A Java bájtkódról írt gyorstalpalóm még 2014-ben készült, így már igencsak itt van az ideje, hogy tovább vájkáljunk a Java belsejében, mégpedig egy másik szép téma, a szemétgyűjtő, polgári nevén garbage collector (GC) témakörében. Ehhez persze nem árt egy picit mélyebben tisztában lenni a Java memóriafelépítésével és még a HotSpot virtuális gép belvilágát is érinteni fogjuk. A megértéshez azért mindenképpen ajánlatos a korábbi cikk elolvasása is. Most ebben az írásban pedig elsősorban az Oracle Java VM implementációjával, a HotSpottal foglalkozom, mégpedig annak 64 bites verziójával. A kódrészletek és a tesztprogramok a következő Java verziókat használják:
Forró nyomon
A HotSpot-ra keresztelt virtuális gépet még 1999. április 27-én mutatta be a szép emlékű Sun Microsystems. A Java eredeti, még kizárólag értelmezőt (interpreter) használó virtuális gépe mellett az 1.2-es Java-ban a HotSpot bekapcsolható kiegészítésként szerepelt, de az 1.3-tól már a Sun elsődleges JVM-e lett. Miután az Oracle 2010 januárjában felvásárolta a Sun-t (a felvásárlás első szerződése egyébként 2009 április 20-án kelt), továbbra is ez maradt a Java elsődleges virtuális gépe. A képet árnyalja, hogy a Sun még 2006-ban elhatározta, hogy a Java-t nyílt forráskódúvá teszi. Az elhatározást tett követte, megnyitották a teljes Java, ezzel együtt pedig a HotSpot forráskódját. Ebből jött létre az OpenJDK, ami az Oracle mellett tehát szintén HotSpot-ot használ.
A helyzetet tovább bonyolítja, hogy a Java nyíltsága miatt boldog-boldogtalan készített hozzá saját virtuális gépet. A Wikipédia nem kevesebb, mint 77 különféle JVM implementációt sorol fel, ezek egy részét természetesen ma már nem fejlesztik. Kavarodást jelentett az is, amikor a BEA Systems által fejlesztett JRockit JVM (amihez a BEA is felvásárlással jutott) bekerült a képbe. Az Oracle éhsége közismert, a Sun előtt egy évvel, 2008-ban a BEA Systems-et is felvásárolta, így a HotSpot előtt már megvolt neki a JRockit mint házon belüli JVM. A zavar abból látható, hogy az Oracle dokumentációi hol a JRockit-ról, hol a HotSpot-ról szólnak. Előfordul, hogy az ember keres valamit a HotSpot-ról és észre sem veszi hogy egyszercsak már a JRockit-ról olvas. Ez szép félreértéseket tud okozni, például itt, ahol a kérdező azt tudakolja, hogy mi a MaxDirectMemorySize paraméter értéke a SUN 1.6-os JVM-jében, majd az első válaszoló belinkeli a JRockit dokumentációját. Az Oracle terve mindenesetre az, hogy hosszú távon a JRockit-ot beleolvassza a HotSpot-ba, a JDK8 már részben egy ilyen, összevont kódbázison alapul. JRockit JVM-ből Java 7-es változat már meg sem jelent.
Régi bölcsesség, hogy a legtöbb program futási idejének nagy részét a kód egy kis részének végrehajtásával tölti. Ezt a bölcsességet fogadták meg a HotSpot tervezői is, mert ahelyett, hogy futásidőben metódusról metódusra lefordítana mindent, a HotSpot azonnal elkezdi futtatni a programot egy értelmezővel és közben analizálja azt, hogy kritikus részeket (hot spot - forró pont) figyeljen meg, majd pedig ezeket fordítsa le és optimalizálja. Mivel elkerüli a kód ritkán használt részeinek (vagyis nagy részének) fordítását, a HotSpot több figyelmet tud szentelni a program teljesítménykritikus részére anélkül, hogy a fordítási idő jelentősen megnőne. Ez a forrópont-figyelés a program futása során is folytatódik, tehát gyakorlatilag a teljesítményt dinamikusan, a felhasználó igényei szerint alakítja. Ennek a megközelítésnek lényeges tulajdonsága, hogy a fordítást elodázza addig, míg a kód már futott egy darabig (egy darabig - gépi, nem pedig felhasználói idővel mérve). Eközben információt gyűjt a kód használatáról, ami alapján már okosabb optimalizációt tud végezni.
A HotSpot-nak valójában kétféle verziója van: egy kilensoldali és egy szerveroldali VM. A kettő ugyanarra a kódbázisra épül, de különböző fordítót és környezeti beállításokat alkalmaz. (Indításkor -client vagy -server kapcsolóval adhatjuk meg, hogy melyiket szeretnénk használni.) A szerver VM esetén a hosszú távú minél nagyob működési sebesség elérése a lényeg, ez folyamatosan működő szerverekhez alkalmazható, ahol a gyors indulási idő vagy a futás közbeni memóriafoglalás kevésbé fontos. A kliens VM arra lett optimalizálva, hogy minél gyorsabban elinduljon és minél kevesebb memóriát használjon. Ez a lokális kódminőségre koncentrál és kevés globális optimalizációt végez, mivel azok gyakran nagyon költségesek a fordítási idő szempontjából.
Kliens fordító: egy egyszerű, ún. háromfázisú fordító. Az első fázisban egy platformfüggetlen frontend egy magasszintű közbenső reprezentációt (high-level intermediate representation; HIR) hoz létre a bájtkódból. A második fázisban ebből a platformspecifikus backend alacsonyszintű közbenső reprezentációt (low-level intermediate representation; LIR) állít elő. Az utolsó fokozat végzi el a LIR-en a regiszterhozzárendelést, emellett egyszerű optimalizálást is végez, majd pedig gépi kódot generál belőle.
Szerver fordító: ez már minden hagyományos optimalizációt megcsinál, amit például egy C++ fordító is. Ilyen például a sosem hívott kód kiküszöbölése, ciklusinvariáns kiemelése, közös alkifejezés kiküszöbölése, konstans továbbterjesztés, globális értékszámolás és kódmozgatás. Emellett olyan optimalizálásokat is elvégez, amik speciálisan a Java nyelvhez készültek. Ilyen a nullellenőrzés és a tartományellenőrzés kiküszöbölése valamint a kivételek dobásának optimalizálása. A fordító nagymértékben hordozható és egy gépleíró fájlon alapul, ami a célhardver minden aspektusát leírja. Bár kategóriájában ez a fordító elég lassúnak számít, még mindig sokkal gyorsabb, mint a hagyományos, optimalizáló fordítók.
Többszintű fordítás
A többszintű fordítást azért vezették be a Java SE 7-ben, hogy a szerver VM indulási sebessége közelebb legyen a kliens VM indulási sebességéhez. A szerver VM esetén alapesetben az értelmező gyűjt információt a metódusokról amiket aztán a fordító felhasznál. A többszintű rendszerben induláskor viszont nem csak az értelmező dolgozik, hanem egyes metódusokat a fordító lefordít (de még nem optimalizál szénné) és azután ezt a lefordított változatot elemzi a beépített profiler. Mivel a lefordított változat alapvetően gyorsabb, mint az interpreteres, a program már az elemző fázisban (profiling) nagyobb sebességgel fut. A többszintű fordítás 32 és 64 bites módokban is támogatott és a -XX:+TieredCompilation opcióval lehet bekapcsolni. (Java 7-ben ez alapesetben kikapcsolt, Java 8-ban pedig már alapesetben bekapcsolt.) Megjegyzendő egyébként, hogy ez a Java 7-ben még nem volt teljesen kiforrott és a bekapcsolása azt eredményezte, hogy nagyjából 24 óra futás után az alkalmazás nemhogy gyorsult volna, hanem elkezdett lassulni és egy idő után teljesen megállt.
A HotSpot az Oracle dokumentációi szerint kliens VM esetén 1000, szerver VM esetén pedig 10000 interpretált meghívás után gyűjt annyi információt, hogy megfelelően optimalizálva lefordíthassa az adott metódust. Amennyiben nem szeretnénk semmiféle optimalizáló fordítást, akkor a -Xcomp parancssori opcióval kikényszeríthetjük, hogy a JVM minden metódust az első meghíváskor azonnal lefordítson. De a fordítás előtti meghívások számát is módosíthatjuk a -XX:CompileThreshold paraméterrel. Ha pedig az egész lefordítási mulatságot ki szeretnénk kapcsolni, ne habozzunk a -Xint parancssori opciót használni. Ekkor csak az interpreter fogja futtatni a bájtkódunkat.
A szerver JVM tehát sok optimalizációt tud elvégezni a bájtkódú programon, azonban a nyelv néhány speciális tulajdonsága miatt több esetben különleges megoldásokra van szükség a kívánt teljesítmény eléréséhez. Java esetén a legtöbb metódushívás virtuális, ami azt jelenti, hogy a statikus fordítóprogram-optimalizációkat (különösen az olyan globális érvényűeket, mint a metódusok kifejtése) sokkal nehezebb elvégezni. Ráadásul az osztályok dinamikus betöltési lehetőségének következtében a Java alapú programok futásidőben is megváltozhatnak. A fordítónak nemcsak azt kell észrevennie, hogy a dinamikus betöltés miatt mikor válnak az ilyen optimalizációk érvénytelenné, de vissza kell tudnia vonni illetve újra végre kell tudnia hajtani ezeket az optimalizációkat a program végrehajása közben még akkor is, ha ez a vermen lévő aktív metódushívásokat is érinti. Ezt anélkül kell elvégeznie, hogy bármilyen módon hatással lenne a programok végrehajtására. A HotSpot VM ún. adaptív (vagyis alkalmazkodó) optimalizációt alkalmaz, amely mindezeket a problémákat képes kezelni.
Metódus kifejtés
Amikor a HotSpot elég információt gyűjtött a program forró pontjainak végrehajtásáról, nemcsak natív kóddá fordítja azokat, hanem metódus kifejtést (inline) is végez rajtuk. A kifejtés drámaian le tudja csökkenteni a metódushívások gyakoriságát, viszont talán még fontosabb, hogy így sokkal nagyobb kódblokkok jönnek létre, amiket hatékonyabban lehet tovább optimalizálni. A kifejtés tehát más optimalizációkkal együtt igazán hatásos, mert egyrészt lehetővé másrészt hatékonyabbá is teszi azokat. (Viszont ki is kapcsolhatjuk az egész inline-olást a fenébe a -XX:-Inline parancssori kapcsolóval.)
A metóduskifejtés során a fordító kiküszöböli a metódushívásokat úgy, hogy az azok által végrehajtott kóddal lecseréli a hívó utasítást. Tekintsük a következő példát, ami a könnyebb érthetőség kedvéért Java nyelven van, a fordító természetesen mindezt gépi kódban végzi el, de a lényeg ugyanaz:
public int addAndInc(int a, int b) { return a + b + 1; }
Ezt pedig hívjuk így:
public void doEverything() { int var1 = addAndInc(6, 10); int var2 = addAndInc(9, 20); ... // a metódus további része itt most lényegtelen }
A fordító azt látja, hogy hatékonyabb lenne kifejteni a két metódushívást, nosza meg is teszi:
public void doEverything() { int var1 = 6 + 10 + 1; int var2 = 9 + 20 + 1; ... // a metódus további része itt most lényegtelen }
A példából is sejthető, hogy ez az egyszerű módszer a virtuális metódusok használata miatt jelentősen bonyolódhat, hiszen az addAndInc metódus megváltozhat egy alosztály betöltésével, így a korábbi inline-olt kód már nem lesz jó. A fordítót lehet segíteni final metódusok és osztályok deklarálásával, hiszen azzal jelezzük, hogy azok már nem fognak változni később, de persze ez nem jelenti azt, hogy a HotSpot valóban kifejtést is végez majd azon a kódon, hiszen az optimalizálást (és egyáltalán a lefordítást) számos egyéb paraméter befolyásolja. Teljesen biztos módszer tehát nincs a programozó kezében a kifejtés kényszerítésére, azt mindig futásidőben fogja eldönteni a JVM.
Dinamikus visszaoptimalizálás
Bár a metóduskifejtés fontos optimalizálás, a dinamikus betöltés jelentősen bonyolítja a helyzetet, mert megváltoztatja a programon belüli kapcsolatokat. Egy új osztály tartalmazhat új metódusokat is, amiket ki kell fejteni megfelelő helyeken. Ezért a HotSpot-nak képesnek kell lennie dinamikus visszaoptimalizálásra (dynamic deoptimization), vagyis a korábban már optimalizált kód visszaállítására, amit szükség szerint újra optimalizálni tud. Ja, és mindezt futás közben! Enélkül a kifejtést nem lehetne biztonságosan elvégezni Java alapú programokban. A HotSpot kliens és szerver változata is támogatja a dinamikus visszaoptimalizálást. Ez azért is fontos, mert ez tesz lehetővé további optimalizációkat:
Objektumcsomagolás
A 64 bites korszak eljövetelével bekerült a HotSpot-ba egy objektumcsomagolás nevű lehetőség is, hogy az adattípusok közötti elpazarolt területet minél kisebbre csökkentsék. Ez főként a 64 bites rendszerekben hatásos, de némi pozitív hozadéka még 32 bites környezetben is van. A megértése példán keresztül a legegyszerűbb. Tekintsük a következő osztályt:
public class Button { char shape; String label; int xposition; int yposition; char color; int joe; Object mike; char armed; }
A modern processzorok esetén a legnagyobb teljesítmény érdekében nem árt, ha az adattípusaink megfelelő (például négybájtos) határra illeszkednek. Az illeszkedés megvalósítása viszont területet pazarol a color és a joe (három bájt a 4-bájtos int határ miatt) és a joe és mike (négy bájt egy 64 bites VM-ben, hogy mutató határra essen) között. Az objektumcsomagolás a mezőket a következőképp rendezi át:
public class Button { ... Object mike; int joe; char color; char armed; ... }
Így már nincs elpazarolt memóriaterület.
