesen magyarázat nélkül, a stackoverflow egyik, a tűzhöz közelebb álló felhasználója segített kissé megvilágítani a feltételezhető okokat és kiderült néhány turpisság.
Ha megnézzük a karakterisztikák leírását (én is a Java 8 API dokumentációját vettem alapul a fordításhoz), úgy tűnhet, hogy a pontos jelentésük még nem volt teljesen letisztázva a Java 8 implementációs fázisában és emiatt aztán következetlenül használták őket. Nézzük például mit mond a dokumentáció az IMMUTABLE karakterisztikáról: "azt jelzi, hogy az elemek forrását nem lehet szerkezetileg módosítani, vagyis nem lehet elemeket hozzáadni, kicserélni vagy eltávolítani, tehát ilyen módosítások nem történhetnek a bejárás során."
Itt eleve fura a kicserélni szó, hiszen az általában nem jelent szerkezeti módosítást amikor List-ről vagy tömbről beszélünk. A tömböt is elfogadó stream és spliterator gyárak (amelyek nem klónozzák) adnak is IMMUTABLE karakterisztikát. Ilyen a LongStream.of() vagy az Arrays.spliterator(long[]). Ha ezt általánosabban értelmezzük úgy, hogy "amíg a kliens által nem észrevehető", akkor nincs jelentős különbség a CONCURRENT karakterisztikához képest. Mindkét esetben látható lesz néhány elem a kliens számára de nincs mód rá, hogy megtudjuk, ezeket a bejárás alatt adták-e hozzá és arra sem, hogy voltak-e olyan elemek amiket nem sikerült már bejárni mert közben eltávolították őket. A specifikáció viszont nem ér véget: "Olyan Spliterator aminek nincs IMMUTABLE vagy CONCURRENT tulajdonsága, speciális eljárásmódot igényel (például ConcurrentModificationException-t kell dobnia) amikor a bejárás során szerkezeti interferenciát észlelt."
Ez a lényeg: egy spliterator ami vagy IMMUTABLE vagy CONCURRENT karakterisztikát jelzett, garantáltan soha nem dob ConcurrentModificationException-t. A CONCURRENT kizárja a SIZED karakterisztikát is, de ennek nincs következménye a kliens kódra nézve.
És itt jön a turpisság: ezek a karakterisztikák semmire nincsenek használva a Stream API-ban, vagyis inkonzisztens használatuk soha sehol nem fog kibukni! Ez a magyarázat arra, hogy miért törli ki az összes közbülső művelet a CONCURRENT, IMMUTABLE és NONNULL karakterisztikát: a Stream implementáció nem használja ezeket és a stream belső állapotát reprezentáló belső osztályok sem tárolják ezeket. A NONNULL sincs sehol sem használva, tehát a hiányának semmiféle hatása nincs.
Az IntStream.of() problémát (második) egészen az Arrays.spliterator(long[], int, int) hívásig vissza lehet követni. Ez tovább hív a föntebb már megismert Spliterators.spliterator(Object[] array array, int fromIndex, int toIndex, int additionalCharacteristics)-be. Ennek a dokumentációja az fentebb leírtakon kívül még ezt is mondja: "A hívó hozzáadhat további karakterisztikákat a spliterator-hoz. Például ha ismert, hogy a tömböt nem fogják tovább módosítani, akkor megadhat IMMUTABLE-t."
Itt újra feltűnik az IMMUTABLE következetlen használata: úgy beszél a specifikáció, mintha ennek bármilyen módosítás hiányát kellene jeleznie. Az Arrays.spliterator, Arrays.stream és a LongStream.of() viszont specifikáció szerint jelezni fog IMMUTABLE karakterisztikát, pedig ezek sem képesek garantálni, hogy a hívó nem fogja módosítani a tömbjét. Hacsak azt nem mondjuk, hogy egy elem beállítása nem szerkezeti módosítás, de akkor meg az egész megkülönböztetés értelmetlen, mivel a tömböket nem lehet szerkezetileg módosítani. A fenti dokumentáció továbbá egyértelműen nem mond NONNULL karakterisztikát, pedig nyilvánvaló, hogy a primitív értékek nem lehetnek null-ok.
Ha figyelmen kívül hagyjuk az összes problémát a CONCURRENT, IMMUTABLE vagy NONNULL esetén (ezeknek úgysincs következménye), akkor a felsorolásból marad az ötödik probléma: a SIZED és a skip/limit. Ez ismert probléma és Stream API skip és limit implementációjából adódik. Ez igaz végtelen stream és a limit kombinációjára is, hiszen a limit után ott is véges és ismert a méret, de a jelenlegi implementáció mégsem ad ilyen karakterisztikát vissza.
A boxed() viselkedését (3. eset) könnyű megmagyarázni. Ezt naivan így implementálták: .mapToObj(Long::valueOf), tehát egyszerűen elveszt minden korábbi információt, mivel a mapToObj nem feltételezheti, hogy az eredmény továbbra is rendezett vagy distinct lesz. A Java 9-ben ezt egyébként már kijavították: ott a LongStream.range(0,10).boxed()-nak már SUBSIZED|SIZED|ORDERED|SORTED|DISTINCT karakterisztikája van. (Egyébként néhány korán kiderült Java 8 problémát a későbbi frissítések is megoldottak, ezekről ezért nem is szólok ebben a cikkben. Ha el szeretnénk kerülni minél több JDK bugot, akkor érdemes minél frissebb verziót használni a Java 8-ból is.)
| Stream létrehozása | Közbülső művelet | Lezáró művelet |
|---|---|---|
| Collection | BaseStream | BaseStream |
| stream() | sequential() | iterator() |
| parallelStream() | parallel() | spliterator() |
| unordered() | ||
| Stream | onClose(...) | Stream |
| IntStream | forEach(...) | |
| LongStream | Stream | forEachOrdered(...) |
| DoubleStream | filter(...) | toArray(...) |
| static generate(...) [rendezetlen] | map(..) | reduce(...) |
| static of(...) | mapToInt(...) | collect(...) |
| static empty() | mapToLong(...) | min(...) |
| static iterate(...) | mapToDouble(...) | max(...) |
| static concat(...) | flatMap(...) | count() |
| static builder() | flatMapToInt(...) | anyMatch(...) [rövidzár] |
| flatMapToLong(...) | allMatch(...) [rövidzár] | |
| IntStream | flatMapToDouble(...) | noneMatch(...) [rövidzár] |
| LongStream | distinct() [állapottartó] | findFirst() [rövidzár] |
| static range(...) | sorted() [állapottartó] | findAny() [rövidzár, nemdeterminisztikus] |
| static rangeClosed(...) | peek(...) | |
| limit(...) [állapottartó, rövidzár] | Az IntStream, LongStream és DoubleStream rendelkezik a Stream lezáró műveleteivel, de eltérő paraméterekkel. Alább a plusz metódusok. | |
| Arrays | skip(...) [állapottartó] | |
| static stream(...) | ||
| Az IntStream, LongStream és DoubleStream rendelkezik a Stream metódusaival, de eltérő paraméterekkel. Alább a plusz metódusok. | IntStream | |
| BufferedReader | LongStream | |
| lines() | DoubleStream | |
| IntStream | sum() | |
| Files | LongStream | average() |
| static lines(...) | DoubleStream | summaryStatistics() |
| static list(...) | boxed() | |
| static walk(...) | mapToObj(...) | |
| static find(...) | ||
| IntStream | ||
| JarFile | LongStream | |
| stream() | asDoubleStream() | |
| range(...) | ||
| ZipFile | rangeClosed(...) | |
| stream() | ||
| IntStream | ||
| Pattern | asLongStream() | |
| splitAsStream(...) | ||
| SplittableRandom | ||
| ints(...) [rendezetlen] | ||
| longs(...) [rendezetlen] | ||
| doubles(...) [rendezetlen] | ||
| Random | ||
| ThreadLocalRandom | ||
| ints(...) | ||
| longs(...) | ||
| doubles(...) | ||
| BitSet | ||
| stream() | ||
| CharSequence (String) | ||
| chars() | ||
| codePoints() | ||
| StreamSupport (alacsony szintű) | ||
| static doubleStream(...) | ||
| static intStream(...) | ||
| static longStream(...) | ||
| static stream(...) |
Ebben a részben néhány olyan lambdákkal és stream-ekkel kapcsolatos érdekességet fogok bemutatni amelyek egy Java programozó életében mindennap felmerülhetnek.
 Bár a Java 8 témájához nem kapcsolódik közvetlenül, de ezen a ponton érdemes felidézni egy kis
érdekességet. Amint azt bizonyára mindenki tudja, a Java-ban minden eldobható kivétel a Throwable osztályból származik. Először is két alcsoport:
Bár a Java 8 témájához nem kapcsolódik közvetlenül, de ezen a ponton érdemes felidézni egy kis
érdekességet. Amint azt bizonyára mindenki tudja, a Java-ban minden eldobható kivétel a Throwable osztályból származik. Először is két alcsoport:
Az Exception osztályból származnak a futásidejű kivételek (RuntimeException). Ezekre némileg más szabályok vonatkoznak mint a többire. És itt lép be a Java egyik sajátossága, a kivételtípusok két csoportra osztása:
Ellenőrzött kivételek (checked exception): Exception osztályból származó kivétel, de nem RuntimeException leszármazott. Olyan hibákat reprezentálnak, amik a program aktuális végrehajtásán kívül eső érvénytelen állapotok (felhasználótól érkező hibás adat, adatbázis problémák, hálózati kiesések, hiányzó fájlok). A metódusoknak kötelező valahogyan kezelniük ezt a típust: jelezniük kell a throws záradékban vagy pedig helyileg kell kezelniük. Az ábrán zölddel jelölt.
Nem ellenőrzött kivételek (unchecked exception): Error osztályból vagy pedig a RuntimeException osztályból származik. Programhibákat jelez. A Java kitalálói szerint: "nem ellenőrzött kivételek olyan állapotokat reprezentálnak, amik általánosságban véve a programunkban lévő hibákra utalnak és futásidőben ésszerűen nem kezelhetőek." A metódusoknak nem kötelező az aláírásukban a throws záradékban jelezni ezeket. (De megtehetik.) Az ábrán pirossal jelölt.
A kivételek ilyen felosztása Java specialitás, más széles körben elterjedt nyelvben (C++, JavaScript, C#, Python, ObjectPascal) nincs ilyen csoportosítás. A Java-ban már régóta fennálló vallásháború, hogy szükség van-e erre a felosztásra vagy sem. A szakirodalomban a nem ellenőrzött kivételeket egyébként néha "futásidejű kivételeknek" is szokták nevezni (ami eléggé félrevezető).
Mivel a Throwable és az Exception osztályok mindkét típusú osztálynak ősei, ezért ezek mindkét csoportba beletartoznak, vagyis egyszerre ellenőrzött és nem ellenőrzött kivételek is! Ez a tény nem tartozik a Java legkedveltebb tulajdonságai közé. Ha ugyanis Exception-t vagy Throwable-t
Ez azért van, mert amikor dobom, nem lehet nem ellenőrzött kivétel, mert az Exception nem egyfajta RuntimeException, tehát ellenőrzött. Amikor elkapok valamit Exception-ként akkor viszont lehet, hogy az objektum tényleges típusa RuntimeException volt, mert az is Exception. Ilyenkor tehát lehet, hogy nem ellenőrzött. De az is lehet, hogy az.
Álljon itt mementóként egy rövidke példa ennek demonstrálására! Amikor egy Exception típusú kivételt dobunk és a függvényben nem kapjuk el, akkor kötelező deklarálni a záradékban:
package hu.egalizer.java8; public class NagyBuli { public void buliVan(boolean statusz) throws Exception { if (statusz) { System.out.println("Buli van!"); } else { throw new Exception("Baj van, nem buli!"); } } }
Ha pedig deklarálunk Exception típusú kivételt a függvény aláírásában, akkor az is ellenőrzött. A következő program nem fog lefordulni:
package hu.egalizer.java8; public class NagyBuli { public static void main(String[] args) { new NagyBuli().buliVan(true); } public void buliVan(boolean statusz) throws Exception { if (statusz) { System.out.println("Buli van!"); } else { throw new Exception("Baj van, nem buli!"); } } }
A main-ben el kellene kapni az Exception kivételt, vagy pedig itt is deklarálnunk kellene az aláírásban.
Végül pedig egy Java API-val kapcsolatos bónusz kérdés! Az alábbi két kódsor két eltérő típusú kivételt dob. Mindkettő nem ellenőrzött, de itt most nem ez a lényeg, hanem az: vajon miért dob a két kódsor két különböző kivételt? Hiszen lényegében ugyanarra szolgálnak!
Integer.parseInt(null); // throws java.lang.NumberFormatException: null Double.parseDouble(null); // throws java.lang.NullPointerException
Nos a válasz az, hogy azért, mert a JDK sem tökéletes. A két metódust két különböző fejlesztő csinálta és úgy látszik más elképzelésük volt róla, hogy mit kell ilyenkor dobni. (A nyájas olvasó nyugodtan kipróbálhatja, nem fog csalódni, valóban így viselkednek!)
Talán eddig nem is tűnt fel, de a JDK-ban lévő funkcionális interfészek bizony nem támogatják az ellenőrzött kivételeket. Ez hamar kiderül, ha egy funkcionális interfésznek (vagy stream művelet viselkedési paraméterének) olyan lambdát akarunk megadni ami ellenőrzött kivételt dobhat.
Tegyük fel, hogy egy CSV fájlban tároljuk a legóadatbázisunk adatait. A LegoSet osztály kiegészül két metódussal (ezek törzsét most nem részletezem, a példához lényegtelen):
package hu.egalizer.java8.lego; [...] public class LegoSet { [...] /** * A LegoSet-et átalakítja CSV-ben tárolható sztringgé. * * @return CSV-sor */ public String toCsvString() { [...] } /** * Egy CSV-ben lévő sort alakít át LegoSet osztállyá * * @param line * CSV-ből beolvasott egy sor * @return A CSV sornak megfelelő LegoSet osztály * @throws LegoParseException: * ellenőrzött kivételt dobunk, ha a paraméterként megadott sztring feldolgozása nem lehetséges */ public static LegoSet parseFromCsvString(String line) throws LegoParseException { [...] } [...] }
A CSV fájl írása során rögtön problémába ütközünk: a BufferedWriter nem használható! Ez a kód nem fordul le:
public static void saveToCSW(LegoDatabase database) {
Path path = Paths.get(FILENAME);
try (BufferedWriter writer = Files.newBufferedWriter(path)) {
Stream<String> stream = database.mySets.stream().map(set -> set.toCsvString());
stream.forEachOrdered(writer::write);
} catch (IOException ex) {
// TODO kivételkezelés
ex.printStackTrace();
}
}
Hiába van try-catch szerkezetben, a stream.forEachOrdered(writer::write) sor hibás, mert a writer::write metódus is IOException-t szeretne dobni, de mivel a forEachOrdered paramétereként várt Consumer funkcionális interfész accept metódusa nem deklarál semmilyen ellenőrzött kivételt, ezért a fordító nem tud metódusreferenciát gyártani Consumer interfészhez. Ezt a problémát ugyan még meg tudjuk kerülni: már régóta létezik a PrintWriter osztály, amivel szintén tudunk szöveges fájlt írni, de nem dob kivételt, hanem utólag tudjuk a sikerességet ellenőrizni. Ez a kód már lefordul (sőt, le is fut):
public static void saveToCSW(LegoDatabase database) {
Stream<String> stream = database.mySets.stream().map(set -> set.toCsvString());
try (PrintWriter pw = new PrintWriter(FILENAME, "UTF-8")) {
stream.forEachOrdered(pw::println);
if (pw.checkError()) {
// TODO hibakezelés
}
} catch (FileNotFoundException | UnsupportedEncodingException e) {
// TODO kivételkezelés
e.printStackTrace();
}
}
Most már van CSV fájlunk. A problémát persze nem oldottuk meg, csak megkerültük, de meszire így se jutunk. A beolvasáshoz a parseFromCsvString metódust és a már ismerős I/O stream-et szeretnénk használni:
public static void loadFromCSW(LegoDatabase database) { Path path = Paths.get(FILENAME); try (Stream<String> stream = Files.lines(path)) { database.mySets = stream.onClose(() -> System.out.println("Beolvasás kész!")).map(LegoSet::parseFromCsvString).collect(Collectors.toList()); } catch (IOException ex) { ex.printStackTrace(); } }
Ez a kód szintén nem fordul le, mégpedig ugyanazon okból amiért az előbbi BufferedWriter-es sem (csak annyi a különbség hogy a map Function funkcionális interfészt vár). A LegoSet::parseFromCsvString a throws záradékban definiál LegoParseException ellenőrzött kivételt, ezt viszont már nem tudjuk (és nem akarjuk) megkerülni. Az Eclipse Oxygen a map paraméterét kérésre ilyen szépséggé alakítja át (hibásan, mert a return-t meg kifelejti a kivétel után, tehát ez szintén nem fog lefordulni):
public static void loadFromCSW(LegoDatabase database) { Path path = Paths.get(FILENAME); try (Stream<String> stream = Files.lines(path)) { database.mySets = stream.onClose(() -> System.out.println("Beolvasás kész!")).map(t -> { try { return LegoSet.parseFromCsvString(t); } catch (LegoParseException e) { e.printStackTrace(); } }).collect(Collectors.toList()); } catch (IOException ex) { ex.printStackTrace(); } }
Persze átalakíthatjuk a catch törzsét erre:
throw new RuntimeException(e);
és így már nem ellenőrzött kivételt fog dobni, de ettől se lesz sokkal szebb a kód. Most már azt hiszem érthető, mi a probléma azzal, hogy a funkcionális interfészek nem támogatják az ellenőrzött kivételeket.
Sajnos a problémára nincs kézenfekvő megoldás. Mindenképpen be kell vezetnünk egy olyan funkcionális interfészt ami tud kivételt dobni, viszont annak nem ellenőrzött kivételnek kell lennie, hogy a stream műveletek is elfogadják. A nyakatekertebbnél nyakatekertebb lehetőségek közül talán még az alábbi a leginkább átlátható.
Csináljunk egy funkcionális interfészt, ami lényegében megfelel a Function-nek, de tud bármilyen (ellenőrzött és nem ellenőrzött) kivételt dobni:
package hu.egalizer.java8.lego; @FunctionalInterface public interface FunctionWithThrows<T, R> { R apply(T t) throws Exception; }
Ezután bevezetünk egy "leképező" függvényt ami ezt az új funkcionális interfészünket beteszi a JDK-beli Function-be úgy, hogy az esetlegesen dobott kivételt RuntimeException kivételként, vagyis nem ellenőrzöttként dobja tovább. Így a Function-nál nem lesz baj a throws záradék hiányából:
public static <T, R> Function<T, R> mapCheckedToUnchecked(FunctionWithThrows<T, R> wrappable) {
return t -> {
try {
return wrappable.apply(t);
} catch (Exception exception) {
throw new RuntimeException(exception);
}
};
}
Így pedig már használhatjuk a stream-et:
database.mySets = stream
.onClose(() -> System.out.println("Beolvasás kész!"))
.map(mapCheckedToUnchecked(LegoSet::parseFromCsvString))
.collect(Collectors.toList());
Ha történetesen egy feladatban olyan műveletet kellene használnunk, ami Supplier interfészt vár, de ott is ellenőrzött kivételt akarunk dobni, akkor még plusz interfész bevezetése sem szükséges, mert a JDK régóta meglévő Callable funkcionális interfésze ugyanarra való, csak az már "gyárilag" rendelkezik throws Exception záradékkal, tehát csak a leképező függvényre van szükségünk.
Ez a megoldás - bár széles körben elterjedt - egyszerűsége ellenére elég csúnya. Az ellenőrzött kivételek épp arra valók, hogy a figyelmeztessék a kódolót olyan feltétel lehetséges bekövetkeztére, amit kezelnie kell. Ezzel a megoldással szépen kitöröljük ezt a figyelmeztetést és innentől kezdve nem ellenőrzött kivételekbe csomagolt ellenőrzött kivételek bukkanhatnak fel a kód bármely részén. Ráadásul a catch ágban most már nem is tudunk közvetlenül például LegoParseException kivételre hivatkozni, hiszen olyat a mapper nem dob! (Legfeljebb várhatunk RuntimeException-t és nézegethetjük, hogy mi van benne...) Tehát ez nem fordul le:
try {
mapCheckedToUnchecked(s -> {
throw new LegoParseException();
});
} catch (LegoParseException lpe) { // ilyen kivétel definíció szerint sosem dobódik
// a try blokkból - legalábbis a fordító szerint
lpe.printStackTrace();
}
Nos ez utóbbi problémán lehet valamennyire segíteni, ha például a stream-et átvisszük egy olyan metóduson ami nem csinál mást, mint visszaadja a paraméterét és ezen kívül még van throws záradéka. Vagyis lényegében az egyik helyről eltüntetett throws záradékot átrakjuk máshová... Az ötlet alapja tehát egy ilyen metódus:
public static <R, E extends Exception> Stream<R> of(final Stream<R> stream) throws E {
return stream;
}
Ezután pedig csak azt kellene megoldani, hogy a mapper most már ne a RuntimeException-be csomagolt kivételt dobja tovább. Java 8-cal ez is lehetséges!
A Java 8 a kivételek típuskövetkeztetésében is bevezetett ugyanis némi változtatást. Ez a változás másoknak is feltűnt. A stackoverflow bejegyzést író kolléga ugyanis a következő furcsaságot tapasztalta:
static void sneakyTest() { Exception e = new Exception(); sneakyThrow(e); // itt nincs gond nonSneakyThrow(e); // nem fog lefordulni, mert: // "unreported exception Exception; must be caught or declared to be thrown" } static <T extends Throwable> void sneakyThrow(Throwable t) throws T { throw (T) t; } static <T extends Throwable> void nonSneakyThrow(T t) throws T { throw t; }
Mi teszi lehetővé, hogy a sneakyThrow hívásban dobott kivétel nem ellenőrzött, a másikban dobott viszont igen? (Ezeket a speciális eseteket, amikor ellenőrzött kivételből nem ellenőrzöttet csinálunk, az angol oldalakon általában sneaky throw-nak hívják.)