Mutatók és tömörített oop-ok
Érdekességképp megemlíthető, hogy a HotSpot előtt még handle-ök voltak objektum referenciaként használva. Bár ez szemétgyűjtés során könnyűvé tette az objektumok áthelyezését, jelentős teljesítménybeli hátrányt jelentett, mert a példányváltozók eléréséhez kétszintű indirekcióra volt szükség. A HotSpot már nem használ handle-öket, az objektum referenciák közvetlen mutatókként vannak implementálva. Ez C-sebességű példányváltozó-elérést tesz lehetővé. Amikor egy objektumot a memóriafelszabadítás során át kell helyezni (a memória töredezettségének elkerülése érdekében), a szemétgyűjtő felelős azért, hogy megtalálja és frissítse az összes arra hivatkozó referenciát.
Mi az a handle?
A handle röviden egy környezetfüggő egyedi azonosító. A környezetfüggőség azt jelenti, hogy az egyik kontextusban használt handle nem feltétlenül használható máshoz. A handle valamilyen erőforrásra hivatkozik, mint például memória, megnyitott fájl, stb. Windows esetén a handle egy olyan absztrakció, ami elrejti a valódi memóriacímeket az API használója elől és így lehetővé teszi az operációs rendszernek, hogy a felhasználói program számára átlátszó módon átrendezze a memóriát. A handle feloldása mutatóvá megadja a kívánt memóriacímet, a handle felszabadítása pedig érvénytelenné teszi a mutatót. Tekinthető például úgy, mint index egy mutatótáblában. A rendszer API hívásoknál ezt az indexet lehet használni, a rendszer pedig így tetszőlegesen módosítani tudja a táblában lévő valódi mutatókat.
A HotSpot-ban egy objektumra hivatkozó menedzselt mutatót "oop"-nak, vagyis ordinary object pointer-nek hívnak. Egy oop jellemzően ugyanolyan méretű, mint egy natív gépi mutató, vagyis egy 64 bites rendszeren 64 bit. 32 bites rendszeren a heap legnagyobb mérete egy kicsivel kevesebb, mint 4 GB lehet, ez pedig sok alkalmazásnak kevés, különösen szerveres környezetben. 64 bites rendszeren viszont egy adott program által használt heap-méret akár másfélszer akkora is lehet, mint ugyanaz a program 32 bites rendszeren, ennek pedig nagyrészt a menedzselt mutató nagyobb mérete az oka. Bár a memória manapság már nem túl költséges, a sávszélesség és a cache (adott esetben pedig akár a memória is) még mindig eléggé behatárolja a lehetőségeket, a heap jelentős növekedése tehát nem kívánatos. Ezért találták ki a tömörített oop-okat.
A menedzselt mutatók a Java heap-en 8 bájtos határra illesztett objektumokra mutatnak. A tömörített oop-ok gyakorlatilag menedzselt mutatók (bár a JVM belsejében nem minden esetben) és ez pedig a 64 bites heap báziscímtől számított 32 bites objektum offszet. Fontos különbség, hogy ezek nem bájt, hanem objektum offszetek, amik négy milliárd objektumot (nem pedig bájtot) tudnak megcímezni. Így tehát akár 32 GB-nyi heap méretig bezárólag lehet objektumokat kezelni. A használathoz ezeket skálázni kell 8-cal és hozzá kell adni a Java heap báziscímhez, hogy megtaláljuk azt az objektumot, amelyre hivatkozunk. A tömörített oop-okkal használt objektumméretek kompatibilisek a 32 bites módban használt oop-okkal.
Dekódolásnak hívják, amikor egy 32 bites tömörített oop átkonvertálódik 64 bites natív heap-címmé. Ennek inverz művelete a kódolás (milyen meglepő). A tömörített oop-okat a Java SE 6u23 óta alapértelmezettként támogatja a JVM. Java 7-ben 64 bites JVM esetén szintén alapértelmezettnek számítanak, ha a -Xmx nincs megadva vagy az értéke kisebb, mint 32 GB.
Nulla alapú oop-ok
Amikor 64 bites JVM folyamatok tömörített oop-okat használnak, a JVM azt kéri az operációs rendszertől, hogy a heap-nek 0 virtuális címen kezdődjön a címtartománya. Amennyiben ezt az operációs rendszer támogatja, akkor a JVM nulla alapú tömörített oop-okat használ. Ilyenkor egy 64 bites mutató a báziscím hozzáadása nélkül dekódolható egy 32 bites objektum-offszetből. 4 GB-nál kisebb heap méret esetén a JVM objektumoffszet helyett bájtoffszetet is tud használni és ebben az esetben még a 8-cal való skálázás is kihagyható. 64 bites cím 32 bites offszetté kódolása ilyenkor hasonlóan hatékony. 26 GB méretig a Solaris, Linux és Windows rendszerek is képesek általában 0 báziscímre heap-et foglalni.
Szál
Valószínűleg mindenki tudja, mi a különbség programozásban a processz és a szál között, így aztán senkit nem fog sokkoló meglepetésként érni a következő pár mondat: egy processz egy alkalmazás éppen végrehajtott példánya, egy szál pedig egy éppen végrehajtott processzen belüli végrehajtási út. Egy processz tartalmazhat több szálat. Fontos különbség, hogy egy adott processzen belüli szálak ugyanazt a címtartományt használják, míg különböző processzek nem. Java esetén maga a JVM a processz, ami végrehajtja a Java programunkat, az pedig több szálat létrehozhat és futtathat párhuzamosan. A HotSpot-ban közvetlen leképezés van egy Java szál és egy natív operációs rendszerbeli szál között. Miután egy Java szálhoz szükséges minden összetevő megvan (thread-local memória, foglalási pufferek, szinkronizációs objektumok, vermek és programszámláló), létrejön egy natív szál. Amikor a Java szál megszűnik, a natív szál pályafutása is végetér. Ennek következtében az operációs rendszer felelős a szálak ütemezéséért és azért, hogy erőforrást és CPU-időt kapjanak. A natív szál, miután létrejött, meghívja a Java szál run() metódusát. Amikor a run() befejeződik, a kezeletlen kivételek lekezelődnek, a natív szál pedig megvizsgálja, hogy a JVM-et is le kell-e állítani (például ha ez volt az utolsó nem-démon szál). Amikor a szál leáll, az összes natív és Java szálhoz rendelt erőforrás felszabadul.
JVM rendszer szálak
A jConsole vagy egyéb nyomkövető használatával meg lehet sasolni, hogy még egy egyszerű program esetén is számos szál fut a háttérben. Ezek a fő programszálak mellett futnak, ami a public static void main (String[]) hatására jött létre illetve amiket az hozott létre. A fő rendszer-háttérszálak a HotSpot-ban a következők (egyes rendszer szálakat a jConsole nem mutat, de egy thread dump igen):
VM Thread: ez a szál vár az ún. safe-point-hoz szükséges események megjelenésére. Ehhez azért kell külön szál, mert ezen kívül mindegyiknek szükséges safe-point-ban lenni, ugyanis a heap-en csak így történhetnek módosítások. Ez a szál olyan műveleteket végez, mint a mindent megállító szemétgyűjtés, thread és stack dump-ok, szál felfüggesztés és a rögzített zárolás visszavonás (biased locking revocation).
Rögzített zárolás visszavonása
Amennyiben egy objektumot csak egy szál zárol, a VM képes olyan optimalizálásra, hogy az objektumot ahhoz a szálhoz rögzíti (bias) és onnantól kezdve azon az objektumon végzett további atomi műveleteknek nincs szinkronizációs költségük. Ez jelentős sebességnövekedést eredményezhet. Ezt a -XX:+UseBiasedLocking kapcsolóval lehet beállítani a JVM-ben, de már a Java 6 óta alapértelmezett. A tulajdonképpeni szinkronizálás csak akkor történik meg, ha másik szál is megpróbálja zárolni azt az objektumot. Ilyenkor vissza kell vonni (revoke) a zárolást. Ez a művelet a rögzítet zárolás visszavonás (biased locking revocation).
VM Periodic Task Thread: ez felelős az időzített eseményekért (pl megszakítások), amelyeket periodikus műveletek ütemezésére lehet használni.
GC szálak: ezek a szálak valósítják meg a különböző típusú szemétgyűjtő műveleteket.
Fordító szálak: ezek a szálak fordítják a bájtkódot natív kódra futásidőben.
Signal dispatcher szál: fogadja az operációs rendszertől JVM processzeknek küldött natív jelzéseket (signal) és a JVM-en belül kezeli azokat úgy, hogy meghívja a megfelelő JVM metódusokat.
Reference Handler: azokat a műveleteket végzi, amit minden referencia objektummal meg kell csinálni, ilyen például az, hogy berakja őket a finalization sorba.
Finalizer: kivesz objektumokat a finalization sorból és meghívja azok finalize() metódusát. Ezután a szemétgyűjtő már felszabadíthatja azok helyét. Ha nem képes lépést tartani a nagyobb prioritású folyamatokkal, amelyek ebbe a sorba rakják az objektumokat, akkor egy idő után java.lang.OutOfMemoryError lesz a jutalmunk.
DestroyJavaVM: leállítja a Java VM-et, mikor a program végetér. Az idő legnagyobb részében szépen várakozik, amíg a VM apokalipszisa el nem érkezik.
Mi az a safe point?
A safe point egy olyan pont a program végrehajtása során, amikor minden GC gyökérelem ismert (GC gyökérelemekről később bővebben lesz szó) és a teljes heap tartalom konzisztens. Safe point esetén az összes Java kódot futtató szál működése felfüggeszthető. Vannak JVM-ek, ahol adott szálra is lehet safe pointot érvényesíteni anélkül, hogy a teljes világ megállna, de a HotSpot nem ilyen. Mielőtt egy szemétgyűjtő elindulhatna, minden szálnak blokkolódnia kell egy safe point-ban. (Speciális esetben a JNI, vagyis Java natív kódot futtató szálak tovább futhatnak, ha közben nem szólnak a JVM-hez. De ha Java objektumokhoz próbálnak hozzáférni, Java metódust akarnak meghívni vagy vissza akarnak térni natív módból, akkor ezek is felfüggesztésre kerülnek a safe point végéig.) A program szempontjából a safe point a kód egy speciális része, ahol a végrehajtó szálat a szemétgyűjtő kedvéért blokkolni lehet. Ennek minősül például a legtöbb hívási pont. Erre az egész mókára azért van szükség, hogy a safe point kezdeményezőjének teljes hozzáférére legyen a JVM adatstruktúráihoz és olyan őrültségeket tudjon csinálni, mint objektumok mozgatása a heap-en vagy éppen végrehajtás alatt álló metódus kódjának lecserélése.
A HotSpot-ban a safe point protokollja együttműködésen alapul: minden szál maga ellenőrzi a safe point státuszt és ha szükséges, akkor parkolópályára áll. A JVM-ek valamilyen hatékony mechanizmust használnak, hogy rendszeresen vizsgálják, szükséges-e megállás. A fordító a lefordított kódba is safe point ellenőrzéseket rak bizonyos pontokra (általában hívások utáni visszatérésekhez vagy ciklusok törzsének végére, mielőtt a ciklus elejére visszaugrás megtörténne). A HotSpot egy egyszerű, globális "go to safepoint" jelzőt használ. Ez gyakorlatilag egy olyan lap, ami védett akkor amikor egy safe pointra van szükség és nem védett egyébként. A safepoint figyelő mechanizmus pedig ennek a lapnak egy adott címéről próbál adatot olvasni. Ha az olvasás csapdázódik, akkor a szál tudja, hogy safepoint-ba kell lépnie. Ez a mechanizmus azért is jó, mert a modern szuperskalár processzorokban nem okoz csővezeték-kiürítést a safepoint vizsgálatnál.
Kétségtelen, hogy a szemétgyűjtés a legfontosabb funkció, aminek a kedvéért safepointokat kell a kódban kijelölni, azonban nem az egyetlen. Ezekben az esetekben használ a JVM safepoint-okat:
A safepointokra többnyire nem kell nagy figyelmet fordítani, mert a GC-t kivéve ezek általában nagyon gyorsan lefutnak. De ha valami probléma adódna, van néhány diagnosztikai lehetőség a JVM parancsok között:
Zárolás
A Java által alkalmazott zárolási módszer (akárcsak a legtöbb többszálú osztálykönyvtár) nagyon pesszimista. Ha csak a legkisebb esélye fennáll annak, hogy két vagy több szál elér adatot konkurens módon, akkor egy nagyon szigorú zárolási megoldást kell használni. Mindezt annak ellenére, hogy kutatások kimutatták, hogy a zárolásokra nagyon ritkán - ha egyáltalán - van valóban szükség. Tehát egy szálnak, ami zárolást kér, ritkán kell várni arra, hogy megkapja. A zárolás kérésének költsége viszont nem nulla, ezért legjobb lenne elkerülni. A JVM fejlesztői ezért többféle optimalizálást vezettek be a zárolásra:
A részletezés előtt nézzünk egy példát!
Vezérlés analízis
A vezérlés analízis (escape analysis) az, amikor a futó program összes referenciájának hatókörét megvizsgáljuk. Ez a HotSpot profilerének szokványos munka. Ha a HotSpot ezzel meg tudja állapítani, hogy egy objektumra hivatkozó minden referencia korlátozott, lokális láthatóságú és egyik referencia sem tud kilépni ebből egy bővebb láthatósági körbe, akkor a JIT számos futásidejű optimalizálást végre tud rajta hajtani. Egyik ilyen a zárolás kiküszöbölés. Amikor referenciák zárolása lokális hatókörre korlátozódik, akkor csak az a szál fér hozzá, ami létrehozta. Ilyenkor tehát a szinkronizált blokkban lévő értékekért sosem fog több szál versenyezni, tehát sosem lesz igazán szükség a zárolásra és ezért nyugodt szívvel elhagyható. Tekintsük a következő metódust:
public String concatBuffer(String s1, String s2, String s3) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); sb.append(s3); return sb.toString(); }
Vegyük észre, hogy az sb változtó csak a metóduson belül él, ráadásul a rá való hivatkozások sosem lépnek ki abból a hatókörből, amelyben deklarálva lettek. Nincs rá mód tehát, hogy másik szál hozzáférjen az sb lokális másolatához. Ezért tudható, hogy az sb-t védő zárolások elhagyhatók.
Rögzített zárolás
A rögzített zárolást (biased locking) az a megfigyelés inspirálta, hogy a legtöbb zárolást egynél több szál sosem éri el az élettartama alatt. De még azon ritka alkalmakkor is, amikor több szál között oszlik meg az adat, az elérések között ritkán van versengés. A rögzített zárolás előnyének megértéséhez az előbbi megfigyelés fényében először nézzük meg, hogyan is kapnak zárolást az adatok.
A zárolás megszerzése kétlépéses folyamat. Először igényelni kell (lease), aztán amikor az megvan, akkor lehet kérni a zárolást. Az igényléshez viszont egy elég költséges atomi műveletre van szükség. A zárolás feloldása általában feloldja az igénylést is. És mi van akkor, ha a szál egy szinkronizált kódblokkon iterál végig és azt szeretnénk optimalizálni? Megtehetnénk, hogy az egész ciklust szinkronizálttá tesszük, így a szál csak egyszer igényli meg a zárolást, nem pedig minden iterációban. Ez viszont azért nem jó megoldás, mert más szálakat zárhat ki az adat igazságos eléréséből. Sokkal okosabb megoldás, ha rögzítjük (bias) a zárolást a ciklust tartalmazó szálhoz. Ilyenkor a szálnak nem kell eldobnia az igénylést a zárolás végén, így a következő zárolások megszerzése sokkal kevésbé lesz költséges. A szál csak akkor engedi el az igénylést, ha másik szál is szeretne zárolást kapni. A Java 6 óta a HotSpot már alapból rögzített zárolást használ.
Lock coarsening
Egy másik optimalizálási módszer a lock coarsening vagy összefűzés. Ez akkor alkalmazható, amikor szomszédos szinkronizált blokkok összefűzhetőek egyetlen szinkronizált blokká. Ennek egy másik változata, amikor több szinkronizált metódust fűzünk egybe, ami akkor alkalmazható, ha ugyanazt a zárolt objektumot használja az összes. Tekintsük a következő példát:
public static String concatToBuffer(StringBuffer sb, String s1, String s2, String s3) { sb.append(s1); sb.append(s2); sb.append(s3); return sb.toString(); }
Ebben az esetben a StringBuffernek nem helyi a láthatósági köre és akár több szál is elérheti. A vezérlés analízis meg fogja mutatni, hogy ennek a zárolását nem lehet biztonságosan elhagyni. Ha a zárolást történetesen csak egy szál érné el, akkor persze a rögzített zárolás is alkalmazható. Érdekes módon a döntés, hogy a JVM összefűzze-e ezeket, attól függetlenül is eldönthető, hogy hány szál verseng az erőforrásért. A példában a zárolás négyszer egymás után lesz megkérve: háromszor az append metódusnál és egyszer a toString-nél. A fordító első tennivalója a metódusok kifejtése, de ezután már mind a négy műveletet módosítani lehet úgy, hogy a zárolást már csak egyszer kelljen megszerezni úgy, hogy a teljes metódus törzset körbefogja. Ennek persze az lesz a hatása, hogy hosszabb kritikus szakaszt kapunk, tehát lehetséges, hogy más szálak várakozni fognak és csökken az áteresztőképesség. Ezért egy ciklusban lévő zárolást sosem fűz ösze a JVM úgy, hogy az a teljes ciklust magába foglalja.
Szál felfüggesztés és spinning
Amikor egy szál arra vár, hogy egy zárolást egy másik szál elengedjen, általában felfüggeszti az operációs rendszer. A felfüggesztés azzal jár, hogy az operációs rendszer esetleg még azelőtt elveszi tőle a processzort, mielőtt a kvantumja lejárna (preemptív operációs rendszerekben általában kvantumnak hívják azt az időszeletet, ameddig egy szál futhat, mielőtt az ütemező egy másik szálnak adná a CPU-t). Amikor a kérdéses zárolást birtokló szál kilép a kritikus szekciójából, a felfüggesztett szálat fel kell ébreszteni, majd újra kell ütemezni és kontextuskapcsolással CPU-t adni neki. Ez mind extra feladatot ad a JVM-nek, az operációs rendszernek és a hardvernek is.
Ebben az esetben a következő megfigyelés használható: a zárolásokat általában nagyon rövid ideig tartják meg az igénylők, amiből az következik, hogy ha még várnánk egy kicsit, akkor lehet, hogy megkapnánk a zárolást anélkül, hogy fel kellene függeszteni a várakozó szálat. Ehhez csak annyit kell tenni, hogy a szálban cikluson belül tevékenyen várakozunk. Ez a spinningnek nevezett technika. A spinning olyan esetekben működik jól, amikor a zárolások tartama nagyon rövid. Ha a zárolásra hosszabb ideig van szükség, akkor a spinning fölöslegesen pazarolja a CPU-t és semmi értelmeset nem csinál. A spinninget a JDK 1.4.2-ben hozták be és két fázisra osztották: először alapértelmezetten 10 iterációt várakozik, majd csak utána függesztődik fel a szál.
Adaptív spinning
A JDK 1.6 hozta be az adaptív spinning-et, ahol a spinning iterációk száma immár nem rögzített, hanem a korábbi spin próbálkozások alapján meghatározott szabály adja meg a zárolás tulajdonosának állapota mellett. Ha a közelmúltban a spinning sikerült ugyanazon a zárolt objektumon és a zárolást tulajdonló szál épp fut, akkor a spinning valószínűleg újra sikeres lesz. Ezért most már relatív hosszabb időtartammal is lehet próbálkozni, mondjuk 100 iterációval. Ha viszont a spinning nem valószínű, hogy sikeres lesz, akkor teljesen le lehet állítani, így nem pazarol CPU időt.
Mielőtt a szemétgyűjtőt a maga valójában meg mernénk közelíteni (nem harap), azért nem árt, ha az objektumok memóriabeli felépítéséről és egyéb izgalmas dolgokról is van némi tudomásunk. A Java nyelvben a programozók tehát objektumokat birizgálnak. Egy objektumhoz szükséges memória mindig a heap-en lesz lefoglalva és ez a művelet mindig impliciten, a new operátorral történik. Tegyük fel, hogy van egy Vadállat nevű osztályunk. Ebből az osztályból csinálunk egy példányt:
Vadállat vad = new Vadállat();
A JVM ilyenkor kiszámítja, hogy mennyi memória szükséges (a Vadállat osztály definíciójától függően), aztán lefoglalja azt a heap-en és egy erre a memóriaterületre hivatkozó referenciát tárol a vad változóban. Amikor tehát egy Vadállat objektumot akarunk létrehozni, nem kell megadnunk, hogy mennyi memóriát szeretnénk (milyen meglepő). A kifejezés new Vadállat() része megmondja a Java-nak, hogy mit akarunk csinálni. A JVM pedig felhasználja a Vadállat osztály definícióját a szükséges memóriaméretet kiszámolásához. Hogyan néz ki valójában egy objektum a heap-en?
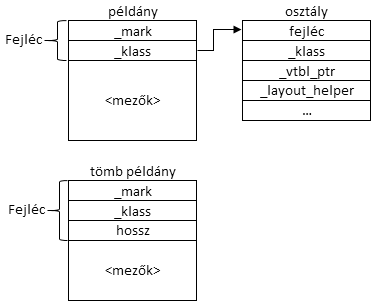
A memóriában egy objektumot egy oopDesc nevű adatszerkezet ír le. Minden objektumnak van egy fejléce (header) és egy adatrésze. A fejléc mindenféle, a JVM által használt könyvelési információt tárol. Itt van például egy mutató az objektum osztályára, információ az objektum szemétgyűjtési státuszáról, zárolási információ, tömb esetén annak hossza, stb. Az adatterületen tárolódik az objektum összes példányváltozójának értéke. Egy adott JVM implementáció esetén a fejléc felépítése rögzített, az adat terület felépítése viszont az objektum típusától függ. A HotSpot két gépi szót használ fel az objektum fejlécének (32 bites architektúra esetén egy szó 4 bájt), kivéve ha az objektum tömb, mert ekkor hármat. Ekkor egy extra szó szolgál a tömb hosszának tárolására. Így néz ki egy objektum és egy osztály a memóriában HotSpot JVM esetén:
Egy objektum memóriabeli fejléce részletesebben az alábbi módon néz ki:
32 bites JVM
| Objektum fejléce (64 bit) | Állapot | |
|---|---|---|
| Mark szó (32 bit) | Klass szó (32 bit) | |
| identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | normál |
| thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | biased |
| ptr_to_lock_record:30 | lock:2 | osztályra mutató oop | lightweight locked |
| ptr_to_heavyweight_monitor:30 | lock:2 | osztályra mutató oop | heavyweight locked |
| | lock:2 | osztályra mutató oop | szemétgyűjtésre kijelölve |
64 bites JVM
| Objektum fejléce (128 bit) | Állapot | |
|---|---|---|
| Mark szó (64 bit) | Klass szó (64 bit) | |
| használatlan:25 | identity_hashcode:31 | használatlan:1 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | normál |
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | biased |
| ptr_to_lock_record:62 | lock:2 | osztályra mutató oop | lightweight locked |
| ptr_to_heavyweight_monitor:62 | lock:2 | osztályra mutató oop | heavyweight locked |
| | lock:2 | osztályra mutató oop | szemétgyűjtésre kijelölve |
64 bites JVM tömörített oop-okkal
| Objektum fejléce (96 bit) | Állapot | |
|---|---|---|
| Mark szó (64 bit) | Klass szó (32 bit) | |
| használatlan:25 | identity_hashcode:31 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | normál |
| thread:54 | epoch:2 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | osztályra mutató oop | biased |
| ptr_to_lock_record:62 | lock:2 | osztályra mutató oop | lightweight locked |
| ptr_to_heavyweight_monitor:62 | lock:2 | osztályra mutató oop | heavyweight locked |
| | lock:2 | osztályra mutató oop | szemétgyűjtésre kijelölve |
Tömbök esetén a fejléc mindhárom esetben kiegészül egy plusz 32 bites mezővel, ami a tömb méretét tárolja. Egy objektum kezdete mindig 8 bájtos határra van illesztve. A mark szó mezőinek jelentése:
A klass mező egy mutató az osztály metaadatra (később még lesz róla bővebben szó). Mivel egy objektum összes mezőihez tartozó információk egyenkénti letárolása nagyon gazdaságtalan lenne, a klass jó módszer ezeknek az információknak példányok közötti megosztására. Fontos azonban megjegyezni, hogy a klass által hivatkozott metaadatok különböznek az osztályok adataitól, amik egy osztálybetöltés eredményeképpen állnak elő. A különbség:
A memóriában a fejléc után következnek az osztály mezői. A mezők mindig a típusuk méretének megfelelően vannak illesztve; tehát az int-ek 4 bájtos határra, a long-ok pedig 8 bájtos határra. Ennek teljesítménybeli okai vannak: illesztett adatokat a modern processzorok sokkal hatékonyabban be tudnak olvasni egy regiszterbe, mint nem illesztetteket. Föntebb már volt szó az objektumcsomagolásról, nézzük meg ezt és a mezők tárolását a gyakorlatban! (A példák mindig a -XX:-UseCompressedOops JVM kapcsolóval készültek, vagyis a tömörített oop-ok kikapcsolásával.)