A 8-as Java nyelvi specifikáció nevű könnyed délutáni olvasmányban van a megfejtés (18.1.3-as és 18.4-es fejezet): a throws záradék valójában csak a metódus metaadata, futás közben semmiféle szerepe nincs. Ha pedig a típuskövetkeztetés során azt látja a fordító, hogy a T típusa Exception, Throwable vagy Object, akkor automatikusan RuntimeException-nek, vagyis nem ellenőrzött kivételnek fogja tekinteni. Mivel ellenőrzött kivételeket csak a fordító kezel, ha lefordult a kód, onnantól kezdve nagy probléma nincs. Ez a 8-as Java előtt még nem így volt: egy 7-es fordító a sneakyThrow hívásnál is panaszkodna arra, hogy a metódus által adott throws záradék kivétele nincs elkapva.
De mi is történik a 8-as Java esetén? Nézzük először a nonSneakyThrow hívást: a fordító látja, hogy a metódust Exception típusú paraméterrel hívjuk meg. A T típusparaméter deklarációjának (T extends Exception) ez megfelel, tehát nincs probléma. A fordító ki tudja következtetni azt is, hogy ha az átadott paraméter T==Exception típusú, akkor a throws T záradékban is Exception típus a T. Azt pedig tudjuk, hogy az Exception (és a Throwable) ha dobjuk, akkor ellenőrzött kivétel. Mivel a nonSneakyThrow ezek szerint ellenőrzött kivételt dob, de a hívó azt nem kapja el, ezért nem fog lefordulni az a sor.
Na és mi van a sneakyThrow metódussal? Az első trükk, hogy átírtuk a paramétert T típusról Exception típusra. A hívás során nem lesz probléma, az aktuális paraméter is Exception típusú. A fordító azonban semmiből nem tudja kikövetkeztetni a T típusparaméter aktuális értékét! Annyit tud, hogy az Exception. A fenti definíció szerint viszont tudjuk, hogy ez esetben azt Java 8 óta a fordító automatikusan RuntimeException-nek fogja tekinteni. Vagyis a throws T záradék a fordító szerint nem ellenőrzött kivételt fog dobni, tehát nem kötelező elkapni. A kód pedig lefordul. A fenti definíció értelmében akkor is lefordul, ha mondjuk a metódus definíciójában a T típusparamétert Throwable-ből származtatjuk. Ha viszont a paraméterben átírjuk az Exception t definícót T t-re akkor már az első eset lép érvénybe: a fordító már ki tudja következtetni, hogy a T aktuális típusa Exception, vagyis onnantól ellenőrzött kivétel lesz, tehát ez sem fog lefordulni.
Tehát a sneakyThrow metódust így is hívhatjuk, mert az IOExceptzion ellenőrzött kivételből is nem ellenőrzöttet csinál:
IOException e = new IOException(); sneakyThrow(e);
Visszatérve a problémára: ezzel a megoldással ki tudjuk cselezni a fordítót, hogy immár valóban LegoParseException dobódjon a mapCheckedToUnchecked metódusból. Az átláthatóság kedvéért tegyük ki most már az egész kivételekkel foglalkozó kódot egy külön osztályba:
package hu.egalizer.java8.lego; import java.util.stream.Stream; public class ExceptionMapper { public static <R, E extends Exception> Stream<R> of(Stream<R> stream) throws E { return stream; } public static <R, E extends Exception> R rethrow(Exception ex) throws E { throw (E) ex; } @FunctionalInterface public interface FunctionWithThrows<R, T> { R apply(T t) throws Exception; } public static <R, T> R mapCheckedToUnchecked(FunctionWithThrows<R, T> wrappable, T t) { try { return wrappable.apply(t); } catch (Exception ex) { return rethrow(ex); } } }
Meghagytuk a map-hez szükséges FunctionWithThrows funkcionális interfészt, a lambda kifejezést most már újra a hívó adja meg, itt pedig már nem RuntimeException-t fogunk dobni, hanem Exception-t. Ezt a típustörléssel meg tudjuk tenni a rethrow metódusban. Bár a fordító panaszkodni fog: "Note: hu\egalizer\java8\lego\ExceptionMapper.java uses unchecked or unsafe operations." de rá se rántsunk, mert működik. Ezzel a következőképp tudjuk átírni a CSV beolvasó metódusunkat:
public static void loadFromCSW(LegoDatabase database) { Path path = Paths.get(FILENAME); try (Stream<String> stream = Files.lines(path)) { database.mySets = ExceptionMapper.<String, LegoParseException> of(stream).onClose(() -> System.out.println("Beolvasás kész!")) .map(s -> ExceptionMapper.mapCheckedToUnchecked(LegoSet::parseFromCsvString, s)).collect(Collectors.toList()); } catch (IOException | LegoParseException ioe) { ioe.printStackTrace(); } }
Vagyis az ExceptionMapper.<String, LegoParseException> of(stream) kifejezés miatt fel kell vennünk a catch ágba a LegoParseException-t, viszont azt a mapCheckedToUnchecked fogja dobni sima Exception-né szárítva, tehát nem ellenőrzötté (unchecked) téve. A catch pedig már el tudja kapni (hiszen futás közben nem számít a nem ellenőrzött-ellenőrzött különbség). Az ExceptionMapper osztályt ezek után már igény szerint bármilyen funkcionális interfész bevezetésével ki tudjuk egészíteni.
Egy generikus kifejezés több kötéssel is definiálható az & jellel: <T extends A & B & C & ... Z>. Ezt a fajta generikus paraméterdefiníciót ritkán használjuk, viszont korlátai miatt van némi hatása a lambda kifejezésekre:
A második megszorítás eltérő módon viselkedik fordítási időben és futásidőben, amikor a lambda kifejezések befűzése megtörténik. Ezt a következő példakóddal elő lehet hozni:
package hu.egalizer.java8; import java.util.function.IntConsumer; import java.util.function.IntSupplier; final class MutableInteger extends Number implements IntSupplier, IntConsumer { private int value; public MutableInteger(int value) { this.value = value; } @Override public int intValue() { return value; } @Override public long longValue() { return value; } @Override public float floatValue() { return value; } @Override public double doubleValue() { return value; } @Override public int getAsInt() { return intValue(); } @Override public void accept(int value) { this.value = value; } }
package hu.egalizer.java8; import java.util.Arrays; import java.util.Collection; import java.util.List; import java.util.OptionalInt; import java.util.function.IntSupplier; public class MultipleBoundMess { public static void main(String[] args) { final List<MutableInteger> integers = Arrays.asList(new MutableInteger(1), new MutableInteger(2)); final int min = findMin(integers).orElse(Integer.MIN_VALUE); System.out.println(min); } static <T extends Number & IntSupplier> OptionalInt findMin(final Collection<T> elements) { return elements.stream().mapToInt(IntSupplier::getAsInt).min(); } }
A kód hibátlan és sikeresen le is fordul. A MutableInteger osztály kielégíti a T többszörös kötését:
Futás közben azonban kivételt kapunk:
Exception in thread "main" java.lang.BootstrapMethodError: call site initialization exception at java.lang.invoke.CallSite.makeSite(CallSite.java:341) at java.lang.invoke.MethodHandleNatives.linkCallSiteImpl(MethodHandleNatives.java:307) at java.lang.invoke.MethodHandleNatives.linkCallSite(MethodHandleNatives.java:297) at hu.egalizer.java8.MultipleBoundMess.findMin(MultipleBoundMess.java:17) at hu.egalizer.java8.MultipleBoundMess.main(MultipleBoundMess.java:12) Caused by: java.lang.invoke.LambdaConversionException: Invalid receiver type class java.lang.Number; not a subtype of implementation type interface java.util.function.IntSupplier at java.lang.invoke.AbstractValidatingLambdaMetafactory.validateMetafactoryArgs(AbstractValidatingLambdaMetafactory.java:233) at java.lang.invoke.LambdaMetafactory.metafactory(LambdaMetafactory.java:303) at java.lang.invoke.CallSite.makeSite(CallSite.java:302) ... 4 more
A kivételt azért kapjuk, mert egy stream csővezetéke csak nyers típust fogad, ami a findMin metódus generikus definíciója szerint Number, hiszen az az első. Ez pedig nem implementálja közvetlenül az IntSupplier-t. A probléma kiküszöbölhető egy paraméter típus explicit definíciójával a metódus referenciához használt különálló metódusban:
private static int getInt(final IntSupplier supplier) { return supplier.getAsInt(); } static <T extends Number & IntSupplier> OptionalInt findMin(final Collection<T> elements) { return elements.stream().mapToInt(MultipleBoundMess::getInt).min(); }
Kibővített tömbfeldolgozás
A Java 8 a régi jó java.util.Arrays osztályba 50 új metódust hozott. Ezek 6 csoportra oszthatók:
int[] intArr = new int[100]; Arrays.setAll(intArr, i -> i % 2); Arrays.stream(intArr).forEach(System.out::println);
int[] intArr = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; Arrays.parallelPrefix(intArr, (a, b) -> a + b);
Az intArr tartalma a művelet után:
[1, 3, 6, 10, 15, 21, 28, 36, 45, 55]
A parallelPrefix tehát bejárja a tömböt és két operandust vár, az első a tömb aktuális eleme, a második pedig a következő, elvégzi rajtuk az operátort, majd az eredménnyel lecseréli a második elemet. A műveletnek asszociatívnak és mellékhatás-mentesnek kell lennie, mert a párhuzamos feldolgozást csak így lehet elvégezni. Ha ennek nem felel meg, akkor a metódus futásának végeredménye; vagyis a tömb tartalma meghatározatlan lesz. A parallelPrefix is a három primitív típusra és T osztály típusú tömbre van implementálva. Ha a műveletet csak a tömb egy résztömbjére szeretnénk elvégezni, azt is megtehetjük ha megadjuk a kívánt tömbindexeket:
int[] intArr = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; Arrays.parallelPrefix(intArr, 5, 8, (a, b) -> a + b);
Eredmény:
[1, 2, 3, 4, 5, 6, 13, 21, 9, 10]
Jobb HashMap
A DoS támadások egyik kedvenc módszere, hogy a szervereknek tömegesen küldenek olyan String objektumokat, amelyeknek ugyanaz a hash kódja. Ez a támadási módszer nem túl jól érintette a Java 7 HashMap implementációját, de a Java 8-ban ezt is megváltoztatták: belsőleg már nem lista, hanem bináris fa tárolja az azonos hash kódú elemeket. Ez ellenállóbbá tette a DoS támadásokkal szemben. Nem árt tudni, hogy az új implementáció csak akkor működik igazán hatékonyan, ha a HashTáblánk kulcsai implementálják a Comparable interfészt (mivel a kulcsok általában String-ek, ezzel legtöbbször nincs is teendő). (De akárhogy is van, még mindig igaz, hogy sok, azonos hashCode értéket adó kulcs használata a biztos mód bármilyen HashMap implementáció teljesítményének lerontására.)
StringJoiner
Az új java.util.StringJoiner segítségével könnyen lehet olyan karaktersorozatokat létrehozni, amiket egy határoló karakter választ el és lehetőség van arra is, hogy az eredmény megadott prefixszel kezdődjön és megadott utótaggal (suffix) végződön. Ha még nem adtunk semmit a StringJoiner-hez, a toString metódusa alapértelmezetten a prefix+suffix összeget fogja visszaadni. Kivéve ha a setEmptyValue metódussal beállítunk egy üres értéket, mert akkor a megadott emptyValue értéket adja vissza.
// StringJoiner létrehozása: a konstruktornak megadjuk az elválasztót, elő- és utótagot. // Az elő- és utótag el is hagyható. StringJoiner sj = new StringJoiner(";", "[", "]"); sj.add("első").add("második").add("harmadik"); String vegeredmeny = sj.toString();// eredmény: [első;második;harmadik]
A merge metódussal két StringJoiner-t lehet összefűzni, ilyenkor a paraméter elő- és utótagja figyelmen kívül lesz hagyva:
StringJoiner sj = new StringJoiner(";", "[", "]"); sj.add("első").add("második").add("harmadik"); StringJoiner sj2 = new StringJoiner(",", "{", "}"); sj2.add("negyedik").add("ötödik").add("hatodik"); sj.merge(sj2); String vegeredmeny = sj.toString();// eredmény: [első;második;harmadik;negyedik,ötödik,hatodik]
A Java 8 nem hagyta érintetlenül a java.util.concurrent csomagot sem. A változások nagy része a lambdákhoz és a streamekhez kötődik, de sokat javult a konkurencia kezelés is:
Egyébként a legtöbb, konkurenciával foglalkozó régi és új osztályt is a stream fejezetben már megismert Douglas Lea professzor írta. (Ilyen például a StampedLock, a CompletableFuture és társai, a java.util.concurrent.atomic csomag nagy része, a ForkJoinPool, az Executor, stb.)
Common pool
Java 8-ban a java.util.concurrent.ForkJoinPool három új metódussal lett gazdagabb. Az awaitQuiescence(long timeout, TimeUnit unit) metódussal arra várakozhatunk, hogy a pool-ban lévő minden taszk isQuiescent() állapota true legyen (vagyis mindegyik idle állapotba kerüljön). Ez esetben az awaitQuiescence is true értékkel tér vissza. Ha viszont a paraméterben megadott timeout ideig várt és még nem minden taszk került ebbe az állapotba akkor false-t ad vissza.
A másik újdonság a globális, általános használatú közös pool támogatása. Egy java.util.concurrent.ForkJoinPool példány megszerzéséhez immár a legegyszerűbb mód a statikus ForkJoinPool.commonPool() metódus meghívása. A közös pool párhuzamossági beállítását (ami alapértelmezetten az elérhető processzormagok száma) a szintén statikus getCommonPoolParallelism() metódussal kérdezhetjük le. Konstruktorokkal persze továbbra is létrehozhatunk saját poolt. A később részletezendő szintén Java 8 újdonságnak számító CompletableFuture osztály például erősen épít a ForkJoinPool.commonPool() használatára.
Akkumulátor és adder
A java.util.concurrent.atomic csomagba bekerült négy új osztály amelyek segítik a szálak közötti adatok kezelését:
Alább a két long kezelő osztályt mutatom be, de az elmondottak értelemszerűen vonatkoznak a double kezelőkre is.
Tegyük fel, hogy a legó nyilvántartó programot webes felületűvé alakítjuk. A felhasználók kézzel felvehetik saját készleteiket. Van egy üzenőfal, ahol folyamatosan látható, hogy milyen elemszámú volt az aznap addig felvett legnagyobb elemszámú készlet. Vagyis több szál által kezelt értékek közül kellene folyamatosan számon tartanunk a példa szerint épp a legnagyobbat. Ehhez tárolnunk kell egy olyan változót amit minden szál elér és frissíthet (legnagobb elemszám) és bizonyos időben lekérdezzük az értékét. Erre volt jó régen az AtomicLong, amiben szálbiztosan tudtunk tárolni egy értéket. Nagy számú versengő szálnál viszont az AtomicLong nem túl hatékony, mert a frissítés idején zárolja a belső állapotát. Ezért jött a négy új típus.
A LongAccumulator típussal egy ilyen feladatot hatékonyabban meg tudunk oldani, ráadásul lambda kifejezéseket is tudunk használni. Az accumulator a külvilág felé egy, belsőleg egy vagy több változót tárol, amivel fenntart egy adott függvénnyel módosítható long (vagy double) értéket. Amikor módosítások (az accumulate(long) metódus) versenyeznek egymással a szálak között, a belsőleg tárolt változók halmaza dinamikusan nőhet így csökkentve a versengést. A get() (vagy ennek megfelelően a longValue()) metódus visszaadja az aktuális értéket amit a frissítések által fenntartott változókból számít.
Ezt az osztályt érdemes alkalmazni az AtomicLong helyett amikor több szál használ és frissít egy közös értéket amit statisztika gyűjtésére nem pedig a szinkronizáció finomvezérlésére használunk. Alacsony versengés esetén a két osztálynak hasonló a működési karakterisztikája. Nagy versengés esetén viszont a LongAccumulator osztálynak nagyobb az áteresztőképessége azon az áron, hogy nagyobb a tárhely felhasználása is.
Az akkumulálás sorrendje viszont nem garantált a szálak között és nem lehet rá logikát építeni. Ez az osztály tehát csak olyan függvényekhez használható, ahol az akkumulálás sorrendje lényegtelen. A megadott accumulator függvénynek mellékhatás-mentesnek kell lennie, mert újra meghívódhat amikor a frissítések kísérletei sikertelenek a szálak közötti versengés miatt. Az osztály a függvényt az aktuális érték mint első paraméterrel hívja meg és a megadott frissítéssel mint második paraméter. Egy frissített maximáils érték tárolásához például Long::max-al érdemes példányosítani Long.MIN_VALUE identity értékkel.
Mind a négy új osztály a Number-ből származik, de nem definiálják az equals, hashCode és compareTo metódusokat mert a példányok mutable tulajdonságúak és így nem használhatók collection-ökben kulcsként.
A legónyilvántartó megoldásához tehát kell egy közös mező amit minden szál elér:
public static final LongAccumulator counter = new LongAccumulator(Long::max, 0);
A counter fogja tárolni a legnagyobb elemszámot. A konstruktornak megadunk egy kifejezést, amivel két érték közül el lehet dönteni, melyiket hagyjuk meg (a példában Long::max) és megadunk egy kezdőértéket is (0). Most így tudjuk immár szálbiztosan minden requesten belül frissíteni az értékét:
counter.accumulate(set.getPieceCount());
A már ismert set.getPieceCount() adja meg az aktuálisan felvett készlet elemszámát. A kiíráshoz pedig le tudjuk kérdezni az aktuálisan akkumulált értéket (a lekérdezéshez többféle visszatérési típusú metódusból is választhatunk.):
counter.get()
Tehát először létrejön a counter 0 kezdőértékkel. Az accumulate metódus különböző szálakból meghívódhat. Ha a híváskor a belsőleg tárolt előző érték éppen frissítés alatt van egy másik szálból (vagyis zárolt), akkor megpróbálkozik a következő tárolt érték frissítésével. Ha ilyen nincs, akkor egy új bejegyzés jön létre az új érték tárolására. A keretrendszer megpróbálja minden egyes híváskor alkalmazni a konstruktornak átadott kifejezést, de ha más szálak épp blokkolják a hívást, akkor nem várakozik rájuk, hanem feladja a kísérletet. Amikor végül meghívjuk a get() metódust, akkor a keretrendszer végigmegy az összes tárolt értéken és mindegyikre páronként alkalmazza a kifejezést is kiszámítja a végértéket. Mivel ez a számítás nem garantálja a sorrendet, ezért a lambda kifejezésünknek asszociatívnak kell lennie! Ez a módszer nagy sebességbeli előnyt jelenthet a korábbi Atomic típusokhoz.
A LongAdder pedig lényegében a LongAccumulator specializált változata. Csak paraméter nélküli konstruktora van ami 0 kezdőértékkel létrehoz egy osztályt. A new LongAdder() kifejezés ekvivalens a new LongAccumulator((x, y) -> x + y, 0L) kifejezéssel. A következő műveletei vannak:
A népszerű java.util.concurrent.ConcurrentHashMap osztályt teljesen újraírták és 43 új metódus került bele.
A ConcurrentHashMap a Hashtable szálbiztos változata és egyébként a konkurencia kezelésén kívül teljesen felcserélhető a kettő. De mire is jó?
Tegyük fel, hogy biztosítani kell a szálbiztosságot és előre tudjuk, hogy nagyon sok lesz az olvasás de kevés az írás. A HashMap gyors megoldás, de sajnos nem szálbiztos. A Hashtable ismerői tudják, hogy ilyen feladatra az sem tökéletes. Bár szálbizos, de elég rosszul muzsikál többszálú környezetben, mert az összes metódusa - a get()-et is beleértve - synchronized. Így bármely metódushívás esetén a többi, ugyanazt az objektumot használó szálnak várakoznia kell míg az aktuális hívás be nem fejeződik. Tehát egy írási művelet esetén az összes olvasás várakozik még akkor is ha nem is ugyanazzal a kulcssal foglalkoznak. Nos itt jön be a ConcurrentHashMap ami szintén szálbiztos, de a lekérdező műveletekben nincs zárolás és nem is támogatja a teljes tábla zárolását.
A ConcurrentHashMap korábbi, Java 7-es implementációja a zárolás optimalizálása érdekében ún. szegmenseket használt egy tömbbe rendezve:
final Segment<K,V>[] segments;
A szegmens tartalmazta a HashEntry-k tömbjét és egy szegmensből zárolás nélkül lehetett olvasni. Java 8-ban a szegmenseket felváltotta a Node, ami már közvetlenül tartalmazza a kulcs-érték párokat és láncolt listába van szervezve:
transient volatile Node<K,V>[] table;
...
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
A Node tábla bejegyzései az első beillesztéskor, lustán értékelődnek ki. Mindegyik bejegyzés a többitől függetlenül zárolható úgy, hogy a bejegyzés első Node-ját zároljuk (ezt persze maga az implementáció megcsinálja nekünk). A módosítási versengés minimálisra lett szorítva (az újraíráskor ez volt a fő cél). A lekérdező művelet (get) pedig már nem zárolja a map-et és a módosító műveletekkel (put, remove) átfedésben futhat. Egy lekérdezés a legutoljára befejezett módosítás eredményét adja vissza.
A következőket érdemes észben tartani a ConcurrentHashMap használatakor:
A ConcurrentHashMap háromféle tömeges műveletet támogat: forEach, search, reduce. Ezek biztonságosan és többnyire ésszerűen működnek még olyan map-eknél is amiket konkurensen módosít több szál. Mindhárom műveletnek négyféle változata van, amelyek funkcionális interfészeket (általában Function) várnak kulcs, érték, (kulcs,érték) vagy Map.Entry paraméterekkel (tömeges műveleteknél a Map.Entry objektumok nem támogatják a setValue metódust). A paraméterként megadott függvények helyessége nem szabad, hogy bármilyen rendezettségtől függjön sem pedig bármi olyan értéktől ami megváltozhat míg a számítás folyamatban van. Emellett asszociatívnak és kommutatívnak kell lennie. A forEach műveleteket kivéve pedig nem árt, ha mellékhatástól is mentesek.
A tömeges műveletek várnak egy parallelismThreshold paramétert is. Ha az aktuális map méret becsülhetően kisebb mint ez a küszöbérték, akor mindenképen soros lesz a feldolgozás. A párhuzamosságot a Long.MAX_VALUE paraméterrel iktathatjuk ki. 1 paraméterrel pedig maximális párhuzamosságot kapunk, ilyenkor a keretrendszer annyi partíciót hoz létre hogy teljesen kihasználja a ForkJoinPool.commonPool()-t.