Tekintsük a következő osztályt:
public class Vadallat { byte a; int b; boolean c; long d; Object e; }
Ha a JVM nem rendezné át a mezőket, akkor ennek egy példánya a memóriában (természetesen a teszthez használt 64 bites JVM-ek esetén) így nézne ki:
[FEJLÉC: 16 bájt] 16 [a: 1 bájt] 17 [kitöltés: 3 bájt] 20 [b: 4 bájt] 24 [c: 1 bájt] 25 [kitöltés: 7 bájt] 32 [d: 8 bájt] 40 [e: 8 bájt] 48
Ebben az esetben a kitöltés 14 bájtot elpazarolna és az objektum 48 bájtot foglalna a memóriából (32 bites JVM esetén 40-et). A mezőket a JVM ezért a következő szabály szerint rendezi át:
Az átrendezéssel a memória így fog kinézni a fenti objektum esetén:
[FEJLÉC: 16 bájt] 16
[d: 8 bájt] 24
[b: 4 bájt] 28
[a: 1 bájt] 29
[c: 1 bájt] 30
[kitöltés: 2 bájt] 32
[e: 8 bájt] 40
Ezúttal csak 2 bájt van kitöltésnek használva és az objektumok csak 40 bájt memóriát foglalnak (32 bites JVM esetén ez 32 lenne). Most már tudjuk, hogyan számoljuk ki bármely, az Object-ből származó osztály példányának memóriafoglalását. Egy jó példa mondjuk a java.lang.Boolean osztály. Íme ennek a memóriakiosztása:
[FEJLÉC: 16 bájt] 16
[érték: 1 bájt] 17
[kitöltés: 7 bájt] 24
Egyetlen Boolean objektumpéldány 24 bájt memóriát eszik (32 bites JVM esetén ez 16, hiszen a fejléc ott csak 8 bájtos).
Alosztályok és egyéb állatfajták
A következőkben megnézzük, hogy mit csinál a JVM a leszármazott osztályoknál. Az osztályhierarchiában különböző szinten lévő mezőket a JVM sosem keveri össze. Elsőként az ősosztály mezői jönnek a korábbiak szerint, aztán pedig az alosztályé. Nézzük ezt a példát:
public class Osallat { long a; int b; int c; } public class Vadallat extends Osallat { long d; }
A Vadallat egy példánya a következőképpen fog kinézni a memóriában:
[FEJLÉC: 16 bájt] 16 [a: 8 bájt] 24 [b: 4 bájt] 28 [c: 4 bájt] 32 [d: 8 bájt] 40
Amikor az ősosztály mezői nem illeszkednek a 8 bájtos határra, a JVM kitöltést alkalmaz az ősosztály és a leszármazott mezői között. Íme egy példa:
public class Osallat { byte a; } public class Vadallat extends Osallat { byte b; } [FEJLÉC: 16 bájt] 16 [a: 1 bájt] 17 [kitöltés: 7 bájt] 24 [b: 1 bájt] 25 [kitöltés: 7 bájt] 32
Látható az a mezőt követő 7 bájtos kitöltés. Ezt a helyet a Vadallat mezői nem használhatják. Ezen kívül érdemes megemlíteni, hogy 32 bites JVM esetén van még egy utolsó eset. Ha meg akarunk takarítani némi helyet, mert a leszármazott első mezője long vagy double, viszont az ősosztály mezői nem 8 bájtos határon végződnek, a JVM megszegi az átrendezési szabályt. Ilyenkor megpróbál int-et, short-ot, majd bájtot és aztán referenciákat tenni az alosztálynak fenntartott hely elejére, amíg fel nem tölti a 8 bájtos illeszkedéshez szükséges rést. Ez 64 bájtos JVM esetén nem szükséges, mert ott az ősosztályok mindig 8 bájtos határon kell, hogy végződjenek, ahogy az előbbiekben láttuk.
A tömbök esetén a fejléc kiegészül egy plusz 8 bájtos mezővel, ami a length változó értékét tárolja. Ezt követik a tömbben lévő elemek, de a tömbök természetesen szintén 8 bájtos határra illesztettek. Így néz ki egy bájttömb a memóriában:
[FEJLÉC: 24 bájt] 24
[[0]: 1 bájt] 25
[[1]: 1 bájt] 26
[[2]: 1 bájt] 27
[kitöltés: 5 bájt] 32
32 bites JVM-nél long tömbök esetén a fejlécet követi egy 4 bájtos kitöltés, mert ott a fejléc csak 12 bájtos. A fenti példák tömörített oop-ok esetén 64 bites JVM-nél nem változnak, mert a fejléc mérete még úgy is 8-cal osztható marad. Nem statikus belső osztályoknak van egy kiegészítő "rejtett" mezője, ami egy referenciát tartalmaz a külső osztályra. Ez azonban teljesen szokványos referencia, ami a mezőátrendezés szabályai szerint kezelhető, bár emiatt a belső osztályok esetén mindig van egy plusz 8 bájtos méretköltség.
Osztályok felépítése a memóriában Java 7 esetén a következőképpen néz ki (Java 8 esetén ez megváltozott és kikerült a heap-ről, ezért annak tárgyalásától eltekintek):
32 bites JVM
| Mező | Hossz | Típus |
|---|---|---|
| fejléc | 4 bájt | |
| klass | 4 bájt | mutató |
| C++ vtbl ptr | 4 bájt | mutató |
| layout helper | 4 bájt | |
| super check offset | 4 bájt | |
| name | 4 bájt | mutató |
| secondary super cache | 4 bájt | mutató |
| secondary supers | 4 bájt | mutató |
| primary supers | 32 bájt | 8 elemű mutatótömb |
| java mirror | 4 bájt | mutató |
| super | 4 bájt | mutató |
| first subklass | 4 bájt | mutató |
| next sibling | 4 bájt | mutató |
| modifier flags | 4 bájt | |
| access flags | 4 bájt |
64 bites JVM
| Mező | Hossz | Típus |
|---|---|---|
| fejléc | 8 bájt (tömörített oop-ok esetén 4 bájt) | |
| klass | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| C++ vtbl ptr | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| layout helper | 4 bájt | |
| super check offset | 4 bájt | |
| name | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| secondary super cache | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| secondary supers | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| primary supers | 64 bájt (tömörített oop-ok esetén 32 bájt) | 8 elemű mutatótömb |
| java mirror | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| super | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| first subklass | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| next sibling | 8 bájt (tömörített oop-ok esetén 4 bájt) | mutató |
| modifier flags | 4 bájt | |
| access flags | 4 bájt |
Az osztály és objektum leírója le sem tagadhatnák, hogy közük van egymáshoz, hiszen mindkettő a fejléccel és a klass mutatóval kezdődik. A JVM fejlesztői egyébként szándékosan a leggyakrabban használt mezőket rendezték előre, mégpedig azért, hogy az esetleges gyorsítótárazás jobban működjön (a JVM egyik fejlesztője a HotSpot forráskódjában meg is jegyezte: ha nem használ, hát ártani biztos nem árt). Az osztály mezői a következők:
A módosító flag-ek értékei:
Public: 0x00000001
Protected: 0x00000002
Private: 0x00000004
Abstract: 0x00000400
Static: 0x00000008
Final: 0x00000010
Strict: 0x00000800
Nézzünk meg most már egy konkrét példát is az osztály memóriabeli szerkezetére. Az Osallat osztály eddig is jó szolgálatot tett, legyen most (ebből ugyan már Vadallat most nem fog származni, de annyi baj legyen...):
public final class Osallat { byte a; }
Ennek a memóriabeli képe a következőképpen fog kinézni (alább pedig a színkódokkal megjelölt mezők, egymás utáni sorrendben):
0| 1| 2| 3| 4| 5| 6| 7| 8| 9| A| B| C| D| E| F|
00 01| 00| 00| 00| 00| 00| 00| 00| 70| 02| 00| 80| 00| 00| 00| 00|
10 88| 0A| 41| 57| 00| 00| 00| 00| 18| 00| 00| 00| 40| 00| 00| 00|
20 20| 86| A7| 0A| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00|
30 58| 1C| 00| 80| 00| 00| 00| 00| 38| 2C| 00| 80| 00| 00| 00| 00|
40 08| E9| 27| 80| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00|
50 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00|
60 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00|
70 00| 00| 00| 00| 00| 00| 00| 00| 28| 19| 38| D9| 00| 00| 00| 00|
80 38| 2C| 00| 80| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00| 00|
90 88| E1| 27| 80| 00| 00| 00| 00| 11| 00| 00| 00| 31| 00| 20| 20| |
A Java eredetileg biztonságos, menedzselt környezetnek készült. A HotSpot azonban tartalmaz egy kiskaput, ami számos alacsonyszintű műveletet biztosít a memória és a szálak közvetlen piszkálásához. Ezt a kiskaput (sun.misc.Unsafe) egyébként maga a Java is használja olyan csomagokban, mint a java.nio vagy a java.util.concurrent. Éles környezetben természetesen az Unsafe használata egyáltalán nem ajánlott, mert ez az API eléggé veszélyes, nem hordozható és nem is szabványos. Nekünk viszont most remek eszközt ad ahhoz, hogy (ha van elég bátorságunk) belenézzünk a HotSpot JVM belsejébe és néhány trükköt is megcsináljunk. Néha C++ debugolás nélkül alkalmas a JVM belsejének tanulmányozásához, néha pedig használható profiling és fejlesztői eszközökhöz.
A sun.misc.Unsafe annyira nem támogatott, hogy a JDK fejlesztői speciális ellenőrzésekkel gátolták az elérését: a konstruktora privát és a getUnsafe() gyártófüggvény hívóját a bootstrap osztálybetöltőnek (classloader) kell betöltenie. Amikor nem ez a helyzet (tehát minden felhasználói kódnál), akkor a hívása - ahogy az alábbi kódrészletből látható - SecurityException kivételt fog dobni.
public final class Unsafe { ... private Unsafe() { } private static final Unsafe theUnsafe; ... public static Unsafe getUnsafe() { Class arg = Reflection.getCallerClass(); if (arg.getClassLoader() != null) { throw new SecurityException("Unsafe"); } else { return theUnsafe; } } ... }
(Megjegyzendő, hogy ha Eclipse fejlesztő környezetben szeretnénk az Unsafe osztályt használni, akkor "Access restriction: The type 'Unsafe' is not API" fordítási hibát kapunk. A szabvány javac fordító viszont csak warninggal figyelmeztet, hogy ez az API nem szabványos és a jövőben megváltozhat. Az Eclipse korlát kiküszöböléséhez a Java build path elérési jogainak beállítását kell módosítani.)
Bár JDK 8 alatt a getUnsafe feltételvizsgálata így néz ki:
if (!VM.isSystemDomainLoader(arg.getClassLoader()))
De ez ne bizonytalanítson el minket, az isSystemDomainLoader ugyanúgy csak egy nullvizsgálatot végez.
A Java esetén használható sokféle osztálybetöltő (classloader) közül a bootstrap osztálybetöltő az egyetlen, ami még nem Java osztályként, hanem natív kódként van implementálva. Ez tölti be a JVM indulásakor az összes kódot, ami szükséges az alapvető Java runtime funkcionalitáshoz. Egy osztálynál az Osztaly.class.getClassLoader() hívás adja vissza az azt betöltő classloader-t. A HotSpot esetén ez null-t ad vissza, ha az osztályt a bootstrap classloader töltötte be. Ilyen például a String, ArrayList, System, stb. Saját Vadallat osztályunk viszont már nem.
A Vadallat.class.getClassLoader() már valami ilyesmit fog visszaadni:
sun.misc.Launcher$AppClassLoader@73d16e93
A lényeg tehát, hogy nem tudunk csak úgy egyszerűen példányosítani egy Unsafe-et. Szerencsére ott van azonban a theUnsafe mező, amit fel lehet használni arra, hogy kapjunk egy Unsafe példányt. Írhatunk egy segédmetódust, ami megcsinálja ezt nekünk reflection-ön keresztül. Például egy ilyet:
public static Unsafe getUnsafe() { try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); return (Unsafe) f.get(null); } catch (Exception e) { /* */ } }
Na és mire lehet használni az Unsafe-et? Például ezekre:
Nem azért ismertük meg ezeket a titkos praktikákat, hogy kihasználatlanul hagyjuk, úgyhogy nézzünk valami izgalmasat ezek használatával. A tesztek során továbbra is a Vadallat osztályt használjuk, ezen nézzük meg, hogyan lehet megszerezni egy objektum címét, kilistázni mezőinek szerkezetét, stb.
1. trükk: egy osztály memóriacímének megszerzése
Egy Java osztály memóriacímének lekérdezésére nincs egyszerű módszer, ezért piszkos trükkökhöz kell folyamodnunk. Abból viszont kettő is van.
1. megoldás: ahogy láttuk, minden objektum tartalmaz egy _klass nevű mutatót az osztályára (de csak a konkrét osztályra, interface-re vagy absztrakt osztályra nem). Ha egy objektum memóriacíme megvan, akkor az osztály címének megszerzése már gyerekjáték. Ez a módszer persze csak olyan osztályoknál használható, amikből lehet példányosítani. Ez az objektum fejlécében a második mező (32 bites JVM-nél az objektum memóriacímétől az offszet 4, 64 bites JVM-nél 8). Ennek a kiolvasásához már használhatjuk az Unsafe osztályt.
32 bites JVM esetén:
Vadallat vadallatObject = new Vadallat(); int addressOfVadallatClass = unsafe.getInt(vadallatObject, 4L);
64 bites JVM esetén:
Vadallat vadallatObject = new Vadallat(); long addressOfVadallatClass = unsafe.getLong(vadallatObject, 8L);
64 bites JVM esetén tömörített oop-okkal:
Vadallat vadallatObject = new Vadallat(); int addressOfVadallatClass = unsafe.getInt(vadallatObject, 8L);
2. megoldás: ezzel bármilyen osztály (interface, annotáció, absztrakt osztály, enum) címe meghatározható. Az osztályok is tartalmaznak ugyanis saját magukra hivatkozó mutatót. Java 7-ben egy osztálydefiníció memóriacíme a következőképp alakul:
Ezek az offszetek egyébként a class fájl parser-jének forrásában vannak rejtett mezőként definiálva. A cím meghatározásához szükséges kódrészletek:
32 bites JVM esetén:
int addressOfVadallatClass = unsafe.getInt(Vadallat.class, 80L);
64 bites JVM esetén:
long addressOfVadallatClass = unsafe.getLong(Vadallat.class, 160L);
64 bites JVM esetén tömörített oop-okkal:
int addressOfVadallatClass = unsafe.getInt(Vadallat.class, 84L);
2. trükk: egy objektum memóriacímének megszerzése
Egy objektum memóriacímének megszerzése kicsit izgalmasabb, mint az osztályé, erre ugyanis nincs közvetlen Unsafe metódus, de ez rajtunk nem fog ki. A meghatározáshoz felhasználjuk az objektumszerkezetről frissen szerzett tudásunkat és egy java.lang.Object típusú 1 elemű segédtömböt:
32 bites JVM esetén:
Object[] helperArray = new Object[1]; helperArray[0] = vadallat; long baseOffset = unsafe.arrayBaseOffset(Object[].class); int addressOfObject = unsafe.getLong(helperArray, baseOffset);
64 bites JVM esetén:
Object[] helperArray = new Object[1]; helperArray[0] = vadallat; long baseOffset = unsafe.arrayBaseOffset(Object[].class); long addressOfObject = unsafe.getLong(helperArray, baseOffset);
A példákban a Vadallat egy példányát használjuk, de ez természetesen bármely másik osztály bármely példánya lehetne!
Méricskélés
A C/C++ nyelvektől eltérően a Java-ban nincs sizeOf operátor, ami megmondaná, hogy a primitív típusok vagy objektumok mennyi helyet fogyasztanak. Pedig ez akár még hasznos is lehetne az I/O műveletekhez, memóriakezeléshez, stb. Persze egy ilyen operátornak Java-ban azért nincs igazából értelme, mert a primitív típusok méretét a nyelv specifikációja megmondja és a nyelvben nincsenek címaritmetikához használható mutatók.
Mindenesetre kétféleképpen lehet meghatározni azt, hogy egy osztály mezői mennyi memóriát foglalnak:
A shallow size jelenti az objektum méretét a saját mezőivel, de az általa esetleg tartalmazott objektum referenciákkal nem. Ez utóbbi fogalom a deep size, ami kiterjeszti a shallow size-t azon objektumok méretével, amikre az objektum hivatkozik.
sizeOf() függvény
Egy osztály példányának mérete a layout helper mezőben tárolódik, ami a metaadatban a negyedik. Az objektum klass mezője megadja az osztály metaadatok címét, annak pedig 64 bites JVM esetén a 24. offszetjén van a layout helper. Ezt kiolvasva megvan a shallow size:
public static long sizeOf(Object object) { return unsafe.getInt(normalize(unsafe.getLong(object, 8L)) + 24L); } public static long normalize(long value) { if (value >= 0) { return value; } return (~0L >>> 64) & value; }
A normalize() függvényt azért kell használni, mert a 231 és 232 közötti címek automatikusan negatív számmá konvertálódnak, vagyis komplemens alakban tárolódnak. Nézzük az eredményeket 64 bites JVM-ben:
public class Osallat { } // 16: 8 a mark szó és 8 a klass szó
public class Osallat { int a; } // 24: 16 a fejléc, 4 az int mező és 4 a kitöltés
public class Osallat { int a; long b; } // 32: 16 a fejléc, 8 a long, 4 az int és 4 a kitöltés
Ez a függvény nem működik tömbökkel, mert ott a layout helper mezőnek más jelentése van, de persze a fentebbi információk tükrében lehet általánosítani a sizeOf() függvényt úgy, hogy a tömböket is támogassa.
Közvetlen memóriakezelés
Az Unsafe lehetővé teszi, hogy közvetlenül foglaljunk és szabadítsunk fel memóriát az allocateMemory és a freeMemory metódusokkal. A lefoglalt memória nincs a GC hatálya alatt és nem korlátozza a maximum JVM heap méret sem. Ez a lehetőség egyébként megvan a NIO csomag off-heap puffereivel is, de az Unsafe esetén az az érdekes, hogy lehetségessé válik leképezni szabványos Java referenciákat off-heap memóriaterületre:
Osallat osallat = new Osallat();// ez lesz a kísérleti egerünk osallat.a = 200; long size = sizeOf(osallat); long offheapPointer = getUnsafe().allocateMemory(size); getUnsafe().copyMemory(osallat, // forrásobjektum 0, // a forrásoffszet nulla - a teljes objektumot másolni kell null, // a cél abszolút címmel van megadva, tehát a célobjektum null offheapPointer, // célcím size);// a tesztobjektumunk át lesz másolva a heap-en kívülre Pointer p = new Pointer();// a Pointer csak egy handler, ami valamely objektum címét tárolja long pointerOffset = getUnsafe().objectFieldOffset(Pointer.class.getDeclaredField("pointer")); getUnsafe().putLong(p, pointerOffset, offheapPointer); // a mutatót a tesztobjektum heap-en kívüli másolatára állítjuk osallat.a = 100; // átírjuk az eredeti objektumban lévő x értékét System.out.println(((Osallat) p.pointer).a); // 200-at fog kiírni
Tehát még valódi objektumokat is lehetséges manuálisan lefoglalni és felszabadítani, nem csak bájtpuffereket. Persze nagy kérdés, hogy mit csinál a GC ilyen trükkök után. Saját tesztjeimből az a tapasztalatom, hogy - természetesen - csak a heap-en lefoglalt területtel törődik, a többit már a programnak kell felszabadítania.
Öröklés final osztályból és a void*
Tegyük fel, hogy van egy metódusunk, ami egy sztringet vár paraméterként, viszont jó lenne átadni neki a String által nem átvitt adatot is. Java-ban ennek két szokványos módja van: a plusz infót thread-local változóba rakjuk vagy pedig statikus mezőt használunk. Nos az Unsafe behoz még két plusz lehetőséget: átadjuk az információ címét sztringként illetve a plusz infó osztályát a String-ből származtathatjuk. Ebből az első megközelítés hasonló az előző részben látottakhoz - csak át kell adni a plusz információ címét a Pointert használva, a hívott metódusban pedig létre kell hozni egy új Pointer-t, ami arra mutat. Tehát bármilyen paraméter, amin keresztül át tudunk adni címet, használható a C void* megoldásához hasonlóan. A második módszerhez először nézzük a következő kódrészletet, ami jónak tűnik, de persze futásidőben kiköp nekünk egy ClassCastException kivételt:
public class Csomag { public int titok; } ... Csomag csomag = new Csomag(); csomag.titok = 777; String message = (String) (Object) csomag;// ClassCastException handler(message); .... static void handler(String message) { System.out.println(((Csomag) (Object) message).titok); }
Ahhoz, hogy ez működjön, módosítani kell a Csomag osztályt úgy, hogy szimulálja az egyébként final String-ből való származást. Az ősosztályok listája egy osztályszerkezetben a primary supers tömbben van, ami 64 bites JVM esetén az 56. bájttól kezdődik. Itt elsőként az objektumra hivatkozó mutató van, másodikként pedig magára a Csomag-ra hivatkozó mutató (64. bájt), mivel a Csomag-ot közvetlenül az Object osztályból örököltettük. Elég hozzáadni a következő kódot a Csomagot Stringgé cast-oló kód elé:
long csomagClassAddress = normalize(unsafe.getLong(csomag, 8L)); long stringClassAddress = normalize(unsafe.getLong("", 8L)); unsafe.putAddress(csomagClassAddress + 64, stringClassAddress);// a Csomag őse immár a String
Láss csodát: a cast (de nekem nagyon tetszik a magyar típuskényszerítés szó is) most már jól működik. Persze ez az átalakítás nagyon csúnya és szembeköpi a Java nyelvi megkötéseit. Egy óvatosabb megközelítéshez még két lépés kell:
Konklúzió
A sun.misc.Unsafe majdnem korlátlan lehetőségeket biztosít a VM futásidejű adatszerkezeteinek módosításához és felfedezéséhez. Bár magához a Java nyelvű fejlesztéshez nem igazán használható és nem ajánlott, az Unsafe remek eszköz akárkinek, aki tanulmányozni akarja a HotSpot VM-et C++ kód debuggolás nélkül.
Most már közelediünk a szemétgyűjtő belvilágához, de még mielőtt nyakig merülnénk benne, érdemes egy olyan nyelvi tulajdonságot megismerni, ami már régóta a Java része, mégis kevesen tudnak róla. A Java 1.2-es változata 1998 decemberében jelent meg és elég jelentős mérföldkőnek számított a nyelv történetében; ha az újdonságok számát csak mennyiségi tekintetben is nézzük: a platformban lévő osztályok száma megháromszorozódott a korábbi verzióhoz képest. Ami minket itt ezek közül érdekel, az egy kis rész, mégpedig a java.lang.ref csomagból. Ez (azóta is) öt osztályt tartalmaz:
A három különféle Reference alosztály a Reference absztrakt osztályból származik és egy másik objektumra való referencia huncut kezelését teszik lehetővé. A kívánt referenciát a leszármazott osztályok konstruktorának lehet átadni és utólag nem módosítható. A Reference ősosztálynak négy metódusa van:
Szemétgyűjtővel foglalkozó cikk nem lehet teljes a különböző típusú referenciák ismertetése nélkül, ezt itt sem úszhatjuk meg, nézzük sorba tehát, mik is ezek.
Erős Pista - helyett erős referencia
Erős referenciára a java.lang.ref nem tartalmaz külön alosztályt, de erre nincs is szükség, ugyanis ezt nap mint nap használja minden háziasszony, akarom mondani Java programozó. Ez pedig nem más, mint a szokványos Java referencia, mint például a következő:
StringBuffer buffer = new StringBuffer();
Ez létrehoz egy új StringBuffer objektumot és egy erős referenciát tárol hozzá a buffer változóban. Ezeket a referenciákat nem a spenót, hanem az teszi erőssé, ahogyan szemétgyűjtés esetén viselkednek. Ha egy objektumot el lehet érni a GC gyökérből erős referenciák láncán (strongly referenced - erősen elérhető), akkor nem pucolható ki szemétgyűjtéskor. (A GC gyökérről később még sokat fogunk hallani. Itt most elég annyi, hogy a GC gyökér a szemétgyűjtés kiindulópontja; minden, a program által aktuálisan használt referencia a GC gyökérből valamilyen útvonalon elérhető.) Amikor a szakirodalom referenciáról beszél, akkor általában az erős referenciát értik alatta. Ezért ebben a cikkben - hacsak nem egyértelmű - én is úgy teszek, mintha ez szakirodalom lenne. Az alábbi példában egy nem túl izgalmas dolog történik: addig toljuk a cuccot, amíg lehet - erős referenciákkal.
import java.util.LinkedList; import java.util.List; public class StrongTest { private byte[] getData() { return new byte[1024*1024]; } public void testStrongReferences() throws Exception { List<byte[]> bigStore=new LinkedList<>(); while(true){ bigStore.add(getData()); } } public static void main(String[] args) throws Exception { new StrongTest().testStrongReferences(); } }
Amikor az erős referencia túl erős
Tegyük fel, hogy egy alkalmazás olyan osztályokat használ, amikből nem lehet tovább származtatni. Ezek lehetnek egyszerűen final kulcsszóval is jelölve vagy lehet valami bonyolultabb oka is, mint például egy ismeretlen implementációval rendelkező gyártófüggvény (factory method) által visszaadott interface. Legyen példaként egy grafikus alkalmazásunk és abban egy Widget osztályunk, amit valamilyen okból nem praktikus vagy nem lehetséges kiterjeszteni új funkcionalitás hozzáadásához. Mi van akkor, amikor egy ilyen objektumról kiegészítő információt kell tárolnunk? Például szükséges lehet minden Widget sorszámát nyomon követni, de a Widget osztálynak nincs sorszám mezője, és mivel a Widgetből nem lehet leszármaztatni, nem is adhatunk hozzá ilyet. Minket persze nem lehet ilyen könnyen elrettenteni, hát mire való a HashMap?
serialNumberMap.put(widget, widgetSerialNumber);
Sima ügy! Legalábbis látszólag, ugyanis az erős referencia majdnem biztosan problémákat fog okozni. 100% bizonyossággal tudnunk kell ugyanis, hogy egy adott Widget sorozatszámára mikor nincs többé szükség és ilyenkor el kell távolítani a map-ből, mert különben memóriaszivárgást kapunk (ha nem távolítjuk el a Widget-et, amikor kellene) vagy pedig hiányzó sorszámokkal találkozunk (ha eltávolítunk olyan Widget-eket, amiket még mindig használ valami). Ezek pont olyan problémák, amik szemétgyűjtés nélküli nyelvekben merülnek fel, pedig a Java nem ilyen.