Alább kifejtem a ConcurrentHashMap összes új funkcióját.
mappingCount: visszaadja a map méretét. Ezt ajánlott használni a size helyett, mivel long a visszatérési értéke és a ConcurrentSkipListMap int-nél nagyobb elemszámot is képes kezelni. A metódus eredménye inkább csak hozzávetőleges érték, hiszen a lekérdezés közben is lehetnek folyamatban lévő módosítások.
computeIfAbsent: korábban is létezett már a putIfAbsent metódus ami akkor illesztett be egy kulcs-érték párost ha a kulcs még nem szerepelt a map-ben. A Java 8 elhozta a computeIfAbsent metódust: ha a megadott kulcs még nincs a map-ben, akkor ez megpróbálja kiszámítani az értékét a paraméterként adott mappingFunction funkcionális interfésszel. Ha az eredmény nem null, akkor beteszi a map-be a kulccsal. Az egész metódushívás atomi, tehát a függvény egyszerre legfeljebb egy kulcsot fog a map-be tenni. A más szálaktól érkező módosító műveletek blokkolódhatnak a végrehajtás során ezért a számítást olyan egyszerűre és rövidre írjuk amennyire csak lehet. És természetesen nem szabad, hogy a map többi elemére hatással legyen.
Tekintsük a következő példakódot:
private Map<String, Object> myLittleMap = new ConcurrentHashMap<>(); ... public Object getAndCreateIfAbsent(String key) { Object value = myLittleMap.get(key); if (value == null) { value = new Object(); myLittleMap.put(key, value); } return value; }
A példa getAndCreateIfAbsent metódus megnézi, szerepel-e már a myLittleMap-ben a lekérdezni kívánt kulcs. Ha igen, visszaadja az értékét, ha nem akkor létrehozza majd visszaadja. Bár a konkurenciával a map-ben nincs gond, a fenti metódussal viszont lesz ha több külön szálból is meghívjuk. Könnyen galiba történhet ha véletlenül több szál vezérlése egyszerre ér az if kifejezéshez. Ha a metódust synchronized-dá tesszük az megoldja a problémát, de Java 8-ban a szép megoldás már a computeIfAbsent metódus használata, amivel az egész getAndCreateIfAbsent metódust kiválthatjuk:
Object value = myLittleMap.computeIfAbsent(key, k -> new Object());
Ez a kód rövidebb és tisztább, szárazabb, biztonságosabb érzést ad! A példa ráadásul arra is rávilágít, hogy a ConcurrentHashMap önmagában nem csodafegyver: az sem mindegy, hogyan használjuk.
A computeIfAbsent és egy LongAdder segítségével a skálázható, gyakoriságot számoló map-ek használata is egyszerű lesz. Legyen egy freqs map-ünk:
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>();
Ebben sztringek előfordulási gyakoriságát fogjuk számolni. Egy sztring hozzáadását a következő sor szépen lekezeli:
freqs.computeIfAbsent("új sztring", k -> new LongAdder()).increment();
computeIfPresent: akkor számol ki új értéket a remappingFunction paraméterrel, ha a megadott kulcs már létezik a collection-ben. Ha a remappingFunction eredménye null, akkor a kulcs törlődik a map-ből. Itt is célszerű az átadott lambda kifejezést egyszerűnek írni.
compute: az előzőekkel ellentétben ez nem foglalkozik vele, hogy a kulcs létezik-e már a map-ben vagy sem. A remappingFunction függvénnyel kiszámol egy új értéket és beteszi a megadott kulccsal. (Ha a kiszámolt érték netalán null lesz és korábban volt azzal a kulccsal más akkor meg törli azt.) A compute esetén a remappingFunction egy BiFunction, ahol az első paraméter a kulcs, a második a korábbi érték (ha volt):
Map<String, Object> myMap = new ConcurrentHashMap<>(); ... Object computed = myMap.compute("kulcs", (k, v) -> calculateValue());
merge: a compute metódusban nekünk kell kezelni azt az esetet, ha eltérő értéket szeretnénk amikor a map még nem tartalmazza az adott kulcsot és ha igen. A merge erre ad megoldást: ha a kulcs még nem szerepelt a map-ban akkor a második paraméter lesz az értéke. Ha már szerepelt, akkor hívódik meg a remappingFunction. Ez paraméterként megkapja a map-ben lévő korábbi értéket és a merge-nek megadott újat. Az eredményével felülíródik a map-ben lévő korábbi érték.
Map<String, Integer> myIntMap = new ConcurrentHashMap<>(); ... myIntMap.merge("kulcs", 2, (v1, v2) -> v1 * v2);
Ha a "kulcs" még nem szerepelt a myIntMap-ben akkor 2 értékkel betesszük, egyébként a korábbi értéket (v1) megszorozzuk v2-vel (ami ez esetben 2).
forEach: a ConcurrentHashMap 9 új forEach típusú metódust is kapott. Ezek 4 típusra oszthatók:
1. forEach
ConcurrentHashMap<String, LegoSet> myMap = new ConcurrentHashMap<>(mySets.stream().collect(Collectors.toMap(LegoSet::getName, (set) -> set))); myMap.forEach(Long.MAX_VALUE, (k, v) -> "A készletünk neve: " + v.getName(), System.out::println);
2. forEachEntry: az előzőekhez képest annyi a különbség, hogy az action itt nem kulcsot és értéket kap paraméterként, hanem egy Map.Entry példányt.
3. forEachKey: az action itt kulcsot kap paraméterként
4. forEachValue: az action itt értéket kap paraméterként
getOrDefault(Object key, V defaultValue): lekérdezés, ami a defaultValue-t adja vissza ha a key nem szerepel a collection-ünkben, egyébként pedig a hozzá tartozó értéket.
search(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> searchFunction): a legegyszerűbb keresés. Végigmegy a map-ben lévő bejegyzéseken, átadja a kulcsokat és értékeket a paraméterben megadott searchFunction-nek. Amint annak a visszatérési értéke nem null, a keresés megáll és visszaadja a searchFunction eredményét (vagy null-t ha egyáltalán nem volt ilyen). A parallelismThreshold már ismert paraméter. A searchEntries metódus searchFunction-je bejegyzéseket kap, a searchKeys metódus esetén kulcsokat, a searchValues esetén pedig értékeket.
replaceAll(BiFunction<? super K,? super V,? extends V> function): a map összes kulcs-érték párjával meghívja a function paramétert és annak eredményével lecseréli a korábbi értéket.
reduce: a ConcurrentHashMap 19 redukciós metódust tartalmaz. A redukció is várja a már ismert parallelismThreshold paramétert. Emellett ezek a metódusok várnak egy redukciós kifejezést is ami összegzi a transzformált elemeket. A redukciós kifejezés nem függhet a rendezettségtől.
A redukciós metódusok a következő csoportokba oszthatók:
Az alábbi példa szintén a legóadatbázisunkat használja: összeadja az összes készletünk elemeinek számát:
ConcurrentHashMap<String, LegoSet> myMap = new ConcurrentHashMap<>(mySets.stream().collect(Collectors.toMap(LegoSet::getName, (set) -> set))); int count = myMap.reduce(Long.MAX_VALUE, (k, v) -> v.getPieceCount(), (v1, v2) -> v1 + v2);
A fenti példa skaláris transformer kifejezést használva 0 kezdőértékkel:
int count = myMap.reduceToInt(Long.MAX_VALUE, (k, v) -> v.getPieceCount(), 0, (v1, v2) -> v1 + v2);
És természetesen mindebből létezik szintén Entry-ket, kulcsokat vagy értékeket feldolgozó változat is.
ConcurrentHashSet
A Java 8-ban ugyan nincs különálló ConcurrentHashSet, de azért létrehozhatunk ilyet a ConcurrentHashMap új statikus newKeySet() vagy newKeySet(int) metódusaival (ez utóbbival az alapértelmezett méretet is meg tudjuk adni):
Set<String> hashSet = ConcurrentHashMap.newKeySet();
A korábban is létező keySet(Object) példánymetódussal a map-ünk Set leképezését tudtuk megadni ahol csak a kulcsok voltak az érdekesek, a leképezett értékek nem voltak használatban vagy mindegyik ugyanolyan értéket tartalmazott. A newKeySet statikus metódusok viszont üres Set-et adnak vissza. Valójában a háttérben ezek is ConcurrentHashMap-re építenek, de az értékek belsőleg Boolean típusúak.
ConcurrentSkipListMap
Java 8-ban a ConcurrentSkipListMap is változott, ez is megkapta a ConcurrentHashMap új metódusai közül a következőket:
Ezeket fentebb már tárgyaltam, a működésük itt is ugyanaz.
Bizonyára mindenki ismeri a Java zárolási technikáit, de ha valaki esetleg mégsem, annak itt egy nagyon gyors összefoglaló (természetesen csak a felszínt kapargatva). Ennek fényében érthetőbb lesz a StampedLock.
Legismertebb a synchronized kulcsszó. Ezzel metódusokat vagy kódblokkokat tudunk megjelölni és a JVM egy monitornak hívott technika segítségével biztosítja, hogy a synchronized kódot egyszerre csak egy szál tudja végrehajtani (a többiek addig a synchronized utasításnál várakoznak). A synchronized újrahívható (reentrant) ami azt jelenti, hogy az aktuálisan benne futó szál újra meg tudja hívni ugyanazt a metódust anélkül hogy holtpontot kapnánk.
Mivel a synchronized nem minden feladatra optimális, a Lock interfész segítségével a JDK már eddig is biztosított más lehetőségeket is a zárolásra. A ReentrantLock a synchronized-hoz hasonló működésű kölcsönösen kizáró zárolás. Ahogy a neve is sugallja, ez is újrahívható. Használatának mintája:
Lock lock = new ReentrantLock(); ... lock.lock(); try { // zárolást igényló kódrészlet } finally { lock.unlock(); }
A zárolást a lock(), a feloldást az unlock() metódus végzi. Egyszerre csak egy szál szerezhet zárolást, minden további szál a lock() hívásnál várakozik, hogy az épp végrehajtó befejezze a feladatát. Fontos, hogy a zárolást igénylő kód try-catch blokkban legyen, különben bármely kivétel esetén a feloldás nem történne meg. Ez a fenti kódrészlet ugyanúgy szálbiztos, mint a synchronized kulcsszóval megvalósított, viszont a fejlesztőtől több odafigyelést igényel. Ugyanakkor nagyobb rugalmasságot is ad, ráadásul a ReentrantLock számos metódust biztosít a tulajdonságai lekérdezésére. Bővebben nem megyek bele, ez már az 1.5-ös Java óta létezik.
A ReadWriteLock egy másik típusú zárolás interfész, szintén az 1.5-ös Java óta. Az volt az alapötlete, hogy általában biztonságos dolog konkurensen olvasni módosítható változókat addig míg senki nem akarja azt írni is. Az olvasási zárolást ezért egyszerre több szál is megtarthatja, míg egyetlen szál sem kér írási zárolást. Ez növelheti az áteresztőképességet ha az olvasások sokkal gyakoribbak mint az írások. Ezt az interfészt a ReentrantReadWriteLock implementálja. Read lock megszerzése:
ReadWriteLock rwlock = new ReentrantReadWriteLock(); ... rwlock.readLock().lock(); try { // csak olvasni akarunk } finally { rwlock.readLock().unlock(); }
Write lock megszerzése ugyanígy megy, csak a writeLock() metódust kell meghívni.
A ReentrantReadWriteLock-nak számos hátulütője volt. Könnyen kiéheztetéses helyzetekhez vezetett (pláne ha rosszul használták), nem lehetett egy read lockot write lock-ká konvertálni és nem támogatta az optimistic read-eket. Az új java.util.concurrent.locks.StampedLock osztály megpróbálta kiküszöbölni ezeket a hiányosságokat és ún. képesség-alapú zárolást (capability-based lock) biztosít. Támogatja az olvasási és írási zárolásokat is és néhány egyszerű elv betartásával jobb teljesítményt biztosít.
A StampedLock belső állapota egy verziót és egy módot tartalmaz. A zárolási metódusok egy long típusú bélyeget (stamp) adnak vissza ami egy zárolási állapotnak megfelelő elérést reprezentál és vezérel. Ezzel a bélyeggel lehet ellenőrizni és feloldani a zárolást. A "try" metódusok pedig 0 értéket is visszaadhatnak ami azt jelzi, hogy a zárolás kérése nem sikerült. A zárolás feloldási és konverziós metódusoknak át kell adni a bélyeget paraméterként és hibát dobnak ha az nem egyezik a zárolás állapotával. A StampedLock három módot támogat:
StampedLock stamped = new StampedLock(); ... long stamp = stamped.readLock(); try { // valamit olvasunk } finally { stamped.unlockRead(stamp); }
ExecutorService executor = Executors.newFixedThreadPool(2); StampedLock lock = new StampedLock(); executor.submit(() -> { long stamp = lock.tryOptimisticRead(); try { System.out.println("Optimistic lock valid: " + lock.validate(stamp)); Thread.sleep(1000); System.out.println("Optimistic lock valid: " + lock.validate(stamp)); Thread.sleep(2000); System.out.println("Optimistic lock valid: " + lock.validate(stamp)); } catch (InterruptedException e) { // TODO kivételkezelés } finally { lock.unlock(stamp); } }); executor.submit(() -> { long stamp = lock.writeLock(); try { System.out.println("Write lock megszerezve"); Thread.sleep(2000); } catch (InterruptedException e) { // TODO kivételkezelés } finally { lock.unlock(stamp); System.out.println("Write lock feloldva"); } }); executor.shutdown();
A példa kimenete:
Optimistic lock valid: true Write lock megszerezve Optimistic lock valid: false Write lock feloldva Optimistic lock valid: false
Az optimistic lock azonnal a zárolás megszerzése után még érvényes. A normál read lock-kal ellentétben ez nem gátolja meg a másik szálat a write lock megszerzésétől. Ezután 1 másodpercre leállítjuk az első szálat, ezalatt a második megszerzi a write lockot. Ettől a ponttól kezdve az optimistic lock többé nem lesz érvényes. Még azután is érvénytelen marad miután a write lockot már megszüntettük. Tehát az ilyen típusú zárolásoknál minden esetben validálni kell a zárolást miután kiolvastuk egy megosztott módosítható változó értékét, hogy megbizonyosodjunk róla, az érték tutira érvényes.
Az optimistic lock használatának ajánlott mintája:
StampedLock lock = new StampedLock(); ... // megszerezzük az optimistic read "zárolás" bélyegét long stamp = lock.tryOptimisticRead(); // a kívánt mező értékeket (value1, value2, stb) beolvassuk lokális változókba double actualValue1 = value1, actualValue2 = value2;// ...stb // megnézzük, hogy közben nem lett-e write lock is kiadva if (!lock.validate(stamp)) { // ha menet közben lett write lock kiadva, akkor a megszerzett állapotunk nem biztos, hogy konzisztens // ilyenkor kérünk egy read lockot és újra kiolvassuk a szükséges értékeket a lokális változóinkba stamp = lock.readLock(); try { actualValue1 = value1; actualValue2 = value2; } finally { lock.unlockRead(stamp); } } // aztán a megszerzett értékekkel számolunk valamit, amit akarunk double result = calculate(actualValue1, actualValue2);
A StampedLock nem újrahívható, mint a synchronized, Lock vagy ReadWriteLock, úgyhogy a zárolt metódustörzsek jobb ha nem hívnak más, ismeretlen metódusokat amik esetleg megpróbálhatják újra megszerezni a zárolásokat (bár egyébként átadhatunk bélyegeket más metódusoknak amik felhasználhatják vagy átkonvertálhatják azokat). A StampedLock által generált bélyegek nem kriptográfiailag biztonságosak, vagyis egy érvényes bélyeget ki lehet találni. A bélyeg értékeket újra lehet hasznosítani nem hamarább mint egy év folyamatos használat után. Ennél hosszabb ideig használat vagy validálás nélkül megtartott bélyeg validálása hibát dobhat. A StampedLock objektumok szerializálhatóak, de mindig alapértelmezett zárolatlan állapotba deszerializálódnak, vagyis nem használhatók távoli zárolásokhoz.
A StampedLock rendelkezik "try" metódusokkal is amik segítségével feltételesen is kérhetünk zárolást illetve feltételesen konvertálhatunk a zárolási módok között (a "feltételesen" itt azt jelenti, hogy a művelet nem biztos, hogy sikeres lesz):
Az osztály három "as" metódust is tartalmaz, ami visszafelé kompatibilitást biztosít: a StampedLock-ból Lock vagy ReadWriteLock-ot csinálhatunk:
Az alábbi példában egy field nevű statikus változót használ közösen több szál. Egy szál működését mutatom be az executor-ban. Az elképzelt kívánt működés az, hogy ha a field-nek egy adott értéke van (0) akkor megváltoztatjuk 42-re. A példában megszerezzük a read lock-ot majd megnézzük, hogy a field értéke megfelelő-e. Ha igen, akkor megpróbálunk write lockba konvertálni. A try nem blokkol, ha nem sikerült, akkor 0 a visszatérési értéke. Ez esetben lezárjuk a read lockot majd most már a blokkoló writeLock metódussal szerzünk write lockot. Ezután beállítjuk a field értékét. Végül lezárjuk a lockot, a stamp mindenképpen a megfelelő bélyeget tartalmazza majd.
ExecutorService executor = Executors.newFixedThreadPool(2); StampedLock lock = new StampedLock(); executor.submit(() -> { long stamp = lock.readLock();// kizáró read lock megszerzése try { if (field == 0) {// ha a feltétel megfelelő long writeStamp = lock.tryConvertToWriteLock(stamp); if (writeStamp == 0L) { // ha nem sikerült átváltani lock.unlock(stamp); stamp = lock.writeLock(); } else { // ha sikerült átváltani stamp = writeStamp; } field = 42; } } finally { lock.unlock(stamp);// lehet write vagy read lock is } }); executor.shutdown();
A példában ugyan egy if vizsgálja, hogy megvan-e a kívánt feltétel, de ha mindenképpen szükséges a váltás és biztos, hogy az meg fog történni, akkor akár ciklussal is várakozhatunk rá:
ExecutorService executor = Executors.newFixedThreadPool(2); StampedLock lock = new StampedLock(); executor.submit(() -> { long stamp = lock.readLock();// kizáró read lock megszerzése try { while (field == 0) {// ha a feltétel megfelelő long writeStamp = lock.tryConvertToWriteLock(stamp); if (writeStamp == 0L) { // ha nem sikerült átváltani lock.unlock(stamp); stamp = lock.writeLock(); } else { // ha sikerült átváltani stamp = writeStamp; field = 42; break; } } } finally { lock.unlock(stamp);// lehet write vagy read lock is } }); executor.shutdown();
Ez azért is jó megoldás, mert ha nem sikerült átváltani akkor az explicit write lock megszerzése után újra megvizsgáljuk a feltételt, hiszen a writeStamp == 0L feltételvizsgálat alatt akár meg is változhatott a field értéke. A try metódus akkor már - mivel eleve write lock módban vagyunk - csak visszaadja ugyanazt a bélyeg értéket, nem változtat semmin. Végül pedig, történjen bármi is, mindenképpen feloldjuk a zárolást a finally részben.
A programvégrehajtást általában úgy képzeljük, mint adott lépések sorozatát. Az aszinkron végrehajtás viszont némileg eltér ettől az elképzeléstől. Aszinkron végrehajtáskor egy műveletet úgy indítunk el, hogy nem kell megvárnunk a befejeződését. Ez hasznos lehet erőforrásigényes feladatok esetén vagy amikor egy művelet várakozni kénytelen külső folyamatra (például fájlbeolvasás). Így a fő kód folytatni tudja a feladatát és csak akkor kéri el az aszonkron folyamat eredményét (ha van) amikor már feltétlenül szükséges. Aszinkron műveletek esetén lehetőség van annak megadására is, hogy amikor egy művelet végetért, milyen kód (callback) fusson le. Egy aszinkron műveletet a Java 8 terminológiája taszknak hív.
Java 5-ben jelent meg elsőként aszinkron számításokat segítő API: a Future interfész (és első implementációja, a FutureTask). Egy Future egy adott aszinkron számítást és eredményét reprezentálja. Az interfész egyszerű műveleteket biztosított: cancel a számítás megszakítására, get és get timeouttal az eredmény lekérdezésére valamint két állapotlekérdezés (isDone és isCancelled).
Az interfész sajnos messze volt a tökéletestől. Nem volt benne beépített hibakezelés, nem lehetett több Future-t kötegelten és egymásba fűzve kezelni, de a legnagyobb hátránya az volt, hogy nem értesített a befejeződéséről. A get metódus blokkolta a hívót amíg az eredmény elő nem állt - ha ez valami hiba miatt soha nem történt meg, akkor örökké. Volt ugyan timeout-ot használó változata is, illetve az isDone metódussal le lehetett kérdezni, hogy elkészült-e már de mégsem volt az igazi.
A Java 8 új java.util.concurrent.CompletableFuture megoldása sokkal több funkcionalitást biztosít és ezeket a hátrányosságokat is megoldja. (A Future 5 metódusával szemben 60 metódussal rendelkezik, de ezek legtöbbje néhány használati esethez tartozik.) A CompletableFuture a régi Future interfészt is implementálja, tehát visszamenőlegesen kompatibilis.
Egyszerű befejezetlen CompletableFuture létrehozása (ez még igazából semmilyen aszinkron folyamatot nem tartalmaz):
CompletableFuture<String> future = new CompletableFuture<>();
Ez azért befejezetlen, mert ha meghívjuk ezután a következő kódot:
String result = future.get();
akkor a get() örökké fog blokkolni. Ahhoz, hogy egy CompletableFuture végetérjen, annak valamikor befejezett állapotba kell kerülni a complete() metódussal:
CompletableFuture<String> future = new CompletableFuture<>(); future.complete("eredmény"); String result = future.get();
A get()-nek létezik olyan változata is, ahol timeoutot megadhatunk, így adott idő után mindenképpen visszatér. Ha lejárt a timeout, akkor TimeoutException dobásával.
A CompletableFuture-ök jellemzően olyan kódot tartalmaznak, amit egy másik szál hajt végre, de nem mindig ez a helyzet. Lehet például olyan CompletableFuture-t létrehozni, ami egy jövőben biztosan bekövetkező eseményt reprezentál, például egy JMS üzenet érkezését. Ilyenkor létrehozhatunk például egy CompletableFuture<Message> objektumot ami semmilyen aszinkron folyamatot nem tartalmaz. Ezt egyszerűen csak be akarjuk fejezni mikor a JMS üzenet megérkezik (ezt egy esemény váltja ki). Ebben az esetben egyszerűen létrehozunk egy CompletableFuture-t, visszaadjuk a kliensnek és amikor úgy gondoljuk, hogy az eredmény már elérhető, csak meghívjuk a complete() metódusát és ezzel értesítjük az összes klienst aki arra CompletableFuture által reprezentált eseményre vár.
Kezdetben létrehozunk egy CompletableFuture-t és visszaadjuk a kliensnek:
CompletableFuture<String> future; ... public synchronized CompletableFuture<String> ask() { if (future == null) { future = new CompletableFuture<>(); } return future; }
Itt még semmiféle aszinkron varázslat nincs. Ha most a kliens meghívja az ask() által visszaadott CompletableFuture get() metódusát, akkor blokkolódni fog. Ha viszont később valahol ezt mondjuk:
future.complete("gezemize");
akkor az összes kliens ami blokkolódott a get()-nél, visszakapja a paraméterként megadott eredmény sztringet. A complete() csak egyszer fut le, minden további meghívás figyelmen kívül lesz hagyva. Bár van egy obtrudeValue() metódus amivel felül lehet írni az előző értéket, de ezt csak nagyon óvatosan érdemes használni (legjobb sehogy).
Ha hibát akarunk jelezni, akkor ott van a completeExceptionally(ex) metódus (és az obtrudeException(ex) amivel ezt is felülírhatjuk). A completeExceptionally(ex) szintén feloldja a várakozó klienseket, de ezúttal a get() kivételt fog nekik dobni:
CompletableFuture<String> future = new CompletableFuture<>(); ... future.completeExceptionally(new RuntimeException("Bibi van!")); ... future.get();// ez ExecutionException kivételt fog dobni
A completeExceptionally normál complete()-el befejezett CompletableFuture esetén már figyelmen kívül lesz hagyva. A get() egyébként ugyanazt a két kivételt dobhatja mint Java 8 előtt is: InterruptedException (a végrehajtó szálat megszakították) és ExecutionException (a végrehajtás közben valamilyen hiba történt). Amikor több szál hívja egyszerre a complete, completeExceptionally, vagy cancel metódust egy CompletableFuture-ön, csak az egyik hívás lesz hatásos.
Ha egyébként nem szeretjük a get() blokkoló működését akkor ott van a getNow(T valueIfAbsent) ami nem blokkol és ha a CompletableFuture még nem fejeződött be, akkor a paraméterben megadott alapértelmezett értéket adja vissza.
A kivételek kapcsán meg kell említeni a join() metódust. Ez lényegében ugyanazt csinálja, mint a get(), csak kisebb eltéréssel a hibakezelésben:
public T get() throws InterruptedException, ExecutionException
public T join()
Mint látható a join nem dob ellenőrzött kivételeket, ehelyett nem ellenőrzött CompletionException-t fog dobni hiba esetén. Ez például akkor hasznos, ha a CompletableFuture-t stream-ekben használjuk.
Egy CompletableFuture futását a cancel(boolean mayInterruptIfRunning) metódussal bármely, a példányt használó szálból megszakíthatjuk. A metódus paramétere a Java 8-ban semmire sincs használva, tehát mindegy, mit adunk meg. Cancel esetén a CompletableFuture egy CancellationException kivétellel fejeződik be, a tőle függő még nem befejezett CompletableFuture-ök pedig egy CancellationException cause-t tartalmazó ExecutionException-nel (a függő CompletableFuture-ökről később lesz szó). (Tehát a cancel lényegében ugyanaz, mint a completeExceptionally(new CancellationException()).)
final CompletableFuture<String> cFuture = new CompletableFuture<>(); Executors.newCachedThreadPool().submit(() -> { Thread.sleep(500); cFuture.cancel(false); return null; }); cFuture.get();// Kis idő elteltével CancellationException-t fog dobni
Az aszinkron futás természetéből adódóan a kivétel a létrehozó számára csak akkor fog jelentkezni, amikor a get() metódust hívja, nem pedig amikor az a CompletableFuture futása során bekövetkezik. Természetesen nem kell, hogy a get()-nél derüljön ki, hogy baj van: az isCancelled() és isCompletedExceptionally() metódusokkal szépen le lehet kérdezni a CompletableFuture állapotát. Ez uóbbi minden kivételes befejeződést jelez, tehát a cancel-t is és azt is, ha valahol a CompletableFuture-nek adott taszkunk kivétellel elszáll (a CompletableFuture-nek taszk átadását lásd lejjebb). Az isDone() meg azt mondja meg, hogy a CompletableFuture futása befejeződött-e már. (Akár normál módon akár kivétellel.)
CompletableFuture létrehozásának a konstruktor használatától eltérő másik módja az amikor már létező eljárásokkal példányosítjuk őket a következő, funkcionális interfészeket váró statikus metódusokkal:
A runAsync az egyik legegyszerűbb használati eset. Ez egy Runnable-t vár és CompletableFuture<Void>-ot ad vissza, mivel a Runnable-nek nincs visszatérési értéke.
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("Ezt már külön szál fogja futtatni!");
});
Ha szeretnénk várni a future végetérésére, akkor a future.get() használható, bár ez esetben természetesen semmit nem fog visszaadni.
Ha valami eredményt akarunk aszinkron módon számolni, akkor a Supplier-t használó supplyAsync változatokat érdemes használni. Ezek egy Supplier<U> típusú paramétert várnak és egy CompletableFuture<U> típusú értéket adnak vissza.
Egy egyszerű használati eset:
CompletableFuture<Integer> cFuture = CompletableFuture.supplyAsync(this::compute); ... Integer result = cFuture.get(); ... public Integer compute() { ... }
Ez a megoldás CompletableFuture-t hoz létre olyan Supplier-rel ami egy Integer értéket számít ki. Amikor elkészült, a get() metódussal felhasználjuk az eredményt.
Egyébként ha az a speciális eset áll fenn, hogy már a létrehozáskor tudjuk a végrehajtás eredményét akkor használhatjuk a completedFuture statikus metódust (ez például tesztelési célokra hasznos):
Future<String> completed = CompletableFuture.completedFuture("Completed");
Ez esetben a get azonnal visszatér az eredménnyel.
Ha azt szeretnénk, hogy a CompletableFuture ne az alapértelmezett ForkJoinPool.commonPool()-t használja, akkor az Executor-t váró metódusváltozatokat kell hívni:
Executor executor = Executors.newFixedThreadPool(8);
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
return "Ezt már saját executor-unk számította ki.";
}, executor);
CompletionStage és callback-ek
Mint láttuk, a get() blokkol, vagyis vár míg a CompletableFuture be nem fejeződik. Ha nem szeretnénk külön figyelni a számítás befejeződésére, csak megadni, hogy mi történjen ekkor, akkor callback-et is adhatunk a CompletableFuture-nek. Sőt, több CompletableFuture-t is tudunk kombinálni.
Ezt a funkcionalitást definiálja a szintén Java 8-ban megjelent java.util.concurrent.CompletionStage interfész. Ezt is implementálja a CompletableFuture. Ráadásul annak sok metódusa CompletionStage-t vár, így egyszerűen tudunk egymásba fűzött számításokat definiálni. Ezzel akár mindegyik lépés (stage) aszinkron módon futhat. Egy lépés végrehajthat egy műveletet vagy kiszámíthat egy eredményt amit továbbadhat a tőle függő lépéseknek (a korábbi lépés ilyenkor végetér). A CompletionStage használatával létrehozhatunk egyetlen CompletableFuture-t úgy, hogy az CompletionStage lépések láncolatát tartalmazza, ahol minden lépés akkor fut le amikor egy másik CompletionStage befejeződik.
Az interfész 39 metódust tartalmaz, ezek az alábbi elveken alapulnak:
A számítási eredményt váró végrehajtási lépések egyébként akár null értéket is kaphatnak, az API ezt nem gátolja meg. Ezért készülnünk kell rá ha ilyen a számításban előfordulhat, különben NullPointerException-t kapunk.
thenAccept, thenRun
Az első példában egy hosszú számítást futtatunk, és megadunk callback-et, ami jelezni fogja ha a számítás elkészült:
public Integer compute() { // itt van egy baromi hosszú számítás ami visszaad egy Integer-t ... } CompletableFuture.supplyAsync(this::compute).thenAccept(System.out::println);
A thenAccept egy Consumer-t vár, ami feldolgozza az előző számításunk végeredményét miután elkészült. Általában ez a metódus egy CompletableFuture lánc utolsó eleme. Ebből is háromféle létezik, a két "Async" utótagú változat aszinkron módon (a ForkJoinPool.commonPool() használatával vagy saját Executor-al) futtatja a Consumer-t.
A thenRun metódus annyiban tér el, hogy egy Runnable paramétert vár aminek nincs is hozzáférése az előzőleg kiszámolt értékhez. Ez például akkor jó ha nem akarjuk azt felhasználni, csak logolni, hogy készen vagyunk. Ezek a metódusok tehát nem blokkolnak, hanem lényegében eseménykezelőként működnek.
thenApply
Ha egyik callbak-ből egy másikba szeretnénk továbbadni értéket, azt a thenAccept-tel nem tehetjük meg, mivel a Consumer nem ad vissza semmit (a thenAccept visszatérési típusa CompletionStage<Void>). Ez esetben a thenApply-t használhatjuk, ami egy Function-t vár:
public Integer getParameter() { ... } public Integer compute(Integer param) { ... } CompletableFuture.supplyAsync(this::getParameter).thenApply(this::compute).thenAccept(System.out::println);
A thenApply használatával például átalakításokat tudunk végezni CompletableFuture-ök között. Így csinálhatunk egy String generikus típusúból Integer-t:
CompletableFuture<String> futureString = CompletableFuture.supplyAsync(this::getSomeNumberString);
CompletableFuture<Integer> futureInt = futureString.thenApply(Integer::parseInt);
CompletableFuture<Double> futureDouble = futureInt.thenApply(r -> Math.sin(r));
Vagy egy kifejezésben:
CompletableFuture<Double> futureDouble = CompletableFuture.supplyAsync(this::getSomeNumberString)
.thenApply(Integer::parseInt)
.thenApply(r -> Math.sin(r));
Fontos megérteni, hogy ezek az átalakítások nem futnak le azonnal de nem is blokkolnak. Amikor a futureString befejeződik, akkor fognak lefutni. Természetesen itt is átadhatunk saját Executor-t paraméterként az Async metódusverzióknak.
Eddig a callback-jaink ugyanabban a szálban futottak mint a hívóik. De ennek nem kell mindig így lennie! A callback-et át is adhatjuk a ForkJoinPool.commonPool()-nak a CompletionStage "async" utótagú metódusaival. Tegyük fel, hogy két műveletet is el akarunk végezni ugyanazzal a paraméterrel:
public Integer compute(Integer param) { ... } public Integer computeOther(Integer param) { ... } CompletableFuture<Integer> argument = CompletableFuture.supplyAsync(this::getParameter); argument.thenApply(this::compute); argument.thenApply(this::computeOther);
Ekkor minden abban a szálban fog megtörténni, amit az argument létrehozott. Vagyis a második számítás addig fog várni, míg az első véget nem ér. A következő megoldásban viszont mindkét számítás a ForkJoinPool.commonPool() külön szálaiban fog végrehajtódni. Vagyis mindkét callback végrehajtódik amikor a getParameter végetér:
CompletableFuture<Integer> argument = CompletableFuture.supplyAsync(this::getParameter); argument.thenApplyAsync(this::compute); argument.thenApplyAsync(this::computeOther);
Az aszinkron verzió tehát akkor hasznos amikor különböző callback-jaink vannak, amik ugyanattól a megelőző számítástól függnek. Természetesen ilyen esetekben ajánlatos immutable vagy szálbiztos paramétert használni.
thenCompose
Eleddig a compute metódusunk normál blokkoló típusú volt. Ha szeretnénk egy kódot aszinkron műveletekből összerakosgatni, akkor CompletionStage-eket visszaadó metódusokat kell létrehoznunk. De az is előfordulhat, hogy olyan osztálykönyvtárat használunk ami bizonyos műveleteknél CompletionStage típusú visszatérési értéket ad. Ilyenkor az eddigi thenApply metódust nem tudnánk használni, mert egymásba ágyazott CompletionStage-eket adna vissza: CompletionStage<CompletionStage<Integer>>. Ekkor jó a thenCompose metódus ami olyan Function-t vár ami egy CompletionStage-t ad vissza.
A függvények szignatúrája segít megérteni a különbséget:
<U> CompletionStage<U> thenApply(Function<? super T,? extends U> fn) <U> CompletionStage<U> thenCompose(Function<? super T,? extends CompletionStage<U>> fn)
Tehát ha CompletableFuture-t visszaadó metódust fűzünk össze, akkor a thenCompose-t érdemes használni. (Ha valaki ez alapján a flatMap metódusokra gondol, az nem a véletlen műve.)
Legyen a következő két metódusunk:
public Integer getParameter() { return 42; } public CompletionStage<Integer> computeAsync(Integer param) { return CompletableFuture.completedFuture(param).thenApply(i -> i + 10); }
A computeAsync itt már CompletionStage típusú értéket ad vissza. Ezt tudjuk a thenCompose segítségével használni:
CompletableFuture.supplyAsync(this::getParameter).thenCompose(this::computeAsync);
thenCombine
Néha olyan callback-ünk van ami két számítás eredményét igényli. Ekkor jó a thenCombine metódus. Ez lehetővé teszi, hogy BiFunction callback-et adjunk meg ami két CompletionStage eredményét várja:
public Integer getParameter1() { ... } public Integer getParameter2() { ... } public Integer compute(Integer param1, Integer param2) { ... } CompletableFuture<Integer> param1 = CompletableFuture.supplyAsync(this::getParameter1); CompletableFuture<Integer> param2 = CompletableFuture.supplyAsync(this::getParameter2); CompletableFuture<Integer> future = param1.thenCombine(param2, this::compute);
thenAcceptBoth, runAfterBoth
Ha nem szeretnénk új CompletableFuture példányt létrehozni két eredmény egyesítésével, csak értesítést akarunk kapni róla mikor befejeződtek, akkor használhatjuk a thenAcceptBoth és runAfterBoth metódusokat. Hasonlóan működnek a thenAccept és thenRun metódusokhoz, de várnak egy plusz CompletableFuture-t:
String original = "eReDeTi"; StringBuilder result = new StringBuilder(); CompletableFuture.completedFuture(original).thenApply(String::toLowerCase) .thenAcceptBoth(CompletableFuture.completedFuture(original) .thenApply(String::toUpperCase), (s1, s2) -> result.append(s1 + s2)); // eredmény: eredetiEREDETI
acceptEither, runAfterEither
Ha viszont nem szeretnénk mindkét eredményt felhasználni, az acceptEither vagy runAfterEither metódussal megtehetjük, hogy csak azt vesszük figyelembe amelyik hamarább előáll. Ezek nem BiFunction-t várnak, hanem Consumer-t. Ez akkor jó ha például két taszkunk van ami ugyanolyan típusú eredményt állít elő, de csak a válaszidő érdekel minket, nem pedig az, hogy melyik végzett először. Például van két rendszerünk amikkel integráltan kell dolgoznunk. Az egyiknek rövidebb átlagos válaszideje van, de nagy a szórása. A másik általában lassabb, de jobban előre jelezhető. Ha azt szeretnénk, hogy a két rendszer legjobbját hozzuk ki (teljesítmény és előrejelezhetőség) akkor mindkét rendszert meghívjuk egyszerre és megvárjuk az elsőt amelyik válaszol. Általában ez az első lesz, de ha ez lelassul, akkor a második is elfogadható időn belül válaszol.
public void processResult(Integer i) { ... } CompletableFuture<Integer> fastService = ... CompletableFuture<Integer> predictableService = ... CompletableFuture<Void> processed = fastService.acceptEither(predictableService, this::processResult);
A példában van egy fastService (gyorsan válaszoló) és egy predictableService (jobban előrejelezhető) CompletableFuture-ünk. Az acceptEither metódussal a kettő közül a gyorsabban lefutó eredményét fogja megkapni a processResult.
applyToEither
Az applyToEither az acceptEither testvére. Míg ez utóbbi egyszerűen meghív egy kódot, amikor két CompletableFuture-ből a gyorsabb befejeződik, az applyToEither visszaad egy új CompletableFuture-t. Ez akkor fog befejeződni amikor a két alatta lévő CompletableFuture-ből az első befejeződik. A fenti példa átalakítva:
public Integer processResult(Integer i) { ... } CompletableFuture<Integer> processed = fastService.applyToEither(predictableService, this::processResult);
Észrevehetjük, hogy a kliens szempontjából az a tény rejtett, hogy a processed mögött valójában két CompletableFuture van. A kliens egyszerűen csak vár, hogy a CompletableFuture lefusson és az applyToEither-é a felelősség, hogy jelezze a kliensnek amikor a kettő közül a gyorsabb lefutott.
allOf, anyOf
Láttuk, hogy lehet megoldani, hogy két CompletableFuture lefusson (thenCombine) vagy hogy az első lefusson (applyToEither). De mi van ha ezt ki szeretnénk terjeszteni tetszőleges számú CompletableFuture-re? Erre az API statikus metódusokat biztosít.
Az allOf veszi a CompletableFuture-ök tömbjét és visszaad egy CompletableFuture-t ami akkor fejeződik be amikor az összes hozzá tartozó CompletableFuture befejeződik. Az anyOf ezzel szemben csak a tömbben megadott CompletableFuture-ök közül az első befejeződésére vár.
Megjegyzendő, hogy a két metódusnak nem ugyanolyan a visszatérési értéke! Az allOf Void generikus típusú (hiszen nem tartalmazhatja az összes visszatérési értéket egyben), az anyOf pedig Object generikus típusú CompletableFuture-el tér vissza! (Ez azért probléma, mert külön tudnunk kell, hogy milyen is az aktuális visszatérési típus. Ha többféle generikus típusú CompletableFuture-t adtunk meg neki, akkor ez mindenféle instanceof-írásra fog minket ihletni.)
Tegyük fel, hogy egy webservice-t akarunk meghívni mondjuk 50 különbőző paraméterrel. Ezt sorosan is megtehetjük, de az sokáig tart. Ha a kiszolgáló bírni fogja, akkor meghívhatjuk ezeket párhuzamosan is. Írunk egy függvényt, ami megkapja a paramétert (ami mondjuk sztring) és visszaad mondjuk egy CompletableFuture-t. Ez aszinkron módon meghívja a webservice-t.
CompletableFuture<String> callWebService(String pageLink) {
return CompletableFuture.supplyAsync(() -> {
// Ide kerül a kód ami meghívja a webservice-t
});
}
Amikor minden hívás lement, akkor megnézzük, milyen eredmények tartalmaznak:
List<String> parameterList = Arrays.asList("1", "2", "3");// paraméterek listája // Minden webservice meghívása aszinkron módon List<CompletableFuture<String>> resultFutures = parameterList.stream().map(actualParameter -> callWebService(actualParameter .collect(Collectors.toList()); // Összesített Future létrehozása az allOf() metódussal CompletableFuture<Void> allFutures = CompletableFuture.allOf(resultFutures.toArray(new CompletableFuture[resultFutures.size()]));
Az allOf tehát gyakorlatilag több CompletableFuture párhuzamos végrehajtását is elvégzi, de az vele a baj, hogy CompletableFuture<Void> a visszatérési értéke. Az összes benne foglalt CompletableFuture eredményét meg tudjuk szerezni például így:
// Amikor minden Future befejeződik, meghívjuk a "future.join()" metódust, // hogy megszerezzük az eredményüket és összegyűjtjük egy listában CompletableFuture<List<String>> allResultsFuture = allFutures.thenApply(v -> { return resultFutures.stream().map(actualResult -> actualResult.join()).collect(Collectors.toList()); }); // feldolgozás: List<String> results = allResultsFuture.get(); // ...
Az actualResult.join() hívással akkor történik meg a lekérdezés amikor az összes future végetért, ezért semmi nem blokkol semmit.
Hibakezelés
Mint tudjuk, a hibák bekövetkeznek. Szerencsére a CompletableFuture segítségével ez nem érhet váratlanul (legfeljebb kellemetlenül) minket! Tegyük fel, hogy a következő láncunk van:
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
// itt a kód valami kivételt dob
return "eredmény""eredmény";
}).thenApply(result -> {
return "feldolgozott eredmény""feldolgozott eredmény";
}).thenApply(result -> {
return "feldolgozott eredmény feldolgozása""feldolgozott eredmény feldolgozása";
}).thenAccept(result -> {
// valamit csinálunk az utolsó eredménnyel
});
Ha egy kivétel jön az eredeti supplyAsync metódusban, akkor egyetlen thenApply callback sem fog lefutni. Ha az első thenApply metódusban jön a kivétel, akkor a 2. és 3. callback nem fog lefutni, és így tovább. A kivételek továbbdobódnak ezekben a lépésekben és a létrehozó számára - ahogy korábban is írtam - a kivétel csak a get() vagy join() hívásakor fog megjelenni.
Hibakezelést az exceptionally metódussal tudunk kivétel esetén végrehajtani. Ha ezt betesszük egy callback-láncba akkor a kivétel helyett egy alternatív eredménnyel folytatja a következő lépésnél:
Integer magassag = -1;
CompletableFuture<String> domborzatFuture = CompletableFuture.supplyAsync(() -> {
if (magassag < 0) {
throw new IllegalArgumentException("Magasság nem lehet negatív!");
}
if (magassag >= 500) {
return "Hegység";
} else {
return "Dombság";
}
}).exceptionally(ex -> {
System.out.println("Kivétel történt: " + ex.getMessage());
return "Nem meghatározható";
});
System.out.println("Típus magasság alapján: " + domborzatFuture.get());
Az exceptionally törzse csak akkor fut le amikor az előtte lévő lépések valamelyikében kivétel dobódott (egyébként a vezérlés tovább adódik a következő lépésre). A segítségével gyakorlatilag helyreállítjuk a kivételt egy olyan értékre aminek a típusa megfelel a CompletableFuture típusának. A kivétel tehát már nem megy tovább a láncban, miután egyszer lekezeltük.