Egy másik szokványos probléma az erős referenciákkal a gyorsítótárazás, különösen olyan nagy méretű adatoknál, mint a képek. Tegyük fel, hogy van egy alkalmazásunk, ami a felhasználók által feltöltött képekkel foglalkozik, mint például egy weboldal tervező eszköz. Ezeket a képeket gyorsítótárazni szeretnénk, mert a lemezről nagyon költséges lenne mindig felolvasni és el akarjuk kerülni a lehetőségét annak, hogy egyszerre két másolatunk legyen egy képből a memóriában. Egy kép-gyorsítótár megoldja a problémát, viszont a szokványos erős referenciáknál a referencia kikényszeríti, hogy a kép mindig a memóriában maradjon, emiatt pedig a programozónak kell valahogy eldöntenie, hogy egy képnek mikor nem kell tovább a memóriában lennie és mikor lehet eltávolítani a cache-ből, hogy a szemétgyűjtő megkaparinthassa. Vagyis manuálisan kell reprodukálni a szemétgyűjtő működését. Na itt jönnek be a gyenge referenciák.
Gyenge referencia
Egy gyenge referencia (weak reference) olyan referencia, ami nem elég erős annak kikényszerítéséhez, hogy egy objektum a memóriában maradjon. Ez lehetővé teszi, hogy kihasználjuk a szemétgyűjtő azon képességét, hogy meghatározza, egy objektumot használ-e még valami. Így ezt nem nekünk kell megtenni. Így lehet gyenge referenciát csinálni:
WeakReference<Widget> weakWidget = new WeakReference<Widget>(widget);
A kódban a weakWidget.get() hívással tudjuk lekérdezni a tulajdonképpeni widget objektumot. A gyenge referencia nem elég erős hozzá, hogy meggátolja a szemétgyűjtést, tehát ha már nincs másik erős referencia a widget-re, vagyis erős referenciával senki más nem használja, akkor a weakWidget.get() null-t ad vissza. A fenti widget-sorozatszám probléma megoldásához a legegyszerűbb a beépített WeakHashMap osztály használata. A WeakHashMap pont úgy működik, mint a HashMap, kivéve, hogy a kulcsok (nem az értékek!) gyenge referenciát használnak. Ha egy WeakHashMap kulcsa szemétté válik, akkor a bejegyzést teljes egészében eltávolítja a JVM. Ez egyből megoldja a korábbi problémákat és nem igényel más módosítást azon kívül, hogy lecseréljük a HashMap-et WeakHashMap-re. Ha követjük a kódolási konvenciókat, vagy a map-jeinkre a Map interface-en keresztül hivatkozunk, további kódmódosítás nem is szükséges, hátradőlhetünk. Illetve várjunk még egy picit azzal a hátradőléssel:
Referenciasorok
Ha egy WeakReference objektum többé nem hivatkozik semmire, mert azt már megette a szemétgyűjtő, akkor igazából ő maga is fölöslegessé válik. A programunknak tehát időről időre érdemes kitakarítania a nem funkcionáló gyenge referenciákat. (Tehát erős referenciák helyett most már gyenge referenciákat kell ugyanúgy piszkálgatunk...) Egy WeakHashMap-nek például el kell távolítania a haszontalan bejegyzéseket, hogy ne csak egy folyamatosan növekvő, halott WeakReference-ekből álló collection-né váljon. Ehhez nyújt segítséget a referenciasor (ReferenceQueue). A ReferenceQueue osztály könnyűvé teszi ezeknek a halott referenciáknak a nyomon követését. Ha egy gyenge referenciának a konstruktorában megadunk egy referenciasort akkor miután az általa hivatkozott objektum elérhetetlenné válik, bekerül a sorba. Ezután bizonyos időközönként fel tudjuk dolgozni a ReferenceQueue-t és el tudunk végezni mindenféle tisztogatást, ami a halott referenciákhoz szükséges. Igazából a WeakHashMap is úgy működik, hogy a kulcs elérése előtt leellenőrzi a saját ReferenceQueue-jában, hogy nincs-e érvénytelen gyenge referencia, és ha van akkor eltávolítja azt.
A gyengeség fokai
Egészen eddig csak erős és gyenge referenciákkal foglalkoztunk, pedig a referencia erősségnek négy különféle fokát különböztetjük meg (sorban a legerősebbtől a leggyengébbig): erős, puha, gyenge és fantom. Nézzük a fennmaradt kettőt!
Puha referencia (soft reference)
Egy puha referencia ugyanolyan, mint egy gyenge, viszont kevésbé lelkesen dobja el a hivatkozott objektumot. Egy objektum, ami csak gyengén elérhető (a regerősebb rá hivatkozó referencia WeakReference) a következő szemétgyűjtésnél el lesz dobva, de egy objektum, ami puhán elérhető (softly reachable, vagyis SoftReference hivatkozik rá legerősebben) általában még velünk lehet egy darabig. A SoftReference-ek nem szükségképpen viselkednek máshogy, mint a WeakReference-ek, de a gyakorlatban a puhán elérhető objektumokat általában addig tartja meg a GC, amíg a memóriából bőségében vagyunk. Ezen tulajdonságuk miatt szokták ezeket gyorsítótárak építéséhez választani. Ilyen például a fent említett kép-cache, ahol így a szemétgyűjtőre tudjuk hagyni, hogy foglalkozzon vele, mennyire elérhetőek az objektumok. A get() metódus puha és a gyenge referencia esetében is null értéket ad vissza, ha az objektum be lett gyűjtve és már nem létezik.
Egyébként van egy parancssori kapcsoló is, amivel szabályozhatjuk a GC viselkedését a puha referenciákkal kapcsolatban: -XX:SoftRefLRUPolicyMSPerMB=N. Ez beállítja azt az N időtartamot (ezredmásodpercben), amíg egy puha referenciát a GC életben tart az utolsó rá való hivatkozás óta. Alapértelmezett értéke egy másodperc a heap szabad megabájtjainként. (Vagyis akkor pucolódik ki, ha életkora átlépte a SzabadMéretMBokban * SoftRefLRUPolicyMSPerMB értéket.) Ez a paraméter a JVM típusától függően kissé eltérően értelmezett:
A különbség miatt a kliens VM a heap méretének növelése helyett inkább a puha referenciák kidobását részesíti előnyben, míg a szerver VM inkább növeli a heap méretét (ha tudja) és csak utána dobálja ki a referenciákat (vagyis az általuk hivatkozott objektumokat). Ez utóbbi esetben a -Xmx paraméternek jelentős hatása van arra, milyen gyorsan szemétgyűjtőződnek a puha referenciák.
Bár kézenfekvő a puha referenciának gyorsítótárként való használata, azért érdemes ezt adott esetben átgondolni, mert nem árt, ha a cache elemeinek élettartamát nem bízzuk a véletlenre és nem hagyjuk, hogy a cache az elérhető memória határáig tudjon terjeszkedni. Célszerűbb valamilyen jól megválasztott gyorsítótárazási stratégiát választani.
Az erős referenciát használó példában egy java.lang.OutOfMemoryError: Java heap space kivételt kapunk. Azzal futásidőben már nem nagyon fogunk tudni mit kezdeni, a hajunkra kenhetjük. Ha viszont puha referenciát használunk, akkor még lesz lehetőségünk kezelni a helyzetet. Az alábbi példában a bigStore erős referenciát egy puha referencián keresztül érjük el.
import java.util.LinkedList; import java.util.List; import java.lang.ref.SoftReference; public class SoftTest { private byte[] getData() { return new byte[1024*1024]; } public void testSoftReferences() throws Exception { SoftReference<List<byte[]>> sRef = new SoftReference<List<byte[]>>(new LinkedList<byte[]>()); byte[] data; List<byte[]> bigStore; while(true){ data=getData(); bigStore=sRef.get(); if(bigStore==null){ return; // így jártál, nincs elég heap }else{ bigStore.add(data); } bigStore=null; } } public static void main(String[] args) throws Exception { new SoftTest().testSoftReferences(); } }
A puha referencia használatához két dolgot kellett átalakítani:
Így már nem jelentkezik OutOfMemoryError. A puha referencia megmondja, hogy mit lehet kidobni és csak azt kell nézni, hogy megkapjuk-e a listát. Ha nem, akkor esetleg megjeleníthetünk egy hibaüzenetet, hogy most épp nincs elég memória, próbáld máskor.
Fantom referenciák
A fantom referencia eltér az előzőektől. A saját objektumával annyira gyenge már a kapcsolata, hogy azt vissza se tudjuk szerezni: a get() metódus mindig null-t ad. A PhantomReference arra való, hogy a programunk értesítést kapjon arról, amikor egy objektumot a rendszer begyűjt. A fantom referencia konstruktorában kötelezően meg kell adni egy referencia sort. A különbség a WeakReference-hez képest az, hogy mikor történik meg a sorbaállítás. A WeakReference-ek sorba állítódnak, amint az objektum, amire mutatnak gyengén elérhető lesz. Ez még a finalize vagy szemétgyűjtés előtt van, elméletben ilyenkor az objektum még akár fel is éleszthető egy nem szokványos finalize() metódussal (bár ekkor a WeakReference már halott maradna). A PhantomReference-ek pont azelőtt kerülnek be a sorba, mielőtt az objektum fizikailag is kikerül a memóriából. A get() metódus azért ad vissza mindig null-t, hogy meggátolja, hogy véletlenül újra lehessen éleszteni egy majdnem halott objektumot.
Mire jó a fantom referencia? Egyrészt lehetővé teszi, hogy pontosan megfigyeljük, egy objektum mikor törlődik a memóriából. Sőt, valójában erre ez az egyetlen mód. Ez néhány nagyon specifikus esetben jöhet jól, mint például nagy képek manipulálásánál: ha biztosan tudjuk, hogy egy képet szemétgyűjtőzni kell, akkor meg tudjuk várni, míg az ténylegesen megtörténik, mielőtt megpróbálnánk betölteni a következő képet és így kevésbé valószínű, hogy OutOfMemory hibát kapunk. Másodszor pedig a PhantomReference használatával elkerülhető egy alapvető hiba a finalize() metódusnál: a finalize() metódusban ugyanis újra fel lehet támasztani az objektumokat azzal, hogy új erős referenciát hozunk létre rájuk. A PhantomReference használatával ez lehetetlen - amikor egy PhantomReference bekerül a sorba, már végképp nincs lehetőség rá, hogy mutatót kapjunk a már halott objektumra.
import java.lang.ref.PhantomReference; import java.lang.ref.Reference; import java.lang.ref.ReferenceQueue; import java.util.HashSet; import java.util.Set; public class PhantomTest { private byte[] getData() { return new byte[1024 * 1024]; } public void testPhantomReferences() { Set<PhantomReference<byte[]>> references = new HashSet<PhantomReference<byte[]>>(); ReferenceQueue<byte[]> queue = new ReferenceQueue<byte[]>(); Reference<? extends byte[]> tmp; for (int i = 0; i < 10000; i++) { PhantomReference<byte[]> pRef = new PhantomReference<byte[]>(getData(), queue); System.out.println(i + ". ref created: " + pRef); references.add(pRef); while ((tmp = queue.poll()) != null) { System.out.println("Ref collected: " + tmp); references.remove(tmp); } } } public static void main(String[] args) { new PhantomTest().testPhantomReferences(); } }
A rendkívül hosszúra nyúlt bevezetés után most már végre lássuk, miről is szól a GC! Először el kell oszlatni egy alapvető félreértést: sokan azt hiszik, a szemétgyűjtés összeszedi és megsemmisíti a szükségtelen objektumokat. Valójában ennek pont az ellenkezőjét teszi! A még élő objektumokat követi figyelemmel és minden mást szemétnek minősít. Ahogy majd látni fogjuk, ez az alapvető félreértés sok teljesítménybeli problémához tud vezetni.
A szemétgyűjtő az ún. heap memórián működik. A legtöbb esetben az operációs rendszer előre lefoglalja a heap-et, hogy majd a továbbiakban azt a JVM kezelje, míg a program fut. Ennek két fontos következménye van:
Minden objektum a heap területen jön létre. Minden, a fejlesztő által használt entitás itt kezelődik, beleértve az osztály objektumokat, statikus változókat és még magát a kódot is. A JVM élőnek tart egy objektumot, amíg van rá hivatkozás, vagyis az alkalmazás kódja által valamilyen objektum-láncolaton (úton) keresztül elérhető. Amikor egy objektumra már nincs többé hivatkozás, vagyis az alkalmazás kódja által nem elérhető, a szemétgyűjtő eltávolítja azt és újrahasznosítja a hozzá lefoglalt memóriát. Olyan egyszerű, ahogyan hangzik, de felmerül egy kérdés: mi az első referencia azon az úton, ahol elérhető az objektum?
Szemétgyűjtési gyökerek
Minden objektum objektumok fastruktúra-szerű szerkezetén át érhető el. Minden objektumfának lennie kell egy vagy több gyökérobjektumának. Amíg az alkalmazás eléri ezeket a gyökereket, az egész fa elérhető. De mikor tekinthetőek ezek a gyökérobjektumok elérhetőnek? A speciális, szemétgyűjtő-gyökérelemeknek nevezett adatszerkezetek (GC root) mindig elérhetőek és így minden olyan objektum is, aminek van szemétgyűjtő gyökéreleme a saját gyökerénél.

Java esetén négyféle GC gyökérelem van:
Egy egyszerű Java alkalmazásnak tehát a következő GC gyökérelemei vannak:
Szemét összeszedése és kisöprése
A szemétgyűjtést a fejlesztés megkönnyítése mellett arra tervezték, hogy megszüntesse a klasszikus memóriaszivárgás okát: a memóriában lévő elérhetetlen, de még nem törölt objektumokat. Viszont ez csak a memóriaszivárgás szokványos formájára érvényes. Simán lehetséges ugyanis, hogy vannak olyan nem használt objektumaink, amiket továbbra is elérhetne az alkalmazás, mert a fejlesztő elfelejtette ezeket elérhetetlenné tenni. Ezekkel pedig a szemétgyűjtő sem tud mit kezdeni. Sőt, az ilyen logikai memóriaszivárgásokat szoftverrel sem lehet felderíteni. Még a legjobb szoftverek is csak megjelölhetnek gyanús objektumokat. (Tegyük fel például, hogy egy dinamikus méretű listát tömbbel ábrázolunk. Mivel a tömb mérete fix, egy változó jelzi, hogy a tömb épp hány elemét használjuk ki. Ha töröljük az utolsó elemet, a működés szempontjából elegendő csak ennek a változónak az értékét csökkenteni. Ekkor azonban a tömb változón felüli eleme még megtartja a referenciát az adott objektumra, ezért a szemétgyűjtő nem tudja kidobni. Emiatt kell null-ra állítanunk a tömb megfelelő elemét.)

Ahhoz, hogy meghatározza, mely objektumok nincsenek használatban, a GC egy ún. megjelöl- és takarít (mark-and-sweep) algoritmust futtat. Ez egy egyszerű, kétlépéses folyamat:
Kiderült tehát, hogy a szemétgyűjtő teljesítményét valójában nem a halott, hanem az élő objektumok száma határozza meg. Minél több objektum hal meg, annál gyorsabb lesz a szemétgyűjtés. Ha a heap-en minden objektum kisöpörhető lenne, akkor a GC szinte azonnal lefutna. Ráadásul a szemétgyűjtőnek fel kell függesztenie a teljes alkalmazás futását, hogy az objektumfák integritását biztosítani tudja. Minél több élő objektumot talált, annál hosszabb ideig tart a felfüggesztés, aminek közvetett hatása van a válaszidőre és az áteresztőképességre. Ez a szemétgyűjtés alapvető tétele. Sok szálból álló alkalmazások esetén ez gyorsan skálázódási problémákhoz vezethet. A szemétgyűjtők működésével kapcsolatos alapvető fogalmak:
Az alábbi ábra egy Oracle GC tuningolás cikkből való és jól szemlélteti a GC leállások teljesítménybeli hatását a CPU-k növekedésének arányában.

Az ábra szemlélteti a GC megállások hatását a többszálú alkalmazások áteresztőképességére. Az adatok ideális rendszerre vonatkoznak, ami a GC kivételével tökéletesen skálázható. A piros vonal egy olyan alkalmazás, ami idejének csak 1%-át tölti a GC-vel egy egyprocesszoros rendszerben. Ha ezt az alkalmazást 32 processzoros rendszerre visszük át, akkor már 80% alá esik az áteresztőképesség. Ha a GC időt 10%-ra növeljük (ami azért nem a világ vége egy egyprocesszoros rendszerben), az 32 processzoros rendszerben már csak 20% áteresztőképességet eredményez. Ekkora hatása van annak, hogy egyszerre 32 végrehajtószálat felfüggesztünk!
A GC megállási idő csökkentésnek két általánosan használt módja van:
De mielőtt elmélyednénk a GC-stratégiákban és teljesítménynövelésekben, meg kell értenünk valamit a memóriatöredezettségről, ami szintén befolyásolja a megállási időt és az alkalmazás teljesítményét.
Új objektum létrehozásakor a JVM automatikusan lefoglal akkora memóriát a heap-en, ahová befér az új objektum. Az ismétlődő foglalás és felszabadítás viszont - minő rettenet - memóriatöredezettséghez vezet, ami hasonló a lemez töredezettségéhez és két problémát okoz:
A JVM ezen problémáknál nem az operációs rendszerre támaszkodik, hanem saját maga próbálja megoldani. Mégpedig az ún. compaction végrehajtásával egy sikeres GC végén (alábbi ábra). Ez a folyamat eléggé hasonlít egy merevlemez töredezettségmentesítéséhez.

Amikor a heap az ismétlődő foglalások és szemétgyűjtések következtében töredezetté válik, a GC végrehajt egy tömörítési lépést: egyszerűen elmozgatja az összes élő objektumot a heap egyik végére. Ez szépen összeilleszti az objektumokat és eltünteti a lyukakat. Innentől kezdve az objektumok újból teljes sebességgel foglalhatók le és a nagy objektumok létrehozásakor jelentkező probléma ki van küszöbölve. Ennek az egész bulinak persze még hosszabb GC időtartam a hátulütője és mivel a legtöbb JVM, köztük a HotSpot is felfüggeszti az alkalmazás végrehajtását a tömörítés időtartamára, a teljesítménybeli hatása jelentős lehet.
A legalapvetőbb szemétgyűjtési stratégia tehát a fentebb megismert három lépésből álló mark-sweep-compact:
A tömörítés negatív hatásának csökkentése
A modern szemétgyűjtők a tömörítési folyamatukat párhuzamosan hajtják végre, kihasználva ezzel több processzort. Viszont majdnem mind fel kell, hogy függessze az alkalmazás futtatását ezen folyamat során. A sok gigabájt memóriát használó JVM-ek akár több másodpercre megállíthatják a program futását. Ennek elkerülésére a JVM-ek bevezetnek paramétereket, amikkel meg lehet adni, hogy a memóriát kisebb, inkrementális lépésekben tömörítse egy nagy blokk helyett. Például:
Két általános módja van a szemétgyűjtéssel eltelt idő csökkentésének:
Ez a két logikai megoldás vezetett el a soros, párhuzamos és konkurens szemétgyűjtési stratégiák kifejlesztéséhez, amik az alapját jelentik minden Java szemétgyűjtő implementációnak. (A szemétgyűjtő mechanizmus megvalósítása egyébként nem a szabvány része, ezért különböző JVM-gyártók különbözőképpen implementálhatják azokat.) Fontos megjegyezni, hogy a párhuzamos fogalom nem ugyanaz, mint a konkurens. De ez az alábbi ábráról is leolvasható. A GC terminológiájában ez két teljesen különböző dolog: a párhuzamos magára a GC algoritmusra, a konkurens pedig a GC lefutására utal. (Megjegyzem, a cikkhez készült nyersanyagok fordítása közben eleinte én is szinonímaként használtam ezeket a szavakat, míg rá nem jöttem, hogy nem ugyanarról van szó.)

A különböző szemétgyűjtési algoritmusok közötti különbségek akkor lesznek a legtisztábbak, amikor a szemétgyűjtési megállásokat hasonlítjuk össze. A soros gyűjtő (serial collector) felfüggeszti az alkalmazást és a mark-sweep algoritmust egyetlen szálon futtatja. Ez a szemétgyűjtés legegyszerűbb és legrégibb formája. A párhuzamos gyűjtő (parallel collector) több szálat használ a munka elvégzéséhez, így több mag esetén csökkenhet a megállás ideje. A konkurens gyűjtő (concurrent collector) a munka nagy részét az alkalmazás futásával párhuzamosan (de ezután ezt már így hívjuk: konkurensen) végzi el és csak nagyon rövid időre kell felfüggesztenie annak a futását. Ez nagy előnyt jelent a válaszidőre, de a megoldás persze nem hátrányok nélküli.
A szemétgyűjtés teljes kiiktatása nélkül csak egy biztos módja van a szemétgyűjtés gyorsításának: biztosítani kell, hogy ennek során a lehető legkevesebb objektum legyen elérhető. Minél kevesebb az élő objektum, annál kevesebbet kell megjelölni. Ez a megfontolás állt a generációs heap bevezetése mögött.
A generációs szemétgyűjtő előnye arra a megfigyelésre alapul, hogy a legtöbb program nagyon rövid életű objektumokat használ (legtöbbjüket átmeneti adattárolásra). Azzal, hogy elkülöníti az újonnan létrehozott objektumokat egyfajta objektum-bölcsödébe (angol terminológiában nursery), a generációs szemétgyűjtő több dolgot elér. Egyrészt mivel az új objektumok létrehozása itt folyamatosan, egyfajta verem-szerű módon történik, a memóriafoglalás rendkívül gyors lehet, mert egyszerűen csak annyiból áll, hogy egy mutatót meg kell növelni és egy ellenőrzést kell végezni arra vonatkozóan, hogy betelt-e a bölcsöde. Másodszor pedig amikor a bölcsöde túlcsordulása megtörtént, az ott lévő objektumok legtöbbje már eldobható, mert semmi nem használja. Ez pedig lehetővé teszi a szemétgyűjtőnek, hogy azt a néhány objektumot, ami megmaradt, átmozgassa máshová, a nem használt objektumoknál pedig semmiféle helyreállítási munkára nincs szükség.
A JVM a heap területet két nagy részre osztja: egy young és egy old generációra, amelyeket különböző stratégiával lehet szemétgyűjtőzni.
Az objektumokat a JVM általában a young területen hozza létre. Amikor az objektum már túlélt néhány GC ciklust, akkor átkerül az old generációba. (Néhány nagyon nagy objektum esetén lehet kivétel, de ezt majd később látni fogjuk.) Miután az alkalmazás befejezte a kezdeti indulási fázist (sok alkalmazás az indítás során foglal le gyorsítótárakat és egyéb állandóan használatos objektumokat), a legtöbb lefoglalt objektum nem éli túl első vagy második GC ciklusát. Az élő objektumok mennyisége, amiket minden egyes ciklusban figyelembe kell venni, stabil és relatív kis mennyiségű lehet.
Az old generációban történő foglalások esetén az a jó, ha ritkák maradnak. Egy ideális világban ilyenek egyáltalán nem is történnek meg a kezdeti indítási fázis után. Ha az old generáció nem növekszik (nem nő túl a szabad területén), akkor ott egyáltalán nincs is szükség szemétgyűjtésre. Lesznek használatlan objektumok az old generációban, de amíg a memóriára nincs szükség, nincs ok arra, hogy újrahasznosítsuk az általuk foglalt területet.
Ahhoz, hogy ez a generációs megközelítés működjön, a young generációnak elég nagynak kell lenni, hogy biztosítsa, hogy minden átmeneti objektum be is fejezi ott az életét. Mivel a legtöbb alkalmazásban az átmeneti objektumok száma az alkalmazás terheltségétől függ, a young generáció optimális mérete terhelésfüggő. A young generáció méretezése (generation-sizing) ezért az egyik legfontosabb teendő a csúcsteljesítmény eléréséhez. Sajnos néha nem lehetséges optimális állapotot elérni, hogy az összes objektum a young generációban múljon ki. Az old generációnak ezért gyakran konkurens szemétgyűjtésre van szüksége. A konkurens szemétgyűjtő egy minimálisan növekvő old generációval együtt biztosítja, hogy az elkerülhetetlen teljes megállási események nagyon rövid ideig tartanak és megjósolhatóak lesznek. (A teljes megállási esemény - stop-the-world event - nagyon fontos fogalom, érdemes megjegyezni. A konkurens szemétgyűjtési fázisokon kívül minden más GC ilyen stop the world event alatt fut. Ilyenkor a JVM teljes egészében felfüggeszti az alkalmazás futását: a GC-hez szükséges szálakon kívül minden más megáll. A teljes megállási esemény is egy safe point-ban következik be.)
Viszont ha sok új objektum keletkezik a young generációban a GC ciklusok kezdetén, és a GC ciklusokat az objektumok csak egy kis része éli túl, az a szokványos GC stratégiákkal nagyfokú töredezettséghez vezet. Szabad listák használata jó opció lenne, ha nem lassítaná le az új objektumokhoz szükséges memóriafoglalásokat. Azt is megtehetnénk, hogy teljes tömörítést végzünk minden egyes alkalommal, de ennek meg rossz hatása van a megállási időre. A legtöbb JVM ezek helyett egy copy collection-nek nevezett stratégiát implementál a young generációban.
Amikor a másolás gyorsabb, mint a megjelölés
A mark-copy elvet alkalmazó szemétgyűjtő felosztja a heap-et két (vagy több) területre amelyek közül csak egyet használ új objektumok létrehozására. Amikor ez a terület betelik, minden élő objektumot átmásol a második területre, aztán az első területet egyszerűen üresnek nyilvánítja.

Ahelyett, hogy kisöpörné a szemetet és tömörítené a heap-et, a mark-copy egyszerűen átmásolja az élő objektumokat valahová máshová, a régi területet pedig üresnek jelöli.