A handle egy rugalmasabb megoldás, mivel minden esetben lefut és olyan Function-t adhatunk meg neki ami helyes eredményt és kivételt is kaphat:
Integer magassag = -1;
CompletableFuture<String> domborzatFuture = CompletableFuture.supplyAsync(() -> {
if (magassag < 0) {
throw new IllegalArgumentException("Magasság nem lehet negatív!");
}
if (magassag >= 500) {
return "Hegység";
} else {
return "Dombság";
}
}).handle((res, ex) -> {
if (ex != null) {
System.out.println("Kivétel történt: " + ex.getMessage());
return "Nem meghatározható";
}
return res;
});
System.out.println("Típus magasság alapján: " + domborzatFuture.get());
A handle mindig meghívódik, akár elkészült eredmény (az ex null) akár kivétel dobódott (a result null). És ebből az exceptionally-től eltérően léteznek szokásos async változatok is.
whenComplete
A whenComplete hasonló a handle-höz, bár nem feltétlenül úgy működik ahogy előre várnánk. A handle BiFunction-t vár, a whenComplete BiConsumer-t. A handle tehát kezelni tudja az esetleges hibát úgy, hogy valamilyen értékre feloldja, a whenComplete-nek viszont nincs visszatérési értéke, a korábbi lépés eredményét adja tovább. Az esetleges kivételt pedig változatlanul tovább dobja. A következő kódrészlet szépen bemutatja ezt:
CompletableFuture.supplyAsync(() -> {
throw new RuntimeException("1");
}).whenComplete((i, ex) -> {
System.out.println("Abrakadabra");
throw new RuntimeException("2");
}).join();
Mit várnánk ennek a futásától? Hát hibakezelés nélkül dobódna az 1-es RuntimeException, hibakezeléssel kiíródna, hogy Abrakadabra és dobódna a 2-es RuntimeException. Ehelyett viszont ez történik:
Abrakadabra
Exception in thread "main" java.util.concurrent.CompletionException:
java.lang.RuntimeException: 1
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1592)
at java.util.concurrent.CompletableFuture$AsyncSupply.exec(CompletableFuture.java:1582)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)
Caused by: java.lang.RuntimeException: 1
... 7 more
Vagyis dobódik az 1-es RuntimeException, lefut a whenComplete, de az abban dobott 2-es RuntimeException már elnyelődik. Erre jó tehát a whenComplete... Persze mivel ez is megkapja a korábbi esetleges kivételt paraméterben (vagy null ha nem volt), ezért azzal is tudunk a metódus törzsében bármit kezdeni. A korábbi esetleges eredményt pedig továbbadja (mivel a BiConsumer-nek egyébként nincs visszatérési értéke):
String result = CompletableFuture.supplyAsync(() -> {
return "4";
}).whenComplete((i, err) -> {
System.out.println("Abrakadabra");
}).thenApply(s -> s + "2").join();
System.out.println(result);
Ennek az eredménye:
Abrakadabra 42
A dátum és időkezelés a Java fejlesztők számára mindig is az egyik legfájóbb pont volt. Az API nem volt szálbiztos, rosszul volt megtervezve, lényeges funkciókat nem támogatott, nem kezelte az időzónákat. A szabványos java.util.Date-et követő java.util.Calendar nem sokat javított a helyzeten (egyesek szerint inkább csak rontott...). Ekkor jött létre kerülő megoldásként Stephen Colebourne vezetésével a JodaTime, ami remek alternatíva lett a beépített date/time API helyett. A JodaTime nagy hatással volt a hivatalos Java fejlesztésére: a Java 8-ban bevezetett új date/time API nagyrészt ezen alapul: a fejlesztők megpróbálták a legjobb dolgokat átvenni belőle.
Az új API alapértelmezettként a világon legelterjedtebb és ISO-8601-ben szabványosított naptárrendszert támogatja. Ez az 1582-ben bevezetett és nyugati kultúrkörben ma is használatos Gergely-naptáron alapul. A szintén Java 8-ban megjelent java.time.chrono csomag arra is biztosít lehetőséget, hogy más naptárrendszereket is használhassunk, mint például a Hijrah vagy a thai buddhista naptár. Természetesen semmi nem akadályoz meg abban sem, hogy saját naptárrendszert írjuk. Az API az Unicode Common Locale Data Repository-t (CLDR) használja. Ez a repository támogatja a világ nyelveit és a lokalizációs adatok legnagyobb adatbázisát tartalmazza. A repositoryban lévő információkat szinte minden nyelvre honosították. A date-time API emellett a Time-Zone Database (TZDB)-t is használja, ami 1970-től kezdve tartalmaz információkat az összes időzónáról és azok módosításairól.
Az adattípusok tervezésekor az immutable filozófiát nagyon komolyan vették: semmiféle módosítás nem engedélyezett rajtuk (ezt a leckét a fejlesztők még a java.util.Calendar-ból tanulták meg). Módosítás esetén a megfelelő osztályból mindig új példány jön létre. Ez a megoldás definíció szerint szálbiztos és segíti a lambdákkal való használatot.
Az új date-time API négy alcsomagra oszlik:
java.time: a dátum és idő ábrázolására szolgáló API magja. Tartalmazza a dátumhoz, időhöz, ezek kombinációjához, időzónákhoz, instantokhoz, időtartamokhoz és órákhoz tartozó adattípusokat. A java.time package lehetőséget biztosít, hogy az adott feladathoz legmegfelelőbb adattípust használjuk.
java.time.chrono: az alapértelmezett ISO-8601-től eltérő naptárrendszerek ábrázolására szolgáló API. Segítségével saját naptárrendszert is létrehozhatunk.
java.time.format: dátum és idő formázására és parse-olására szolgáló osztályok
java.time.temporal: kiterjesztett API, főként keretrendszer és osztálykönyvtár írók számára. Lehetővé teszi a dátum és idő osztályok közötti keresztműveleteket, lekérdezést és beállítást. Ebben a csomagban vannak definiálva mezők (TemporalField és ChronoField) és egységek (TemporalUnit és ChronoUnit).
java.time.zone: az időzónákat kezelő osztályok: offszetek és időzónaszabályok. A legtöbb fejlesztőnek csak a ZonedDateTime és ZoneId vagy ZoneOffset osztályokat kell használnia.
Az ezredmásodperces pontosságot kezelő java.util.Date osztállyal ellentétben az új adattípusok már nanoszekundumos (milliárdod másodperc) pontossággal dolgoznak. A java.time csomag dátum/idő tárolásához a következő osztályokat tartalmazza (mindegyik osztály implementálja a Comparable interfészt is):
A dátum/idő kezelés mellett a csomag időmennyiségekhez való osztályokat is biztosít:
A csomagban lévő új (nem ellenőrzött) DateTimeException kivétel illetve leszármazottai jeleznek minden dátum/időszámítással kapcsolatos hibát. Mindezek mellett néhány kiegészítő enumot is tartalmaz a package:
Az API úgy lett tervezve, hogy a null paramétereket ésszerűen kezelje. Ez azt jelenti, hogy null paraméterek esetén nem valamilyen "alapértelmezett" értéket ad, hanem NullPointerException-t dob. Kivétel ez alól a boolean visszatérési értékeket előállító validáló vagy ellenőrző metódusok: ezek null paraméter esetén általában false értékeket adnak.
A különböző osztályok nagyon sok metódust tartalmaznak, de a metódusnevek ahol csak lehetett konzisztens elnevezési szabályok szerint lettek megtervezve (ezek nagy része nem is igényelne magyarázatot, hiszen a Java-ban széleskörűen használatosak). Sok osztályban van például now metódus, ami az ahhoz az osztályhoz megfelelő aktuális pillanat dátum vagy idő értékét adja. Mivel a legtöbb osztály immutable, az API nem tartalmaz set metódusokat. A következő lista felsorolja az általánosan használt prefixeket:
A metódushívások egymásba láncolhatók, a visszaadott kód könnyen olvasható. Például:
LocalDate today = LocalDate.now(); LocalDate fizetes = today.with(TemporalAdjusters.lastDayOfMonth()).minusDays(2);
| Osztály | Év | Hó | Nap | Óra | Perc | Másodperc1 | Zónaoffszet | Zóna ID | toString() kimenet |
|---|---|---|---|---|---|---|---|---|---|
| Instant | X | 2019-01-27T17:34:21.639Z | |||||||
| LocalDate | X | X | X | 2019-01-27 | |||||
| LocalDateTime | X | X | X | X | X | X | 2019-01-27T18:37:13.625 | ||
| ZonedDateTime | X | X | X | X | X | X | X | X | 2019-01-27T18:38:02.224+01:00[Europe/Prague] |
| LocalTime | X | X | X | 18:38:56.748 | |||||
| MonthDay | X | X | --01-27 | ||||||
| Year | X | 2019 | |||||||
| YearMonth | X | X | 2019-01 | ||||||
| OffsetDateTime | X | X | X | X | X | X | X | 2019-01-27T18:39:57.043+01:00 | |
| OffsetTime | X | X | X | X | 18:40:17.382+01:00 | ||||
| Duration | 2 | 2 | 2 | X | PT-10H (-10 óra) | ||||
| Period | X | X | X | 3 | 3 | P2D (2 nap) |
1: A másodpercek nanoszekundumos pontossággal
2: Az osztály nem tárolja ezt az információt, de vannak olyan metódusai, amelyekkel megkapható az idő ezekben az egységekben
3: Amikor egy Period hozzáadódik egy ZonedDateTime-hoz, nyári időszámítási vagy más helyi időbeli eltérések jelentkezhetnek
Az új adattípusok egyébként a java.time.temporal.TemporalAccessor interfészből származnak (kivéve a Period és Duration) és a különböző dátum/idő műveletek általában TemporalAccessor típusú paramétert várnak vagy ilyen típussal térnek vissza.
DayOfWeek, Month
Ezzel a két enummal határozhatjuk meg a hónapokat és a hét napjait. Mivel angol elnevezéseket használnak, a kód jó olvashatóságát is biztosítják. Mindkét enum tartalmaz a többi dátum/idő osztályhoz hasonló metódusokat is.
// DayOfWeek példák System.out.printf("%s%n", DayOfWeek.MONDAY.plus(3));// THURSDAY System.out.println(DayOfWeek.from(LocalDate.now()));// az aktuális nap enum-ja System.out.println(DayOfWeek.SATURDAY.getDisplayName(TextStyle.FULL, Locale.forLanguageTag("hu")));// szombat // Month példák System.out.printf("%d%n", Month.FEBRUARY.maxLength());// 29 System.out.println(Month.OCTOBER.getValue());// 10. Ennél az enumnál a getValue()-t használjuk mindig az ordinal() helyett! System.out.println(Month.SEPTEMBER.firstMonthOfQuarter());// a hónapot tartalmazó negyedév első hónapja: JULY
A java.time.format.TextStyle enum megmondja, hogy milyen stílusban szeretnénk megjeleníteni az eredményt:
Az enumok int-eken alapulnak, amik pedig megfelelnek az ISO szabványnak, vagyis:
Clock
A Clock elérést biztosít az aktuális instanthoz, dátumhoz és időhöz egy időzónát használva. Bizonyos szempontból a System.currentTimeMillis() és TimeZone.getDefault() korszerűbb megfelelője. Használata opcionális, hiszen az összes fontos dátum/idő osztálynak van now() gyártómetódusa, ami a rendszerórát és alapértelmezett időzónát használva visszaad egy példányt. A Clock elsődleges célja, hogy szükség esetén lehetővé tegye eltérő idők használatát. Az alkalmazások statikus metódusok helyett így egy objektumot használhatnak az aktuális idő megszerzésére. Ez egyszerűsíti a globalizált alkalmazások tesztelését. Az a legcélszerűbb, ha minden gyártómetódusnak átadunk egy Clock objektumot. Vagy beinjektáljuk egy keretrendszerrel egy bean-be:
public class MyBean { private Clock clock;// injektálással ... public void process(LocalDate eventDate) { if (eventDate.isBefore(LocalDate.now(clock))) { ... } } }
Így lehetővé válik saját óra használata, például fix idővel vagy igény szerinti ofszettel. Mivel a Clock absztrakt osztály, saját implementációt is készíthetünk belőle, de ennek fortélyaira ebben a cikkben nem térek ki. A Clock 8 statikus metódusával szerezhetünk előre elkészített (szálbiztos) implementációkat. Ezen implementációk használhatják a rendszer időzónáját, de akár tetszőlegesen kiválasztott időzónát is. Néhány egyszerű használati példa:
final Clock clock = Clock.systemUTC(); clock.instant();// az aktuális instant: 2019-02-07T20:14:49.415Z clock.millis();// az aktuális milliszekundum, a System.currentTimeMillis() megfelelője LocalDateTime.now(Clock.systemUTC());// az aktuális instant az UTC időzóna szerint. Ennek ajánlott a // használata amikor csak az instantra van szükségünk dátum és idő nélkül LocalDateTime.now(Clock.systemDefaultZone());// az aktuális instant az aktuális időzóna szerint. // Ennek a használata bedrótozza a programunkba a helyi időzónát. LocalDateTime.now(Clock.system(ZoneId.of("Asia/Tokyo")));// az aktuális instant tetszőleges időzóna szerint /* * Percekre kerekítetten működő ("ketyegő") instant adott időzóna szerint. * Másodperces verziója: tickSeconds() * Mindig ugyanazt az időpontot visszaadó verzió: fixed(Instant fixedInstant, ZoneId zone) * Mindig ugyanannyi időtartamonként "ketyegő" verziója: tick(Clock baseClock, Duration tickDuration) */ LocalDateTime.now(Clock.tickMinutes(ZoneId.of("Europe/Paris")));// 2019-02-07T21:14
LocalDate, LocalTime, LocalDateTime, YearMonth, MonthDay, Year
A LocalDate dátumot tárol időzóna nélkül. Talán kitalálható, hogy a LocalTime meg csak időt tárol szintén időzóna nélkül. A LocalDateTime összehozza a kettőt: dátumot és időt tartalmaz időzóna nélkül. Mindhárom osztály a Clock segítségével is létrehozható. A LocalTime és LocalDateTime az időt nanoszekundumos pontossággal tudja tárolni.
// LocalDate létrehozása LocalDate date = LocalDate.now(); LocalDate date1 = LocalDate.of(2019, 2, 1); LocalDate date2 = LocalDate.parse("2019-02-01"); // Műveletek és beállítások LocalDate holnap = LocalDate.now().plusDays(1); LocalDate elozoHonapUgyanezenANapon = LocalDate.now().minus(1, ChronoUnit.MONTHS); LocalDate aHonapElsoNapja = LocalDate.parse("2019-01-20").with(TemporalAdjusters.firstDayOfMonth()); LocalDate haromHetMulva = LocalDate.now().plusWeeks(3); LocalDate date5 = LocalDate.of(2019, Month.NOVEMBER, 21); LocalDate nextWed = date5.with(TemporalAdjusters.next(DayOfWeek.WEDNESDAY)); // 2019-11-21-hez képest a következő szerda 2019-11-27. System.out.printf("%s-hez képest a következő szerda %s.%n", date5, nextWed); LocalDate date4 = LocalDate.now(customClock).withMonth(4);// tetszőleges Clock-kal április // Lekérdezések DayOfWeek szombat = LocalDate.parse("2019-02-02").getDayOfWeek(); int husz = LocalDate.parse("2019-01-20").getDayOfMonth(); int honapNapjai = LocalDate.parse("2019-02-20").lengthOfMonth();// 28 // Feltételvizsgálatok boolean szokoev = LocalDate.now().isLeapYear(); boolean nemKorabban = LocalDate.parse("2019-02-01").isBefore(LocalDate.parse("2019-02-02")); boolean kesobb = LocalDate.parse("2019-02-10").isAfter(LocalDate.parse("2019-02-09")); // ********************** // LocalTime létrehozása LocalTime time1 = LocalTime.now(); LocalTime time2 = LocalTime.of(14, 13, 27); LocalTime time3 = LocalTime.parse("14:13:27"); // Műveletek és beállítások LocalTime hetvenPercMulva = LocalTime.now().plusMinutes(70); LocalTime egyOraja = LocalTime.now().minus(1, ChronoUnit.HOURS); // Lekérdezések long nanosec = LocalTime.now().getNano();// az aktuális időpont nanoszekundum része int ora = LocalTime.ofSecondOfDay(15000).getHour();// 4; vagyis a nap 15 ezredik másodperce a 4. órára esik // ************************* // LocalDateTime létrehozása LocalDateTime dtime1 = LocalDateTime.now(); LocalDateTime dtime2 = LocalDateTime.of(LocalDate.of(2019, 2, 1), LocalTime.of(14, 13, 27)); LocalDateTime dtime3 = LocalDateTime.parse("2019-02-10T07:35:00"); // Műveletek: a LocalDateTime kombinálja a LocalDate és LocalTime műveleteit LocalDateTime haromHetTizOraMulva = LocalDateTime.now().plusWeeks(3).plusHours(10); // *********************** // Adattípusok kombinálása LocalDateTime aNapKezdete = LocalDate.parse("2019-02-01").atStartOfDay(); LocalDateTime napiIdopont = LocalDate.parse("2019-02-01").atTime(15, 20, 10); LocalDateTime napiIdopont2 = LocalDate.parse("2019-02-01").atTime(LocalTime.parse("14:42")); LocalDate date3 = LocalDate.from(LocalDateTime.of(2019, 2, 2, 15, 42, 20)); LocalDateTime dateWithTime = LocalDateTime.now().with(LocalTime.of(14, 45)); LocalDate dateResz = LocalDateTime.now().plusWeeks(3).plusHours(10).toLocalDate();// LocalDateTime-nak csak a dátum mezői LocalTime timeResz = LocalDateTime.now().minusWeeks(3).minusHours(10).toLocalTime();// LocalDateTime-nak csak az idő mezői // *********************** // YearMonth, MonthDay, Year int honapHossza = YearMonth.now().lengthOfMonth();// az aktuális hónap hossza boolean ervenyesSzokoev = MonthDay.of(Month.FEBRUARY, 29).isValidYear(2010);// false boolean ervenyesSzokoev2 = Year.of(2012).isLeap();// true
Azt hiszem a fenti példákból is látható, hogy az új API szinte az összes mindennapi feladatra kínál megoldást.
Instant
Az új date/time API egyik központi eleme az Instant osztály, ami az UTC időegyenesen ábrázol egy pillanatnyi időt. Alkalmazásunk időbélyegeinek tárolására használható például.
Bár enélkül is használható az adattípus, de az instant alaposabb megértéséhez mégsem árt megismerni néhány dolgot a (számítógépes) időmérésről. Akit ez a témakör nem érdekel, nyugodtan átugorhatja ezt a leírást.
Az első fontos fogalom az epoch, ami a wikipédia szerint egy meghatározott időpont, amihez a naptárhasználó népek az időszámításukat igazítják. A szó jelentése: korszak. Ettől a kezdőponttól számlált időadatok összessége az éra. (Bár magyarul epocha-nak írják, én maradok az informatikában elterjedt epoch-nál.)
Nos a Java 8-at használó népek számára a szabványos Java epoch 1970-01-01T00:00:00Z. Az Instant ún. epoch-másodperceket számol, amelyek ettől a Java epoch-tól számolódnak. Az epoch utáni instantoknak pozitív, az epoch előtti instantoknak negatív előjele van. Egy időpillanathoz szükséges értékkészlet a long típusnál nagyobb tárkapacitást igényel, ezért az osztály belsőleg egy long értékben tárolja a másodperceket és egy int-ben a másodperc nanoszekundumait. Ez utóbbi értéke mindig 0 és 999 999 999 között van. Mindkét egységre nézve a nagyobb érték későbbi időpillanatot jelent.
Időskálák
A mindennapi életben az időt szabványosan csillagnapban mérjük. Ez 24 órából áll, egy óra 60 percből, egy perc 60 másodpercből. Egy nap így 86400 másodpercből áll. Ez a mindennapi életben használt időfogalmunk. A pontos idő meghatározása azonban nem egyszerű. A modern világban többféle időskálát is használnak.
TAI: a TAI atomórákra alapozott rendkívül egyenletes időskála. Ez jelenleg a világszerte elhelyezett nagyjából 400 atomóra értékének súlyozott átlaga, mivel még az atomórák által biztosított idők is ingadoznak illetve kis mértékben eltérnek egymástól. A polgári életben a TAI-t nagyon sok helyen használják, például a GPS navigációhoz, tudományos kutatáshoz. Az atomóra alapján definiálták az ún. SI-másodpercet, vagyis azt, hogy mennyi a világszerte elfogadott egy másodperc hossza. (Ha valakit furdal a kíváncsiság: "1 s az alapállapotú (0 K) 133Cs céziumatom két hiperfinom energiaszintje közti átmenethez tartozó sugárzás 9 192 631 770 rezgésének idõtartama".)
UT1: a Föld forgására alapozott (vagyis csillagászati alapú) időskála az Egyetemes Időskála (UT1). Ez jól együtt fut a csillagászati megfigyelésekkel, de mivel a Föld forgása nem eléggé egyenletes, nem alkalmas olyan célokra, mint a TAI. Ráadásul a Föld forgásának lassulása miatt növekszik is egy nap átlagos hossza, ezért egy csillagnap hossza 2018-ban kicsit hosszabb, mint 864000 SI másodperc. A Föld lassulásának mértéke pedig előre nem megjósolható, egy adott nap pontos hosszát mindig csak utólagos méréssel lehet meghatározni. Az SI másodperc hossza nagyon közel van egy csillagnap 1/86400 részéhez, de gyakorlati felhasználáshoz az UT1 nem alkalmas, hiszen egy másodperc pontos hossza előre nem meghatározható és nagyon kis mértékben mindig ingadozik. A TAI időskálához képest az UT1 ma már majdnem 40 másodperc késésben van.
UTC: annak érdekében, hogy a Föld forgásából adódó másodperc hossz-ingadozás a TAI-hoz képest ki legyen egyenlítve, 1975-ben (más forrás szerint 1972-ben) bevezették az Összehangolt Világidő-skálát (UTC). Ez lépett a korábbi greenwich-i időskála (GMT) helyébe. Az UTC a szabványos módszer arra, hogy az UT1-ből származó "töredék" másodperceket összevonják egy másodperccé amit szökőmásodpercnek neveznek. Az UTC időskáláját a TAI-ból úgy származtatják, hogy a TAI értékét időnként 1-1 szökőmásodperccel korrigálják (elvesznek vagy hozzáadnak a Föld tengely körüli forgásának megfelelően). Az UTC lehetővé teszi, hogy egy nap 86399 vagy 86401 SI másodpercből álljon, de emellett szinkronban maradjon a Naphoz képest.
A szökőmásodperces helyesbítések biztosítják, hogy a csillagászati UT1 és az UTC-ben megvalósított polgári időskála ne térjen el egymástól 0,9 s-nál jobban. A beiktatás gyakorisága a Föld forgásának rendszertelensége miatt maga is ingadozik: 1972 óta 27 alkalommal került sor szökőmásodperc beiktatására, eddig mindig pozitív irányban. Az UTC-ben nincs zónaidő, az egész Földön egységes. 1958 és 1972 között az UTC korai definíciója eléggé összetett volt, kisebb részmásodperces ugrásokat alkalmaztak. 2012-ben, amikor az új Java 8 API megjelent, újabb megbeszélések folytak, hogy újra módosítsák az UTC definícióját.
Mindezekből látható, hogy a pontos időszámítás eléggé összetett kérdés. A Java ezért saját időskálát definiál, ez a Java Time-Scale. A Java időskála minden naptári napot pontosan 864000 részre oszt, ezt nevezi másodpercnek. Ezek a másodpercek eltérhetnek az SI másodperctől de eléggé közel vannak a fentebb tárgyalt de facto nemzetközi polgári időskálához. Az idővonal különböző szegmenseihez kissé eltérő Java időskála tartozik, de ezek mindegyike a polgári életben használatos nemzetközi időskálán alapul. Amikor a nemzetközileg elfogadott időskálát módosítják vagy lecserélik, új Java időskálát kell definiálni. Minden szegmensnek a következő követelményeknek kell megfelelni:
A JDK 8 bevezetése tájékán, 2013-ban a Java időskálának két szegmenst definiáltak. Az 1972-11-03-tól lévő szegmenshez további értesítésig a nemzetközi (szökőmásodperces) UTC időskála használatos. A Java időskála megegyezik az UTC-vel azokon a napokon ahol nincs szökőmásodperc. Ahol viszont van, a szökőmásodperc egyenletesen kiterjed a nap utolsó 1000 másodpercére, így megmarad a látszólag pontos napi 864000 másodperc.
Az 1972-11-03 előtti szegmenshez használatos skála az UT1, ami megfelel a meridianon (Greenwich) lévő csillagidőnek. A két szegmens között a pontos határ az az időpillanat amikor az UT1==UTC vagyis 1972-11-03T00:00 és 1972-11-04T12:00 között.
Az Instant nem dolgozik olyan emberi időegységekkel mint év, hónap vagy nap. Ha ilyen egységekben akarunk számolni akkor az instantot át kell konvertálnunk másik adttípussá, például LocalDateTime osztállyá. Fordított irányban ZonedDateTime és OffsetTimeZone is konvertálható Instant objektummá, mivel mindegyik pontos időt jelöl ki az idővonalon. Visszafelé azonban ez már nem igaz: ha egy Instant objektumot szeretnénk ZonedDateTime vagy OffsetDateTime objektummá konvertálni, akkor szükségünk van időzónára vagy időzóna ofszetre.
Bár eddig azt írtam, az Instant nem tárol időzónát, ezzel hogy úgy mondjam nem bontottam ki a valóság minden részletét. Az Instant ugyanis a Java időskálán dolgozik, az pedig az UTC-hez van igazítva. Tehát az Instant valójában az UTC "időzónában" számol. Magyarországon a helyi időhöz képest az Instant.now() egy órával kevesebbet fog adni. Instant példák:
// ******************* // Instant létrehozása Instant instant = Instant.now();// a szokásos időlekérdezés itt is működik Instant instant1 = Instant.parse("2018-10-21T11:19:39Z"); // Az Instant mezőit - előjeles long és int - közvetlenül megadva is példányosíthatunk: Instant instant2 = Instant.ofEpochSecond(1500000000l, 999_100_100);// epoch után: 2017-07-14T02:40:00.999100100Z Instant instant3 = Instant.ofEpochSecond(-1500000000l, -999_100_100);// epoch előtt: 1922-06-20T21:19:59.000899900Z // Az Instant sztringjében a "Z" jelzi, hogy az UTC időzónában értelmezett // ********* // Műveletek: a ChronoUnit használatával emberi léptékű mértékegységeket itt is használhatunk instant = instant.minus(5, ChronoUnit.DAYS);// 5 nap kivonása instant = instant.plusSeconds(82400);// másodperc, ezredmásodperc és milliszekundum műveletek közvetlenül is rendelkezésre állnak instant = instant.truncatedTo(ChronoUnit.DAYS);// napokra vagy annál kisebb egységekre csonkolhatunk is, ekkor a csonkolni // kívántnál kisebb mezők értéke 0 lesz // ************ // Lekérdezések // A get az Instant esetén csak ezekre az enum értékekre működik: NANO_OF_SECOND, MICRO_OF_SECOND, MILLI_OF_SECOND, int field = instant.get(ChronoField.NANO_OF_SECOND);// lekérdezhetjük az int mező értékét // vagy egyszerűen csak: int nano = instant.getNano(); long sec = instant.getLong(ChronoField.INSTANT_SECONDS);// A long mező értékét így kapjuk meg... long epoch = instant.getEpochSecond();// ...vagy így System.out.println(instant);// az Instant kiíratása ISO-8601 szabvány szerint // **************************** // Konvertálás más adattípusból instant = Instant.from(ZonedDateTime.now());// Local... típusokkal a from nem működik, kivételt kapunk
Összehasonlítás
Eddig megismert adattípusainknál összehasonlító metódusokban a bőség zavarával küzdhetünk (kivéve a Clock). Nem árt tudni, melyik pontosan mit is művel, hogy azt használhassuk amit tényleg szeretnénk:
Egy időzóna a Föld olyan területe, ahol ugyanaz a szabványidő. Minden időzónának van egy azonosítója. Az azonosító formátuma régió/város (pl. Europe/Paris) és minden időzóna tartalmaz egy Greenwich/UTC időhöz képesti ofszetet. Magyarország esetén az ofszet +01:00, Tokió esetén +09:00. Az új API-ban két osztály van a zóna és az ofszet kezeléséhez a java.time csomagban:
Az új API három időzónákat kezelő adattípust biztosít:
ZoneId
A ZoneId absztrakt osztály a Java időzóna-kezelés alapja. Ez adja meg azokat a szabályokat amelyek Instant vagy LocalDateTime konvertálásnál szükségesek. A szabályokat kétféle módon lehet azonosítani:
Az osztályok kapcsolatát segít megvilágítani az alábbi UML ábra:
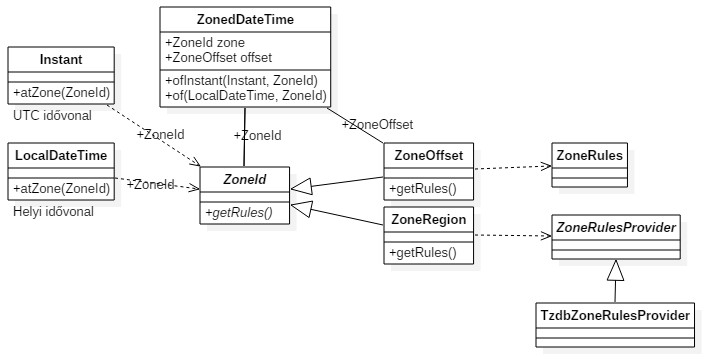
Az absztrakt ZoneId-ből származik a ZoneRegion és a ZoneOffset, bár ZoneRegion helyett mindig csak ZoneID típust tudunk használni, mert az látható a java.time csomagon kívülről. A legtöbb rögzített ofszetet a ZoneOffset adja meg. Egy ZoneId példányból a normalized() metódussal tudunk ZoneOffset-et csinálni, ha rögzített ofszetet tartalmaz. Azok a szabályok, amelyek valójában megmondják, hogy hogyan és mikor változik az ofszet egy zónán belül, a java.time.zone.ZoneRules osztályban vannak leírva. Azért vannak a szabályok és azonosítók külön választva, mert a szabályokat a kormányok határozzák meg és ezért rendszeresen változnak, míg az azonosítók stabilak. A ZoneId.getRules() adja vissza a zónához tartozó szabályokat.
Ennek következménye, hogy két ID összehasonlítása csak az ID-ket vizsgálja, míg két szabály összehasonlítása a teljes adathalmazt. Másik következmény, hogy egy ZoneId szerializálásakor csak az ID lesz elküldve, míg a szabályok szerializálása a teljes adathalmazt küldi. Egy ZoneId olyan környezetben is deszerializálható, ahol az ID ismeretlen. Ha például egy szerveroldali Java már frissült egy új zóna ID-vel, de a kliensoldali párja még nem, a ZoneId akkor is létezni fog kliensoldalon is; használható a getId, equals, hashCode, toString, getDisplayName és normalized metódus, de a getRules el fog szállni ZoneRulesException kivétellel. Ez azért lett így tervezve, hogy egy ZonedDateTime objektumot be lehessen tölteni, le lehessen kérdezni, de ne lehessen módosítani olyan környezeten, ahol hiányos az időzóna információ.
Az ID a teljes rendszerben egyedi és háromféle létezik:
Az időzóna szabályokat a kormányok definiálják és ezért gyakran változnak. Számos szervezet (angol terminológiában group) monitorozza és egyezteti az időzóna változásokat. Az alapértelmezett az IANA Time Zone Database (TZDB). További ilyen szervezet az IATA (a légiközlekedési ipartestület) és a Microsoft. Mindegyikük saját formátumot definiál az általa adott régió ID-khoz. A TZDB által definiált ID-k például: "Europe/London" vagy "America/New_York". Java környezetben a TZDB ID-k használata az elsődleges.
A kavarodás elkerülése érdekében erősen ajánlott, hogy minden olyan ID, amit nem a TZDB adott, tartalmazza a szervezet nevét. Az IATA időzóna régió ID-i általában megegyeznek a hárombetűs reptér kódokkal. (Utrecht repülőterének UTC kódja nyilvánvalóan ütközne is a a fentebb írottakkal.) A TZDB-től eltérő szervezetek régió ID-ihez ajánlott formátum a "group~régió". Vagyis ha IATA adatot definiálunk, akkor az Utrecht repülőtér kódja "IATA~UTC" lenne.
Az aktuális TZDB egyébjént a JDK-ban alapértelmezetten betöltött java.time.zone.TzdbZoneRulesProvider osztályban is benne van. Ez az osztály állítja be az időzóna szabályokat Java platform vagy környezeti szinten (az adatokat a JRE-n belül a lib\tzdb.dat fájlból olvassa föl). Az egy JVM példányhoz használatos ZoneRulesProvider-ek konfigurációs fájlból vagy programozottan is megadhatók. De az esetek túlnyomó részében a TzdbZoneRulesProvider is tökéletesen elegendő.
A ZoneId-ből lekérdezhető ZoneRules is rendelkezik néhány hasznos metódussal:
ZoneRules rulez = ZoneId.of("Europe/Paris").getRules(); // Téli/nyári időszámítás lekérdezése: boolean ido1 = rulez.isDaylightSavings(Instant.parse("2019-02-17T22:16:39Z"));// false boolean ido2 = rulez.isDaylightSavings(Instant.parse("2019-08-17T22:16:39Z"));// true // Van egy téli időszámításban lévő időpontnuk: Instant teli = Instant.parse("2019-02-17T22:16:39Z"); // Megmondja a következő átállítás időpontját és hogy ott 1 órás hézag lesz ez esetben ZoneOffsetTransition kovetkezoOraAllitas = rulez.nextTransition(teli);// Transition[Gap at 2019-03-31T02:00+01:00 to +02:00] // Megmondja az előző átállítás időpontját és hogy ott 1 órás átfedés volt ez esetben ZoneOffsetTransition elozoOraAllitas = rulez.previousTransition(teli);// Transition[Overlap at 2018-10-28T03:00+02:00 to +01:00] boolean nyariIdoszamitas = rulez.isDaylightSavings(teli);// false
ZoneOffset
Greenwich/UTC-hez képesti időzóna ofszetet tárol (például +02:00). Egy időzóna ofszet az az időmennyiség, amenyivel az adott időzóna eltér a Greenwich/UTC-től. Ez általában rögzített számú óra és perc. A ZoneId osztályban rögzítik az ofszetek hely- és idő szerint változó szabályait. Párizs például egy órával van a Greenwich/UTC előtt télen és két órával nyáron. Egy ZoneId pédány Párizshoz két ZoneOffset példányt fog hivatkozni: egy +01:00 példányt télhez és egy +02:00 példányt nyárhoz.
2019-ben az időzóna ofszetek a világon -11:00 és +14:00 között voltak. Azért, hogy későbbi bővítés még beleférjen, de mégis legyen valamiféle validálás, az API az ofszeteket -18:00 és +18:00 között limitálja.
Példák
Legegyszerűbben a ZoneId of metódusával hozhatunk létre ZoneId példányokat. Megjegyzésben megadom, hogy az adott példa valójában milyen osztály példányát generálja.
ZoneId zid1 = ZoneId.of("UTC");// UTC időzóna; ZoneRegion példány ZoneId zid2 = ZoneId.of("Z");// szintén UTC; ZoneOffset példány ZoneId zid3 = ZoneId.of("Europe/Paris");// Magyarországra vonatkozó időzóna; ZoneRegion példány ZoneId zid4 = ZoneId.of("UTC+1");// Magyarországra vonatkozó időzóna; ZoneRegion példány ZoneId zid5 = ZoneId.of("+1");// Magyarországra vonatkozó időzóna; ZoneOffset példány ZoneId zid6 = ZoneId.of("+01:00");// Magyarországra vonatkozó időzóna; ZoneOffset példány
ZoneOffset példányok létrehozása:
ZoneOffset zof1 = ZoneOffset.of("Z"); ZoneOffset zof2 = ZoneOffset.of("+1"); ZoneOffset zof3 = ZoneOffset.of("+01:00"); ZoneOffset zof4 = ZoneOffset.of("-0300"); ZoneOffset zof5 = ZoneOffset.of("-053010");// ofszetnek másodperc pontosságot is megadhatunk
A ZoneOffset az UTC időzónát beépítve is tartalmazza:
ZoneId zid7 = ZoneOffset.UTC;// UTC időzóna; ZoneOffset példány
A ZoneOffset és ZoneId a fenti leírás értelmében eltér még ha látszólag ugyanarra az időzónára vonatkozik is! Tekintsük a következő példát:
ZonedDateTime now = ZonedDateTime.now(); boolean utcEquals = now.withZoneSameInstant(ZoneOffset.UTC) .equals(now.withZoneSameInstant(ZoneId.of("UTC")));
Az utcEquals értéke false lesz, pedig mindkét esetben UTC időzónával dolgozunk! Ha két ZonedDateTime értékét megnézzük, akkor látjuk is, mi a különbség:
System.out.println(now.withZoneSameInstant(ZoneOffset.UTC)); // Ezt írja ki: 2019-02-17T18:35:09.215Z System.out.println(now.withZoneSameInstant(ZoneId.of("UTC"))); // Ezt írja ki: 2019-02-17T18:35:09.215Z[UTC] // Mivel ez a forma zóna azonosítót is tartalmaz, // ezért eltér a kizárólag ofszetet tartalmazó normalizált változattól: ZoneId zid = ZoneId.of("UTC+2"); System.out.println(zid);// UTC+02:00 zid = zid.normalized(); System.out.println(zid);// +02:00
A fenti példában az equals metódust használtuk összehasonlításra, ami objektum egyenlőséget vizsgál. Ezért a két objektum nem lesz ugyanaz. Ha az isEqual metódust hasznájuk, ami a dátum-időt vizsgálja, akkor már true értéket kapunk. Fentebb pedig már említettem, hogy a normalized() metódussal is tudunk ZoneOffset-et csinálni a ZoneId-ből, tehát:
boolean utcEquals2 = now.withZoneSameInstant(ZoneOffset.UTC)
.equals(now.withZoneSameInstant(ZoneId.of("UTC").normalized()));
Ez esetben true lesz az utcEquals2 értéke. A normalize a konkrét zónainformáción kívül minden esetben működik, tehát a fenti példák közül egyedül a ZoneId zid3 = ZoneId.of("Europe/Paris"); változatnál maradna ZoneRegion a példány normalizálás után, az összes többinél ZoneOffset-et kapnánk. A "Z", "+1", "+01:00" példák esetén pedig az of a ZoneId esetén is egyből ZoneOffset példányt hoz létre.
Az ofszetek a világban általában egész órákban vannak rögzítve, de vannak kivételek. A következő kód kilistázza az összes időzónát ami nem egész órákat használ az UTC-től:
List<String> zoneList = new ArrayList<String>(ZoneId.getAvailableZoneIds()); Collections.sort(zoneList); for (String s : zoneList) { ZoneId zone = ZoneId.of(s); ZonedDateTime zdt = ZonedDateTime.now(zone); ZoneOffset offset = zdt.getOffset(); int secondsOfHour = offset.getTotalSeconds() % (60 * 60); // Csak azon zónákat írjuk ki amiknek nem egész órányi ofszetjük van if (secondsOfHour != 0) { System.out.printf("%25s %8s%n", zone, offset); } }
ZonedDateTime
Amennyiben egy adott időzónában lévő dátumra/időre van szükségünk, a ZonedDateTime segít. A nanoszekundumos pontossággal tárolt idő mellett egy időzónát és egy zóna ofszetet is tárol (gyakorlatilag egybefoglal egy LocalDateTime, egy ZoneId és egy ZoneOffset objektumot). Egy tárolható érték például "2019. november 2.-a 11:45.30.123456789 +02:00 az Europe/Paris időzónában".
Az osztály konvertálni tud LocalDateTime idővonalból Instant idővonalba; a kettő között a ZoneOffset által tárolt ofszet a különbség. A konvertáláshoz figyelembe kell venni a ZoneId által meghatározott szabályokat is. Láttuk, hogy egy Instant-hoz könnyű ofszetet meghatározni, mert az Instant-hoz pontosan egy érvényes ofszet tartozik. A LocalDateTime ofszetjének meghatározása viszont nem egyszerű. Három eset van:
Esélyes, hogy a LocalDateTime-ból Instant-ba közvetlenül konvertálás bonyolult lesz. Hézagok esetén a Java azt csinálja, hogy ha a LocalDateTime a rés közepébe esik, akkor az eredmény zónázott date-time a rés hosszával eltolt local date-time értéke lesz, így olyan értéket ad, ami tipikusan a nyári időszámítás késői ofszetjében van. Átfedések esetén az általános stratégia, hogy ha a LocalDateTime az átfedés közepébe esik, akkor az előző ofszet lesz megtartva. Ha nincs előző ofszet, vagy érvénytelen, akkor a korábbi ofszet lesz használatos, ami tipikusan a "nyári" időszámítás. Két metódus, a withEarlierOffsetAtOverlap() és withLaterOffsetAtOverlap() segít kezelni az átfedés jelenségét.
A következő módokon tudunk ZonedDateTime példányokat létrehozni:
// ************************* // ZonedDateTime létrehozása ZonedDateTime zoned1 = ZonedDateTime.now(); ZonedDateTime zoned2 = ZonedDateTime.now(ZoneId.of("Europe/Paris")); ZonedDateTime zoned3 = ZonedDateTime.parse("2015-05-03T10:15:30+01:00[Europe/Paris]"); // Más adattípusokból LocalDateTime ldt = LocalDateTime.now(); ZonedDateTime zoned4 = ZonedDateTime.of(ldt, ZoneId.of("Europe/Paris"));// LocalDateTime -> ZonedDateTime Instant instant = Instant.now(); ZonedDateTime zoned5 = ZonedDateTime.ofInstant(instant, ZoneId.of("Asia/Tokyo"));// Instant -> ZonedDateTime
Instant és LocalDateTime példányokból az atZone metódussal tudunk ZonedDateTime-ot csinálni:
ZonedDateTime zoned6 = LocalDateTime.now().atZone(ZoneId.of("+07:00")); ZonedDateTime zoned7 = Instant.now().atZone(ZoneId.of("Australia/Sydney"));
A ZonedDateTime természetesen rendelkezik mindazon műveletekkel is amelyeket már korábban láttunk a többi adattípusnál. Különböző időzónák közötti konvertálásokat mutat be a következő példa:
// Indítunk egy helyi idővel: 2018-12-24T19:00 LocalDateTime local = LocalDateTime.of(2018, 12, 24, 19, 0); System.out.println("LocalDateTime: " + local); // Beállítjuk az Europe/Paris időzónát a LocalDateTime-unknak ZonedDateTime magyarIdoSzerint = local.atZone(ZoneId.of("Europe/Paris")); System.out.println("Magyar idő szerint: " + magyarIdoSzerint); // A mi időnk az UTC időzónában ZonedDateTime magyarIdoToUTC = magyarIdoSzerint.withZoneSameInstant(ZoneId.of("UTC+00:00")); System.out.println("UTC időzónába konvertálva: " + magyarIdoToUTC); // A mi időnk japán idő szerint ZonedDateTime magyarIdoJapanban = magyarIdoSzerint.withZoneSameInstant(ZoneId.of("Asia/Tokyo")); System.out.println("Japán idővé konvertálva: " + magyarIdoJapanban);
A következő példában Budapestről Dubajba repülünk. Az indulási időt magyar időzónában adjuk meg ZonedDateTime példányként. A withZoneSameInstant és plusMinutes metódusok segítségével kiszámoljuk, hogy mikor érkezünk helyi idő szerint Dubajba 5 óra 15 perc utazást követően. A ZoneRules.isDaylightSavings metódus megmondja, hogy nyári időszámítás van-e amikor a repülő megérkezik Dubajba. DateTimeFormatter példányt használunk a ZonedDateTime példány megjelenítéséhez (később bővebben lesz róla szó):
DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy MMM d hh:mm a"); // 2019. február 19-én indulunk Budapestről délután 2:50-kor ZoneId indulasiZona = ZoneId.of("Europe/Paris"); ZonedDateTime indulas = ZonedDateTime.of(LocalDateTime.of(2019, Month.FEBRUARY, 19, 14, 50), indulasiZona); try { System.out.printf("Indulás: %s (%s)%n", indulas.format(format), indulasiZona); } catch (DateTimeException ex) { System.out.printf("%s nem formázható!%n", indulas); } // 5 óra 15 perc utazás után érkezünk ZoneId celZona = ZoneId.of("Asia/Dubai"); ZonedDateTime erkezes = indulas.withZoneSameInstant(celZona).plusMinutes(5 * 60 + 15); try { System.out.printf("Érkezés: %s (%s)%n", erkezes.format(format), celZona); } catch (DateTimeException ex) { System.out.printf("%s nem formázható!%n", erkezes); } if (celZona.getRules().isDaylightSavings(erkezes.toInstant())) { System.out.printf(" (%s időzónában nyári időszámítás lesz.)%n", celZona); } else { System.out.printf(" (%s időzónában téli időszámítás lesz.)%n", celZona); }
A program kimenete:
Indulás: 2019 febr. 19 02:50 DU (Europe/Paris) Érkezés: 2019 febr. 19 11:05 DU (Asia/Dubai) (Asia/Dubai időzónában téli időszámítás lesz.)
OffsetTime, OffsetDateTime
Ezek a típusok az idő és dátum/idő mellett adott UTC-hez képesti ofszetet tárolnak. Kezelésük az eddigiek alapján már semmi újdonságot nem jelenthet. Azt viszont érdemes átgondolni, hogy mikor használjuk ezeket a ZonedDateTime helyett? Ha olyan szoftverrendszert írunk ami földrajzi helyek alapján saját szabályokat definiál a dátum-idő számításokhoz vagy ha időbélyegeket olyan adatbázisban tárolunk ami csak UTC-hez képesti abszolút ofszeteket tárol, akkor érdemes az OffsetDateTime-ot használni. Emellett XML vagy egyéb formátumok is definiálnak dátum-idő átviteli adattípusokat OffsetDateTime vagy OffsetTime típusként. Bár mindhárom osztály tárol ofszetet, csak a ZonedDateTime használja a ZoneRules-t, hogy meghatározza, egy időzónában egy ofszet hogyan változik. A legtöbb időzóna tartalmazza például az 1 órás rést amikor a nyári időszámításhoz előre állítjuk az órát és átfedést amikor a téli időszámításhoz vissza (ilyenkor az állítás előtti utolsó óra megismétlődik). A ZonedDateTime kezeli ezeket az eseteket, de az OffsetDateTime és OffsetTime osztályok nem.
Időmennyiségek kezeléséhez a Java 8 két osztályt és egy metódust biztosít:
Duration esetén egy nap pontosan 24 óra hosszú. Period esetén viszont időzónától függően változhat egy nap hossza amikor Period objektumot ZonedDateTime-hoz adunk (például a nyári időszámítás első vagy utolsó napján).
Duration
Időmennyiség számolása másodpercekben és nanoszekundumokban. Egy Duration objektum tartalma természetesen ezektől eltérő időtartam-egységekben is lekérdezhető (percek, órák vagy napok). A Duration nem követ időzónát vagy nyári időszámítást. 1 napnyi Duration hozzáadása egy ZonedDateTime értékhez, vagy nap mértékegységben való lekérdezés minden esetben úgy működik, hogy egy nap 24 órából áll, függetlenül a nyári időszámítástól vagy egyéb időbeli eltérésektől. A Duration esetén használt másodperc nem feltétlenül azonos az SI-féle, atomórán alapuló másodperccel, de ez csak a szökőmásodpercek közelében lévő számításokat befolyásolja, ezért a legtöbb alkalmazásra semmi hatása nincs.
A Duration ugyanolyan felbontást használ, mint az Instant, vagyis nanoszekundumokat tárol int, másodperceket pedig long primitív típusban. Egy fizikai időtartam végtelen hosszú is lehet, de az Instant-hoz hasonló megszorítás mindenesetre jó kompromisszum a használhatóság terén. A tárolható időtartam így is nagyobb, mint a világegyetemünk jelenlegi becsült élettartama. Az adattárolásból az is következik, hogy ez egy irányított időtartam, vagyis az értéke negatív is lehet. Például akkor, ha olyan vég-időponttal hoztuk létre ami az indulási időpont előttre esik.
A Duration olyan helyzetekben alkalmas, amikor gépi alapú időt mérünk, mint például Instant-okat használó kódnál. Példányt a between metódussal tudunk a legegyszerűbben létrehozni:
// ******************** // Duration létrehozása LocalTime kezdet = LocalTime.parse("19:30"); LocalTime veg = LocalTime.parse("23:45"); Duration dur1 = Duration.between(kezdet, veg); long percek = dur1.toMinutes();// 255
A long típussal visszatérő toDays(), toHours(), toMillis(), toMinutes(), toNanos() metódusokkal pedig le tudjuk kérdezni az értékét.
A between metódusnak egyébként eltérő típusokat is megadhatunk. Az időtartam számításakor ilyen esetekben az első paraméter típusából fogja meghatározni a második típusát.
LocalDateTime vegDatum = LocalDateTime.of(2019, 2, 19, 20, 10); LocalTime kezdetIdo = LocalTime.parse("11:30"); Duration dur2 = Duration.between(kezdetIdo, vegDatum); // 520 perc
Ha viszont felcserélnénk a kettőt:
Duration dur2 = Duration.between(vegDatum, kezdetIdo);
Akkor DateTimeException kivételt kapunk, mert a kezdetIdo-t nem tudja LocalDateTime-ként használni, hiszen dátum információt a LocalTime nem tárol. (Ugyanígy kivételt kapunk ha az első paraméter ZonedDateTime, a második pedig LocalDateTime, mert ez esetben a LocalDateTime példányból nem tud ZoneId-t szerezni.)
További létrehozási lehetőségek:
Duration dur2 = Duration.ofDays(2);// pontosan 2x24 óra Duration dur3 = Duration.ofMinutes(-256);// -256 perc Duration dur4 = Duration.parse("PT25M");// 25 perc Duration dur5 = Duration.parse("-PT2H12M");// -2 óra -12 perc; -132 perc Duration dur6 = Duration.parse("PT-2H12M");// -2 óra +12 perc; -108 perc
(A parse metódus leírásánál az API-ban egyébként több hibás példa is szerepel, amikkel valójában kivételt dob a metódus; a T jel hiányzik több esetben.)
A Duration is rendelkezik a szokásos műveletekkel, sőt még egy picit többel is, például:
Duration duration1 = Duration.ofDays(2).plusMinutes(20).minusMillis(230); System.out.println(duration1);// PT48H19M59.77S //vagyis 48 óra 19 perc 59 másodperc 770 ezredmásodperc Duration duration2 = Duration.ofHours(-436); duration2 = duration2.abs();// abszolútérték duration2 = duration2.negated();// negált érték duration2 = duration2.dividedBy(10);// osztjuk 10-zel System.out.println(duration2.toHours());// -43 // A Duration-t más típusok műveleteiben is felhasználhatjuk. // Itt például a mai időponthoz hozzáadunk 40 órát: LocalDateTime ldt = LocalDateTime.now().plus(Duration.ofHours(40));
Period
A Period osztállyal dátum alapú (évek, hónapok, napok) időtartamot tudunk ábrázolni. A get metódusaival (getMonths, getDays és getYears) tudjuk kinyerni belőle az időmennyiséget a kívánt mértékegységben, értékei lehetnek nullák is.
// ******************** // Period létrehozása LocalDate kezdet = LocalDate.parse("2017-07-19"); LocalDate veg = kezdet.plus(Period.ofDays(9)); int eredmeny = Period.between(veg, kezdet).getDays();// -9 // További létrehozási lehetőségek Period per1 = Period.of(10, 6, 12);// 10 év 6 hónap 12 nap Period per2 = Period.ofWeeks(12);// 12 hét Period per3 = Period.parse("P1Y2M5D");// 1 év 2 hónap 5 nap Period per4 = Period.parse("P-3Y5M");// -3 év 5 hónap, vagy: Period per5 = Period.of(-3, 5, 0);// ugyanaz mint a fönti, per4.equals(per5)==true // Műveletek LocalDateTime ldt = LocalDateTime.now(); Period per = Period.ofDays(3); // a Period tartalmaz addTo és subtractFrom metódust, // de a JDK inkább a kívánt típus plus és minus metódusának használatát javasolja // tehát az alábbi két sor működése megegyezik, de a második a javasolt: ldt = (LocalDateTime) per.addTo(ldt); ldt.plus(per); System.out.println(Period.of(2019, 2, 22).toTotalMonths());// a teljes hónapok száma a dátumban: 24230
A megszokott plus és minus műveletekkel a Period esetén vigyázni kell, ezek ugyanis nem normalizálják az eredményt automatikusan!
Period per6 = Period.of(2019, 2, 22).minusDays(40); System.out.println(per6);// P2019Y2M-18D vagyis 2019 02 -18 Period per7 = Period.of(2019, 2, 22).plusMonths(13); System.out.println(per7);// P2019Y15M22D vagyis 2019 15 22
Természetesen ha ezeket a Period példányokat date/time adattípusok esetén használjuk (hozzáadjuk, elvesszük) akkor az eredmény date/time adattípusok normalizáltak lesznek, csak az önmagában álló Period kezelésekor fontos tudni róla. A hónapokat a normalize() metódussal normalizálhatjuk (ez a napokat változatlanul hagyja):
// A normalized a napokkal nem törődik, csak a hónapokkal: System.out.println(per6.normalized());// P2019Y2M-18D, vagyis semmi nem változott System.out.println(per7.normalized());// P2020Y3M22D vagyis 2020 03 22
A Period különbözik a Duration típustól abban, hogy míg a Duration mindig rögzített időt kezel (egy nap mindig 24 órából áll), a Period megpróbálja fenntartani a helyi időt. Adjunk hozzá épp a tavaszi óraátállítás előtti napon egy ZonedDateTime dátumhoz egy napnyi Period-ot és Duration-t. Mondjuk 16:00-kor. A Period egy naptári napot fog hozzáadni és egy olyan ZonedDateTime-ot eredményez ami a következő nap 16:00-n áll. Ezzel szemben a Duration pontosan 24 órát fog hozzáadni, így olyan ZonedDateTime-ot eredményez ami a következő nap 17:00-n áll (a mi időzónánkban a rés pont egy óra).
// óraátállítás: 2019-03-31T02:00+01:00-kor +02:00-re // alább az előző nap 16:00-ra hozunk létre egy példányt: ZonedDateTime zdt = ZonedDateTime.of(2019, 3, 30, 16, 0, 0, 0, ZoneId.of("Europe/Paris"));// 2019-03-30T16:00+01:00[Europe/Paris] System.out.println(zdt.plus(Duration.ofHours(24)));// 2019-03-31T17:00+02:00[Europe/Paris] System.out.println(zdt.plus(Period.ofDays(1)));// 2019-03-31T16:00+02:00[Europe/Paris]
ChronoUnit.between
Ha az eltelt időt nem a Period vagy Duration által adott bontásban hanem egyetlen mennyiségben szeretnénk használni, akkor jó a ChronoUnit.between metódus. Meg kell adni a kezdő és vég időpontot, amelyeknek kompatibilis típusoknak kell lenniük. A metódus az eredmény kiszámítása előtt átkonvertálja a második paramétert az első típus példányává. Az eredmény negatív is lehet, ha a végdátum a kezdő dátum elé esik. Példa:
long napok = ChronoUnit.DAYS.between(LocalDate.of(2010, 4, 5), LocalDate.of(2019, 2, 22));// 3245
A számítás mindig egész számot eredményez: a két idő közötti teljes egységekben. Tehát a 11:30 és 13:29 között ha órákban számolunk akkor csak egy órát kapunk, mert még egy perc hiányzik a két órához.
Létezik a metódusnak egy egyenértékű változata is, mégpedig a Temporal.until(Temporal, TemporalUnit) metódus:
long napok2 = LocalDate.of(2010, 4, 5).until(LocalDate.of(2019, 2, 22), ChronoUnit.DAYS);//3245
A két metódus használata ekvivalens, mindig a kód olvashatósága szerint érdemes köztük dönteni. Számításainkat a ChronoUnit vagy a ChronoField mezőit használva végezhetjük. Ha az egység számítása nem támogatott, akkor UnsupportedTemporalTypeException kivételt kapunk.
Láttuk, hogy a dátum/idő adattípusoknak van beépített parse metódusuk sztringek közvetlen beolvasásához. Az adattartalom ISO-8601-nek megfelelő formában való kiírásához eddig a toString() metódust használtuk, de ezek az osztályok tartalmaznak format metódust is, amivel kívánt formára alakíthatjuk a tárolt információt. A parse pedig rendelkezik olyan kétparaméteres változattal is, ahol a második paraméter egy tetszőleges formátum. Ez kétparaméteres parse és a format esetén is ugyanaz: egy DateTimeFormatter példány. A DateTimeFormatter tartalmaz néhány előre megadott formázót, de sajátot is definiálhatunk.
A java.time csomagban lévő új adattípusok egyébként közvetlenül is használhatók a már 1.5-ös Java óta létező java.util.Formatter és String.format eszközökkel ugyanúgy mint a régi java.util.Date és java.util.Calendar. Erre már volt korábban néhány példa a régi System.out.printf() metódus használatakor is:
String minta = "2019-02-25"; Date dat = null; try { dat = new SimpleDateFormat("yyyy-MM-d").parse(minta); } catch (ParseException ex) { // TODO hibakezelés } String output = String.format("%tB havában %tA napon", dat, dat); LocalDate local = LocalDate.parse(minta); String output2 = String.format("%tB havában %tA napon", local, local);
Az output és output2 értéke is "február havában hétfő napon".
Az új parse és formázó API immár teljesen szálbiztos és immutable, nem úgy mint a régi DateFormat. A JDK tutorialja szerint ezt már ajánlatos statikus konstansként kezelni, ha lehetséges.
A parse és format metódusok bármely konverziós probléma esetén kivételt dobnak:
Ezek nem ellenőrzött kivételek, tehát a fordító nem követeli meg a kezelésüket, nekünk kell figyelni rá, hogy try-catch blokkot definiáljunk.
Parse
Az adattípusok egy paramétert váró parse(CharSequence) változata mindig az ISO szerinti alapértelmezett formázót használja. Az alábbi táblázatban összefoglalom, hogy mely adattípusok mely DateTimeFormatter konstanst használják és megadok példa sztringet is az egy paraméteres parse metódushoz:
| Osztály | DateTimeFormatter konstans | Példa sztring |
|---|---|---|
| Instant | ISO_INSTANT | "2019-02-25T20:57:30Z" |
| LocalDate | ISO_LOCAL_DATE | "2019-02-25" |
| LocalDateTime | ISO_LOCAL_DATE_TIME | "2007-12-03T10:15:30" |
| LocalTime | ISO_LOCAL_TIME | "15:15" |
| OffsetDateTime | ISO_OFFSET_DATE_TIME | "2019-02-25T21:03:30+01:00" |
| OffsetTime | ISO_OFFSET_TIME | "21:03:30+01:00" |
| ZonedDateTime | ISO_ZONED_DATE_TIME | "2019-02-25T21:06:30+01:00[Europe/Paris]" |
Ha ezektől a mintáktól szeretnénk eltérni akkor használhatjuk a két paramétert váró parse(CharSequence, DateTimeFormatter) metódust, például más előre definiált DateTimeFormatter konstansokkal:
// 2019. 10. hetének 5. napja: 2019-03-08 LocalDate date = LocalDate.parse("2019-W10-5", DateTimeFormatter.ISO_WEEK_DATE);
Vagy akár saját mintával:
LocalDateTime ldt = LocalDateTime.parse("5 2 2019-16.30",
DateTimeFormatter.ofPattern("d M yyyy-H.m"));
Ebben egy karakter reprezentálja a hónapot, egy a hónap napját és négy az évet. Ezzel a mintával a parse felismeri az "5 2 2019-16.30" vagy "06 12 2019-16.30" sztringeket. Viszont ha a formátumot "dd MM yyyy-H.m" formában adjuk meg, vagyis két karakterrel a hónapot és a hónap napját, akkor ezeknek mindig két karaktert is kell megadnunk, az egy számjegyű (hó)napoknak 0-val kell kezdődnia. A DateTimeFormatter dokumentációja megadja a teljes leírást, itt nem térek ki minden lehetőségre.
Nem csak az adattípusok, hanem a DateTimeFormatter parse metódusaival is dolgozhatunk. A parse egyébként egy kétfázisú művelet. Első lépésben a bemenet feldolgozása a formázó által adott minta alapján megtörténik és egy map készül a mező-érték párokból egy ZoneId és egy Chronology példánnyal. Második lépés az adat feloldása (resolve): ekkor történik a validálás, összefűzés és egyszerűsítés. A parse műveletet a DateTimeFormatter-ben ötféle metódus szolgálja, ebből négy mindkét fázist elvégzi, az ötödik viszont a feloldást nem:
parse(CharSequence text): alapértelmezett parse:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy. MM. dd. - HH:mm"); LocalDateTime ldt = LocalDateTime.from(formatter.parse("2019. 03. 02. - 19:45"));// 2019-03-02T19:45
parse(CharSequence text, ParsePosition position): egy sztring tetszőleges részére végezhetjük el a parse műveletet. A position paraméter az az index ahol a szövegben elkezdődik a beolvasandó rész. Amikor a beolvasás eléri a minta végét, a beolvasás is végetér, a sztring további része nem lesz feldolgozva (csak ez a metódus működik így, a többinél a beolvasandó sztringnek pontosan meg kell felelnie a mintának):
String minta = "A mai nap: 2019. 03. 02. Ez a sztring már nem lesz feldolgozva."; DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy. MM. dd."); LocalDate ld = LocalDate.from(formatter.parse(minta, new ParsePosition(11)));// 2019-03-02
parse(CharSequence text, TemporalQuery<T> query): a TemporalQuery egy funkcionális interfész amit az új API a dátum/idő kezeléshez vezetett be. Ennek segítségével egy lépésben el tudjuk végezni a beolvasás műveletet:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy. MM. dd. - HH:mm"); LocalDateTime ldt = formatter.parse("2019. 03. 02. - 19:45", LocalDateTime::from);// 2019-03-02T19:45
parseBest(CharSequence text, TemporalQuery<?>... queries): olyan esetekhez való amikor a parse opcionális paramétereket is tud kezelni (ezt a mintában a [] karakterek között lehet jelezni). Az "uuuu-MM-dd HH.mm[ VV]" minta például ZonedDateTime vagy LocalDateTime példánnyá is szépen beolvasható. Ilyen esetekben a parseBest második paraméterének sorrendje is fontos: először a legjobban illeszkedő adattípust kell megadni, aztán haladni a legkevésbé illeszkedő felé. (A queries itt is tipikusan from-ra hivatkzó metódusreferenciákat tartalmaz.) Az eredmény a legjobban illeszkedő adattípussal tér vissza (vagy kivételt dob ha nincs ilyen) amit aztán típusellenőrzéssel célszerű feldolgozni:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("uuuu-MM-dd HH:mm[ VV]"); TemporalAccessor dt = formatter.parseBest("2019-03-02 19:45 +01:11", ZonedDateTime::from, LocalDateTime::from); if (dt instanceof ZonedDateTime) { // TODO ZonedDateTime feldolgozás } else { // TODO LocalDateTime feldolgozás }
A példában ZonedDateTime lesz a dt aktuális típusa. Ha például "2019-03-02 19:45" sztringgel próbálkoznánk, akkor LocalDateTime lenne.
parseUnresolved(CharSequence text, ParsePosition position): alacsonyszintű művelet, amely kihagyja a második, feloldás lépést. Ezzel az általános felhasználás során semmi dolgunk.
A parse művelet feloldás lépését a ResolverStyle enum három értékével lehet vezérelni:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("uuuu-MM-dd").withResolverStyle(ResolverStyle.SMART); LocalDate ld = formatter.parse("2019-11-31", LocalDate::from); // az ld tartalma: 2019-11-30
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("uuuu-MM-dd HH:mm").withResolverStyle(ResolverStyle.LENIENT); LocalDateTime dt = formatter.parse("2019-15-02 29:45", LocalDateTime::from); // a dt tartalma: 2020-03-03T05:45
Az alapértelmezett működés a SMART.
Formázás
A formázást használata sem tér el lényegében a parse-tól. Az adattípusok format metódusával tetszőleges DateTimeFormatter példány segítségével alakíthatjuk az objektumot sztringgé:
LocalDateTime ldt = LocalDateTime.now(); System.out.println(ldt.format(DateTimeFormatter.ofPattern("yyyy. MM. dd. G - H.m")));
De a DateTimeFormatter.format is ugyanezt csinálja bármely dátum/idő adattípussal (a mintában a G azt adja meg, hogy időszámításunk előtt vagy után):
System.out.println(DateTimeFormatter.ofPattern("yyyy. MM. dd. G - H.m").format(ldt));
Az írás pillanatában mindkét sor kimenete:
2019. 02. 26. i.u. - 22.17
Ha StringBuilder-ünk vagy fájlunk van, a formatTo metódussal egyből abba írathatjuk az eredményt:
StringBuilder sb = new StringBuilder(); LocalDateTime ldt = LocalDateTime.now(); DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy. MM. dd. - H.m"); formatter.formatTo(ldt, sb);
Bár az Appendable metódusok IOException-t dobhatnak, a formatTo ezt DateTimeException-be csomagolja.
A lokalizált formázást (és parse-olást) külön metódusok segítik. Ezeket egy külön enum vezérli: java.time.format.FormatStyle. Így tudjuk őket használni:
LocalDateTime ldt = LocalDateTime.parse("2019-02-10T19:30:10"); // csak a dátum stílusának megadása az alapértelmezett locale szerint System.out.println(ldt.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.SHORT))); // 2019.02.10. // csak az idő stílusának megadása az alapértelmezett locale szerint System.out.println(ldt.format(DateTimeFormatter.ofLocalizedTime(FormatStyle.SHORT))); // 19:30 // csak a dátum stílusának megadása tetszőleges locale szerint System.out.println(ldt.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.SHORT).withLocale(Locale.ENGLISH))); // 2/10/19 // dátum és idő stílusának megadása az alapértelmezett locale szerint System.out.println(ldt.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.SHORT))); // 2019.02.10. 19:30 // dátum és idő stílusának eltérő megadása az alapértelmezett locale szerint System.out.println(ldt.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG, FormatStyle.SHORT))); // 2019. február 10. 19:30
A FormatStyle különböző értékeit az alábbi táblázat foglalja össze. Megmutatja, hogy melyik DateTimeFormatter melyik metódusában az enumot az adott adattípusnál használva milyen eredményt kapunk (a teljes minta időpont "2019-02-10T19:30:10+01:00[Europe/Paris]"). A - azt jelenti, hogy az adott adattípusnál az az enum érték azzal a metódussal nincs értelmezve. Ha így próbáljuk használni, DateTimeException-t kapunk. Az ofLocalizedDateTime két paramétere megfelel az ofLocalizedDate és ofLocalizedTime paramétereinek, ezért a táblában nem szerepel.
| FormatStyle | Metódus | LocalTime | LocalDate | LocalDateTime | ZonedDateTime |
|---|---|---|---|---|---|
| SHORT | |||||
| ofLocalizedTime | "19:30" | - | "19:30" | "19:30" | |
| ofLocalizedDate | - | "2019.02.10." | "2019.02.10." | "2019.02.10." | |
| MEDIUM | |||||
| ofLocalizedTime | "19:30:10" | - | "19:30:10" | "19:30:10" | |
| ofLocalizedDate | - | "2019.02.10." | "2019.02.10." | "2019.02.10." | |
| LONG | |||||
| ofLocalizedTime | - | - | - | "19:30:10 CET" | |
| ofLocalizedDate | - | "2019. február 10." | "2019. február 10." | "2019. február 10." | |
| FULL | |||||
| ofLocalizedTime | - | - | - | "19:30:10 CET" | |
| ofLocalizedDate | - | "2019. február 10." | "2019. február 10." | "2019. február 10." |
Már említettem, hogy a dátum/idő kezelő osztályok paraméterei általában valamilyen "Temporal..." paramétert várnak. A java.time.temporal csomag tartalmazza azokat az interfészeket, osztályokat és enumokat, amelyekre felépülnek a dátum/idő számítások. Ezek az interfészek az alacsony szintű műveleteket tartalmazzák, egy általános alkalmazásnak a változóit és paramétereit a konkrét típusban kell kezelnie. Tehát például LocalDateTime vagy ZonedDateTime, nem pedig Temporal interfész. (Ez pont ugyanaz, hogy a változóink String típusúak, nem pedig CharSequence.) Az alábbiakban röviden átfutom az alap-interfészeket és bemutatok néhány olyan jellemzőt és műveletet amiket viszont az általános célú programjainkban is használhatunk.
Temporal és TemporalAccessor
A TemporalAccessor interfész minden idő/dátum adattípus őse (már amennyire egy interfész ős lehet...). Csak olvasható elérést definiál a leendő mezőkhöz. Mivel a legtöbb idő-információnk valamilyen számmal reprezentálható, a get és getLong metódusai egésszel térnek vissza. A kronológia és az időzóna nem reprezentálható számokkal, ezek lekérdezésére a query metódust definiálja.
A TemporalAccessor-ból származó Temporal interfész definiálja azon metódusokat, amelyek hozzáadnak vagy kivonnak időegységeket (minus, plus), elvégzik az idő alapú aritmetikát a sok dátum és idő kezelő osztályon keresztül (until, with). Az idő/dátum tárolására szolgáló mezők definiálásának őse a TemporalField interfész. Ezt a ChronoField enum implementálja, ami egész sor konstanst tartalmaz. Például DAY_OF_WEEK, MINUTE_OF_HOUR vagy MONTH_OF_YEAR.
A mezőkhöz tartozó egységeket a TemporalUnit interfész definiálja. Ezt a ChronoUnit enum implementálja. Egy példa és rögtön érthető lesz: a ChronoField.DAY_OF_WEEK például a ChronoUnit.DAYS és a ChronoUnit.WEEKS kombinációja.
A Temporal interfészben lévő aritmetikai metódusoknak (minus, plus) van TemporalAmount értéket váró változatuk is. TemporalAmount definiálja az időmennyiségeket, ezt implementálják a már jólismert Period és Duration osztályok.
ChronoField (javadoc): a ChronoField enum értékeivel olyan fogalmakat gyárthatunk, mint például "az év harmadik hete" vagy "a nap 11. órája" vagy "a hónap első hétfője". Ha ismeretlen típusú Temporal-lal találkozunk, akkor a TemporalAccessor.isSupported(TemporalField) metódust használhatjuk, ami megmondja, hogy a Temporal támogatja-e az adott mezőt. Az alábbi sor false eredményt ad, vagyis a LocalDate nem támogatja a ChronoField.CLOCK_HOUR_OF_DAY-t:
boolean isSupported = LocalDate.now().isSupported(ChronoField.CLOCK_HOUR_OF_DAY);
IsoFields (javadoc): ebben az osztályban az ISO-8601 naptárrendszernek megfelelő kiegészítő mezők találhatóak. A következő két példa megmutatja, hogyan szerezzük meg egy mező értékét a ChronoField és IsoFields használatával:
Instant time = Instant.now(); int milli = time.get(ChronoField.MILLI_OF_SECOND);// az aktuális instant ezredmásodperc része LocalDate ld = LocalDate.now(); int negyedev = ld.get(IsoFields.QUARTER_OF_YEAR);// megadja, hányadik negyedévben tartunk
WeekFields (javadoc): a hét napjához, hónap hetéhez és év hetéhez szolgáló lokalizált mezők. A szabvány hét mindenhol hét nap, de egyes kultúrákban a hét néhány tulajdonsága eltérő. Az ISO-8601 szerint a hét első napja a hétfő, míg az Egyesült Államokban a vasárnap. Néhány példa:
LocalDate ld = LocalDate.parse("2019-03-24"); WeekFields wf = WeekFields.of(Locale.forLanguageTag("hu")); int nap = ld.get(wf.dayOfWeek());// 7 lesz mert a fenti dátum vasárnapra esett int nap2 = ld.get(wf.weekOfMonth());// 3, ez a hónap harmadik hete int nap3 = ld.get(wf.weekOfYear());// 12, ez az év 12. hete System.out.println(wf.getFirstDayOfWeek());// MONDAY
JulianFields: a ritkán használt Julián naptárhoz használatos dátum mezők. A julián dátumot a csillagászatban használják. (Epocha i. e. 4713. január 1. 12:00:00) Példa:
LocalDate ld = LocalDate.parse("2019-03-24"); long nap = ld.getLong(JulianFields.JULIAN_DAY);// a mapi nap: 2458567 (hogy telik az idő! :-)
ChronoUnit: dátumhoz és időhöz használatos mértékegységek az ezredmásodperctől az évezredig. Akárcsak a ChronoField esetén, nem minden ChronoUnit értéket támogat minden osztály. Az Instant például nem támogatja a ChronoUnit.MONTHS vagy ChronoUnit.YEARS-t. A TemporalAccessor.isSupported(TemporalUnit) metódussal ellenőrizhetjük, hogy egy osztály támogat-e egy adott időegységet. A következő példa false eredményt ad, mert az Instant nem támogatja a ChronoUnit.DAYS egységet:
boolean isSupported = instant.isSupported(ChronoUnit.DAYS);
A ChronoUnit.between metódusról korábban már volt szó. Ez a metódus minden temporal-alapú objektummal működik.
Elég sok interfészről volt szó már eddig ebben a fejezetben, talán kissé áttekinthetőbb (vagy még zavarosabb) lesz, ha a következő ábrán bemutatom, hogyan is néz ki a típusfánk:

TemporalAdjuster
A java.time.temporal.TemporalAdjuster funkcionális interfész adjustInto(Temporal temporal) metódusán keresztül lehet dátum/idő objektumokon műveleteket végezni. Ha egy adjuster-t ZonedDateTime-mal használunk, akkor az új dátum úgy számolódik ki, hogy megtartja az eredeti idő és időzóna értékeket. Vannak előre definiált adjusterek de sajátot is fabrikálhatunk. Két egymással ekvivalens mód van egy TemporalAdjuster használatára:
A java.time.temporal.TemporalAdjusters osztály tartalmazza az előre definiált adjustereket. Ezek statikus metódusként vannak megvalósítva, így static import kifejezéssel is használhatók. 14 ilyen statikus metódus van, ezek mind TemporalAdjuster-el térnek vissza:
LocalDate ld = LocalDate.of(2019, Month.SEPTEMBER, 15);// ez egy vasárnapi nap System.out.printf("A hónap első napja: %s%n", ld.with(TemporalAdjusters.firstDayOfMonth()));// A hónap első napja: 2019-09-01 System.out.printf("A hónap utolsó napja: %s%n", ld.with(TemporalAdjusters.lastDayOfMonth()));// A hónap utolsó napja: 2019-09-30
// A következő hónap első napja: 2019-10-01: System.out.printf("A következő hónap első napja: %s%n", ld.with(TemporalAdjusters.firstDayOfNextMonth()));
// A következő év első napja: 2020-01-01:
System.out.printf("A következő év első napja: %s%n", ld.with(TemporalAdjusters.firstDayOfNextYear()));
System.out.printf("Az év első napja: %s%n", ld.with(TemporalAdjusters.firstDayOfYear()));// Az év első napja: 2019-01-01 System.out.printf("Az év utolsó napja: %s%n", ld.with(TemporalAdjusters.lastDayOfYear()));// Az év utolsó napja: 2019-12-31
// A hónap első hétfője: 2019-09-02: System.out.printf("A hónap első hétfője: %s%n", ld.with(TemporalAdjusters.firstInMonth(DayOfWeek.MONDAY))); // A hónap utolsó vasárnapja: 2019-09-29: System.out.printf("A hónap utolsó vasárnapja: %s%n", ld.with(TemporalAdjusters.lastInMonth(DayOfWeek.SUNDAY)));
// A hónap következő hétfője: 2019-09-16 System.out.printf("A hónap következő hétfője: %s%n", ld.with(TemporalAdjusters.next(DayOfWeek.MONDAY))); // A hónap előző vasárnapja: 2019-09-08 System.out.printf("A hónap előző vasárnapja: %s%n", ld.with(TemporalAdjusters.previous(DayOfWeek.SUNDAY)));
// A hónap második vasárnapja: 2019-09-15 System.out.printf("A hónap második vasárnapja: %s%n", ld.with(TemporalAdjusters.dayOfWeekInMonth(2, DayOfWeek.SUNDAY))); // A hónap második vasárnapja visszafelé: 2019-09-22 System.out.printf("A hónap második vasárnapja visszafelé: %s%n", ld.with(TemporalAdjusters.dayOfWeekInMonth(-2, DayOfWeek.SUNDAY))); // A hónap 12. vasárnapjával túlcsordulunk novemberre: 2019-11-17 System.out.printf("A hónap 12. vasárnapjával túlcsordulunk novemberre: %s%n", ld.with(TemporalAdjusters.dayOfWeekInMonth(12, DayOfWeek.SUNDAY)));
Az előzőeken túl akár saját adjustereket is létrehozhatunk. Legegyszerűbb módja, ha az ofDateAdjuster statikus metódust használjuk lambda kifejezéssel:
// Két nap múlva: 2019-09-17 final TemporalAdjuster KET_NAP_MULVA = TemporalAdjusters.ofDateAdjuster(date -> date.plusDays(2)); System.out.printf("Két nap múlva: %s%n", ld.with(KET_NAP_MULVA));
Bonyolultabb műveletek esetén létrehozhatunk saját osztályt is, ami implementálja a TemporalAdjuster interfész adjustInto(Temporal) metódusát.
TemporalQuery
A TemporalQuery funkcionális interfész queryFrom metódusa használható temporal-alapú objektumkból információ lekérdezésére. Vannak előre definiált lekérdezések de sajátot is barkácsolhatunk. Két egymással ekvivalens mód van egy TemporalQuery használatára:
A java.time.temporal.TemporalQueries osztály tartalmazza az előre definiált lekérdezéseket. Ezekkel meg lehet határozni például egy adott objektum tulajdonságait akkor is, ha az alkalmazás egyébként nem tudja meghatározni a temporális alapú objektum típusát. Ezek statikus metódusokként vannak megvalósítva, így static import kifejezéssel is használhatók. 7 ilyen statikus metódus van, ezek mind TemporalQuery-vel térnek vissza:
TemporalQuery query = TemporalQueries.localDate(); LocalDate ld1 = (LocalDate) LocalDateTime.now().query(query);// itt nyilván lesz LocalDate LocalDate ld2 = (LocalDate) Year.now().query(query);// ez null lesz LocalDate ld3 = (LocalDate) ZonedDateTime.now().query(query);// itt is LocalDate
Természetesen saját lekérdezéseket is létrehozhatunk a TemporalAdjuster-nél megismert módszerrel.
A TemporalAdjuster és a TemporalAccessor az alábbi módon viszonyul a dátum/idő adattípusokhoz:
Az új API-val a régi kódjainkat nem kell egyből kidobni, mert a java.util-ban lévő régi dátum/idő típusok kaptak olyan metódusokat, amelyekkel oda-vissza konvertálhatunk a két API között. Ezekkel simábbá tehetjük az új API-ra való átállást:
Néhány példa:
ZonedDateTime zdt = ZonedDateTime.ofInstant(Calendar.getInstance().toInstant(), ZoneId.systemDefault()); ZonedDateTime zdt2 = new GregorianCalendar().toZonedDateTime(); GregorianCalendar calendarFromZonedDateTime = GregorianCalendar.from(ZonedDateTime.now()); Date dateFromInstant = Date.from(Instant.now()); Instant instantFromDate = new Date().toInstant(); ZoneId zoneIdFromTimeZone = TimeZone.getTimeZone("PST").toZoneId();
Mivel a date/time API teljesen át lett írva, nem lehet a régi és az új metódusok között egyszerű megfeleltetést adni. A legegyszerűbb módszer az új API használatára, ha a régi kódnál használat előtt egyszerűen átkonvertáljuk a fenti metódusokkal az adatokat az újakra. Ha ez nem elegendő akkor sajnos át kell írni a régi kódot. Az alábbi táblázat ad egy vázlatos áttekintést arról, hogy a régi metódusoknak nagyjából melyik felel meg az új API-ban.
| java.util funkció | java.time funkció | Megjegyzés |
|---|---|---|
| java.util.Date | java.time.Instant | Az Instant és Date osztályok hasonlóak. Mindkettő:
|
| java.util.GregorianCalendar | java.time.ZonedDateTime | A ZonedDateTime osztály cseréli le a GregorianCalendar-t. Mindkettő emberi léptékben ábrázolja az időt az
alábbiakban hasonlóképpen:
|
| java.util.TimeZone | java.time.ZoneId / java.time.ZoneOffset | A ZoneId osztály megad egy időzóna azonosítót és hozzáfér az egyes időzónákat meghatározó szabályokhoz. A ZoneOffset osztály csak egy Greenwich/UTC-hez képesti ofszetet ad meg. |
| GregorianCalendar 1970-01-01 dátumra beállítva | java.time.LocalTime | Azon kód ami eddig 1970-01-01-et állított be egy GregorianCalendar példánynak kizárólag az idő számítása céljából, most már lecserélhető LocalTime példánnyal. |
| GregorianCalendar 00:00 időre beállítva | java.time.LocalDate | Azon kód ami eddig 00:00-t állított be egy GregorianCalendar példányba abból a célból, hogy csak a dátum komponenseit használja, most már lecserélhető egy LocalDate példánnyal. (Ez a GregorianCalendar-féle megoldás egyébként is hibás volt, mivel néhány országban évente egyszer nincs éjfél amikor nyári időszámításra állnak át.) |
Java 8-cal végre a Base64 kódolás támogatása is bekerült a szabványos osztálykönyvtárba. Az ezzel kapcsolatos műveleteket a java.util.Base64 osztály valósítja. Ez kizárólag statikus metódusokat tartalmaz, amelyekkel megkaphatjuk a Base64 enkódereket és dekódereket. Az osztály a következő Base64 típusokat támogatja:
Az osztály 7 statikus metódust tartalmaz, amelyek a fenti típusoknak megfelelő dekódereket és enkódereket adnak vissza. Ezt nem részletezem tovább, a nevükből szerintem egyértelmű.
A használata egyszerűbb nem is lehetne. Enkódolás:
String inputString = "Hello Base64 world!\nMásodik sor";
String encodedString = Base64.getEncoder().encodeToString(inputString.getBytes());
Dekódolás:
byte[] decodedByteArray = Base64.getDecoder().decode(encodedString); String decodedString = new String(decodedByteArray);
Az getEncoder() és getDecoder() által visszaadott objektumok egyébként szálbiztosak.
Talán kevéssé ismert tény, hogy Base64 kódolásnál az enkódolt sztring kimenet hossza 3-mal osztható kell legyen. Ha nem így sikerül, akkor az eredményhez kiegészítő "=" karakterek kerülnek, hogy ez a feltétel teljesüljön. Dekódoláskor ezeket a kiegészítő karaktereket a dekóder figyelmen kívül hagyja. De ha mi úgy véljük, nincs szükségünk rájuk akkor enélkül is enkódolhatunk:
String encodedString = Base64.getEncoder().withoutPadding().encodeToString(inputString.getBytes());
A URL kódolás az előzőhöz hasonlóan működik:
String inputUrl = "http://www.egalizer.hu/zene/cdk/kritika.htm?csubpage=/zene/cdk/cd21.htm"; String encodedUrl = Base64.getUrlEncoder().encodeToString(inputUrl.getBytes()); byte[] decodedByteArray = Base64.getUrlDecoder().decode(encodedUrl); String decodedUrl = new String(decodedByteArray);
A MIME kódolás ezek után már aligha meglepetés:
String inputString = "Hosszú várakozás után 2014. március 18-án jelent meg a Java 8 fejlesztői környezet" + " és programozási nyelv (JDK 1.8.0). A 8-as Java talán a legnagyobb előrelépés a 2004-ben megjelent"; String mimeEncodedString = Base64.getMimeEncoder().encodeToString(inputString.getBytes()); byte[] decodedByteArray = Base64.getMimeDecoder().decode(mimeEncodedString); String decodedString = new String(decodedByteArray);
Ez az enkóder 76 karakternél nem hosszabb kimenetet produkál, szükség esetén újsorokkal elválasztva. A fenti esetben:
SG9zc3rDuiB2w6FyYWtvesOhcyB1dMOhbiAyMDE0LiBtw6FyY2l1cyAxOC3DoW4gamVsZW50IG1l ZyBhIEphdmEgOCBmZWpsZXN6dMWRaSBrw7ZybnllemV0IMOpcyBwcm9ncmFtb3rDoXNpIG55ZWx2 IChKREsgMS44LjApLiBBIDgtYXMgSmF2YSB0YWzDoW4gYSBsZWduYWd5b2JiIGVsxZFyZWzDqXDD qXMgYSAyMDA0LWJlbiBtZWdqZWxlbnQ=
A MIME enkódernek van egy olyan változata is aminek kézzel adhatjuk meg egy sor hosszát és az újsor karaktert:
String mimeEncodedString = Base64.getMimeEncoder(10, "\n".getBytes()).encodeToString(inputString.getBytes());
A karakterhossz lefelé lesz kerekítve a 4 legközelebbi többszörösére (10 esetén tehát 8 lesz).
A Java 6-ban jelent meg a ScriptEngine, ami lehetővé tette Java kódból különböző szkriptnyelvek beágyazott használatát. Új szcriptnyelvhez egyszerűen a javax.script.ScriptEngine-t kell implementálni. A támogatott nyelvek közé tartozott a JavaScript is. A Java 8 egy új, Nashorn nevű JavaScript motort hozott be, ami felváltotta a korábbi Rhino-t. A Nashorn lehetővé teszi a metódushívást JavaScript és a Java között, collection-ök kezelését és még mindenféle nyalánkságot. Mivel ez a Java 11-ben már tovább nem támogatott (deprecated), nem fogok belemélyedni az izgalmaiba. Egy kis példa:
ScriptEngineManager manager = new ScriptEngineManager(); ScriptEngine engine = manager.getEngineByName("JavaScript"); System.out.println(engine.getClass().getName()); engine.eval("print('Hello World!');"); System.out.println(engine.eval("function f() { return 1; }; f() + 1;"));
A Java 8 egy csapat parancssori eszközt is hozott magával.
jjs
A jjs egy különálló paracssori Nashorn motor. JavaScript forráskód fájllistát vár paraméterként és lefuttatja azokat. Csináljunk például egy func.js fájlt a következő tartalommal:
function f() {
return 1;
};
print( f() + 1 );
Parancssorból ezt a fájlt így tudjuk lefuttatni:
jjs func.js
Akit bővebben érdekel a jjs, itt a teljes dokumentáció.
jdeps
A jdeps megmutatja a class fájlok csomagszintű vagy osztályszintű függőségeit. Bemenetként .class fájlt, könyvtárat vagy jar fájlt vár. A függőségeket alapesetben a konzolra írja és csomagonként csoportosítja. Ha a függőség nem érhető el a classpath-on akkor not found jelenik meg. Hivatalos dokumentáció.
Példaként a népszerű spring framework core API függőségeinek egy részlete:
jdeps.exe spring-core-5.1.6.RELEASE.jar
spring-core-5.1.6.RELEASE.jar -> not found
spring-core-5.1.6.RELEASE.jar -> c:\Program Files\Java\jdk1.8.0_162\jre\lib\rt.jar
org.springframework.asm (spring-core-5.1.6.RELEASE.jar)
-> java.io
-> java.lang
-> java.lang.reflect
-> java.util
org.springframework.cglib (spring-core-5.1.6.RELEASE.jar)
-> java.lang
org.springframework.cglib.beans (spring-core-5.1.6.RELEASE.jar)
-> java.beans
-> java.lang
-> java.lang.reflect
-> java.security
-> java.util
-> org.springframework.asm spring-core-5.1.6.RELEASE.jar
-> org.springframework.cglib.core spring-core-5.1.6.RELEASE.jar
[...]
org.springframework.cglib.transform (spring-core-5.1.6.RELEASE.jar)
-> java.io
-> java.lang
-> java.net
-> java.security
-> java.util
-> java.util.zip
-> org.apache.tools.ant not found
-> org.apache.tools.ant.types not found
-> org.springframework.asm
[...]
JVM kapcsolók
Mivel eltűnt a permgen terület és bejött a metaspace, az ezekhez tartozó parancssori kapcsolók is módosultak. Eltűntek a -XX:PermSize és –XX:MaxPermSize kapcsolók és bejöttek a -XX:MetaSpaceSize és -XX:MaxMetaspaceSize kapcsolók.