Itt nincs töredezettség és ezért nincs szükség üres listára és tömörítésre sem. A foglalás mindig gyors, a GC algoritmus pedig egyszerű. Ez a stratégia viszont csak akkor hatékony, ha a legtöbb objektum a szemétgyűjtésig bevégzi az életét. Ha a young generáció túl kicsi, az objektumok idő előtt az old generációba kerülnek. Ha a young generáció túl nagy, akkor túl sok objektum marad élő és a GC ciklus túl sokáig fog tartani. A közhiedelemmel ellentétben ezek a young-generációs GC-k, amiket gyakran minor-GC-nek hívnak, tele vannak teljes leállási eseménnyel. Ezeknek még súlyosabb negatív hatása lehet a válaszidőre, mint az alkalmankénti old-generációs GC-nek.
A generációs heap tehát nem ad minden szemétgyűjtési problémára megoldást. Az optimális konfiguráció sokszor egy kompromisszum egy megfelelően méretezett young generációval a hoszú minor GC-k elkerülésée és egy konkurens GC-vel az old generációban, hogy kezelni tudják a túl korán oda került objektumokat.
Az Oracle HotSpot kizárólag generációs heap-et használ, azonban a JRockit nemgenerációs heap-et is támogatott, az IBM szerint pedig a generációs heap kis memóriánál úri huncutság, a WebSphere alapértelmezetten nemgenerációs heap-et használ és azt ajánlják, hogy 100 MB-nál kisebb heap esetén mindig nemgenerációs heap-et használjunk. Egy generációs GC és a hozzá kapcsolódó copy collection-nek van némi plusz erőforrásigénye CPU és memória terén, ezért ez reális meglátásnak tűnik.
Ha egy alkalmazást áteresztőképességre optimalizáltak és az átmeneti objektumok száma kicsi, akkor egy nemgenerációs GC-nek is megvan a maga előnye. Egy teljes párhuzamos GC jobb kompromisszum CPU használatban, ha nem érdekel minket egyetlen tranzakció válaszideje. Másrészről ha az átmeneti objektumok száma relatív kicsi, egy konkurens GC egy nemgenerációs heap-en is megcsinálja a munkát kevesebb megállási idővel, mint egy generációs GC. De persze pontos választ mindig csak átfogó teljesítményteszt tud adni.
A foglalási teljesítmény növelése
A foglalási sebességre (új objektumok létrehozása) két dolognak van negatív hatása: a töredezettség és a konkurencia. A töredezettségről már volt szó, a konkurencia problémája pedig ott kezdődik, hogy a JVM-ben minden szál megosztottan használja a memóriát és minden memóriafoglalást szinkronizálni kell. Amikor sok szál próbál meg párhuzamosan foglalni, a helyzet gyorsan eldurvulhat. A megoldás a thread-local foglalás.
Ebben az esetben mindegyik szál kap egy kicsi, de kizárólagos memóriadarabot, ahol szinkronizálás nélkül tudnak objektumokat foglalni. Ez növeli a párhuzamosságot és az alkalmazásvégrehajtási sebességet. (Ez nem keverendő össze a thread-local változóknak szánt heap területtel!) Egy egyszerű thread-local heap (TLH) még akkor is kicsi lehet, amikor már sok szálhoz tartozik. A TLH nem egy speciális heap terület, hanem általában a young generáció része, ami persze okozhat problémákat. Egy generációs heap-nek TLH-val nagyobb young generációra van szüksége, mint TLH nélkül. Ugyanolyan számú objektum egyszerűen több helyet foglal. Másrészről egy nemgenerációs heap aktív TLH-val valószínűleg sokkal töredezettebbé válik és sokkal gyakoribb tömörítést igényel.
Az Oracle Java 7 heap területének felosztása az alábbi módon néz ki. Mindegyik területhez megadom az annak méretét vezérlő paramétert is.

Young generation: minden új objektum itt kezdi az életét. Angol terminológiában "nursery", vagyis bölcsöde néven is emlegetik. Ha ez a terület betelik, egy ún. minor GC indul el. Egy elérhetetlen objektumokkal teli young generation-t nagyon gyorsan GC-zni lehet a már fentebb leírt elvek miatt. A néhány túlélő objektum pedig folyamatosan öregszik, ahogy egyre több GC-t túlél és ezeket végül az old generation-be lehet mozgatni.
Old generation: a hosszú ideig túlélő objektumok tárolási helye. Általában egy küszöbérték van beállítva a young generáció objektumainak és amikor ezt az életkort elérik, átkerülnek az old generation-be. Persze végül az old generation-t is szemétgyűjtőzni kell, ezt nevezik major GC-nek. Ez egy teljes megállási esemény. A major GC gyakran sokkal lassabb, mert az összes élő objektumon végigmegy, ezért a reszponzív alkalmazások esetén ezek előfordulását érdemes minél inkább lecsökkenteni. A teljes megállási esemény időtartama attól is függ, milyen szemétgyűjtési stratégiát választottunk az old generation-höz.
Permanent Generation: a JVM által igényelt metaadatokat tartalmazza, amelyek leírják az alkalmazás által használt osztályokat és metódusokat. Ezt a JVM tölti fel futásidőben. A Java SE osztálykönyvtárak is itt foglalnak helyet. A permanent generation arra rendeltetett, hogy hatékonyabbá tegye a szemétgyűjtési folyamatot. A futás legnagyobb részében ezek az objektumok állandóan bent kell, hogy legyenek (permanent) a memóriában és nem kell hozzájuk szemétgyűjtés. A HotSpot képes azáltal növelni a szemétgyűjtés teljesítményét, hogy az osztály objektumokat és konstansokat a permanent generációra teszi, így figyelmen kívül lehet hagyni ezeket a szokványos GC ciklusokban. Az alkalmazásszerverek, OSGi konténerek és dinamikusasn generált kód elterjedésével viszont megváltoztak a játékszabályok és a valaha állandónak tekintett objektumok már egyáltalán nem olyan állandóak. A permanent generation nem ezek figyelembe vételével lett megtervezve. A mai alkalmazásszerverek nagy mennyiségű osztályt, gyakran 100000-nél is többet tudnak betölteni, ami nagyon gyosan ki tud akasztani bármilyen konfigurációt. Az osztályokat mindenesetre ki lehet innen dobálni, ha a JVM úgy találja, hogy többé már nincs szükség rájuk, az általuk elfoglalt helyre viszont igen. A teljes GC ezért a permanent generation-t is magába foglalja. (Java 7 előtt a HotSpot-nál az interned sztringek is itt tárolódtak, azonban a 7-es Java-ban azok már átkerültek a young és old generációba.)
Virtuális területek: a JVM memóriaméretének konfigurálásakor minden fő területre be lehet állítani kezdeti értéket (ennyi memóriát foglal le induláskor a JVM) és maximális értéket (ennyi memóriát foglal le legfeljebb a JVM). A kettő közötti különbség a virtuális, vagyis a pillanatnyilag kihasználatlan terület.
A sztring internalizálás biztosítja, hogy a különböző sztring literálokból és sztring értékű konstansokból mindig csak egy példány tárolódjon a memóriában. Tehát ha van egy listánk, amiben a "kisvakond" ezerszer szerepel, az internalizálással ez a sztring valójában csak egyszer fog a memóriában tárolódni. A String osztálynak van egy publikus intern() metódusa, ami visszaadja a sztring objektum kanonikus reprezentációját. A String osztály belsőleg tartalmaz egy sztring pool-t, amiben a sztring literálok automatikusan internalizálódnak. Az intern() metódus megnézi, hogy az a sztring benne van-e a pool-ban. Ha igen, akkor visszaadja annak a referenciáját, egyébként pedig hozzáadja az új sztringet, majd visszaadja az új referenciát.
Az intern() metódus segít két sztring objektum összehasonlításában az == operátorral úgy, hogy a már létező sztring literálok pool-ját használja. Ez pedig gyorsabb, mint az equals() metódus. A pool tehát egyrészt tárhely-megtakarítást, másrészt pedig teljesítménybeli javulást jelent. (A Java programozóknak általában azt tanácsolják, hogy az equals() metódust használják == helyett két sztring azonosságának vizsgálatára, hiszen az == referenciákat, az equals() pedig a tartalmat vizsgálja.)
A Java minden sztringet alapértelmezetten internalizál, tehát expliciten csak akkor kell használni az intern() metódust, amikor nem konstansról van szó. Íme egy példa:
package hu.egalizer.gctest; public class InternTest { public static void main(String[] args) { String s1 = "Test"; String s2 = "Test"; String s3 = new String("Test"); String s4 = s3.intern(); System.out.println(s1 == s2); System.out.println(s2 == s3); System.out.println(s3 == s4); System.out.println(s1 == s3); System.out.println(s1 == s4); System.out.println(s1.equals(s2)); System.out.println(s2.equals(s3)); System.out.println(s3.equals(s4)); System.out.println(s1.equals(s4)); System.out.println(s1.equals(s3)); } }
A program kimenete:
true false false false true true true true true true
A fentiekben már szó esett a különböző területeken lefutó szemétgyűjtőkről, ezek összefoglalva:
A munka mennyiségéből adódóan a full GC tart a legtovább, hiszen a teljes heap-et szemétgyűjtőzi, ráadásul ezt egy teljes megállási esemény alatt csinálja, vagyis az alkalmazás elég hosszú ideig felfüggesztésre kerül, ami akár több másodperc, sőt extrém esetben perc is lehet.
A heap méretének beállítására a következő JVM paraméterek alkalmasak (az X-szel kezdődő JVM paraméterek egyébként nem szabványosnak számítanak és nem is minden VM esetén támogatottak, de a HotSpot-ban azért bízvást építhetünk rájuk. A paraméterekről bővebben itt lehet olvasni):
Metafizika
A Java 8 HotSpot virtuális gépének fejlesztésekor az egyik fő szempont az volt, hogy a permanens generációt megszüntessék. Ez a terület alkalmazásszerverek esetén a folyamatos alkalmazás-újradeployolások során hajlandó volt betelni (részben a rosszul megírt osztálybetöltők miatt), és java.lang.OutOfMemoryError: PermGen space kivétellel megörvendeztetni a fejlesztőt. Optimális méretét pedig nehéz volt előre meghatározni, valamint a hírek szerint néhány GC-t érintő fejlesztést sem lehetett volna a permanens generációval megcsinálni.
Az osztályok metaadatai a Java 8-tólkezdődően ezért immár nem a heap-en, hanem a natív memóriában helyezkednek el egy metaspace nevű területen. A heap-ről eltűntek az osztály metaadatokat definiáló adatszerkezetek is (klassKlass). A metaspace mérete alapesetben nem konfigurált, vagyis dinamikusan, az igényeknek megfelelően képes nőni. Az osztály metaadatok mennyiségét tehát immár csak a memória mérete korlátozza, bár adott esetben természetesen a metaspace méretét is lehet korlátozni. Egyes adatok a megszűnt permanens generációból a heap-re kerültek, így néhány alkalmazás esetén nagyobb heap-pel kell számolni Java 8 esetén a 7-hez képest. A metaspace is GC-zett terület: a betelése váltja ki a GC-t. A heap egyébként a young és old generációk tekintetében változatlan maradt a Java 7-hez képest.
Jól hangzik a permgen kivezetése, de azért vegyük észre, hogy az osztálybetöltő memóriaszivárgását a metaspace sem oldotta meg, sőt az alapértelmezetten nem korlátozott mérete miatt a hatását kitolta, vagyis még nehezebb észrevenni. Amikor nagyon intenzív metaspace GC-zést tapasztalunk, akkor sejthető, hogy ilyen hiba áll a háttérben.
Java 8-cal a paraméterek közül a permanent generáció méretezése kikerült, de bejött a metaspace opcionális méretezése. (A Java 8 paraméterekről bővebben itt lehet olvasni)
Metafizikai telítettség
Hogy a metaspace is milyen gyönyörűen be tud telni, annak pedig az alábbiakban állítok bizonyítékot. (A példát ezen az oldalon található mintából írtam át.) Jó persze a példa itt speciálisan konstruált, hogy lássuk a lényeget, de valódi alkalmazások is tudnak hasonlóan viselkedni.
A példához már tudjuk, hogy a Java-ban minden objektum hivatkozik a saját osztályára, emellett pedig azt is tudni kell, hogy minden osztály hivatkozik a saját osztálybetöltőjére (classloader), ami szintén egy osztály. Mivel az osztálydefiníciók a permanens generációban vagy a metaspace-en helyezkednek el, valahogyan el kell érni, hogy elég sok osztálydefiníciónk legyen.
Ehhez a Java dinamikus proxy nevű komponensét fogjuk felhasználni.
A Java reflection keretrendszernek van egy olyan lehetősége, amivel futásidőben dinamikusan lehet interfészeket implementálni. Ezt dinamikus proxynak hívják és a java.lang.reflect.Proxy osztály segíti benne az egyszeri programozót.
Proxy-k létrehozása
Dinamikus proxykat a Proxy.newProxyInstance() metódussal lehet varázsolni. Ez három paramétert vár:
Íme egy példa:
InterfaceA tmp = (InterfaceA) Proxy.newProxyInstance(classLoader,
new Class<?>[] { InterfaceA.class },
new InterfaceAInvocationHandler(new InterfaceAImpl()));
(Az InvocationHandler-nek nem kötelező implementációt átadni, de a példánkban használni fogjuk.)
Miután a kód lefut, a tmp változóban ott lesz az InterfaceA dinamikus implementációjának referenciája. Metódushívások pedig továbbítódnak a new InterfaceAInvocationHandler() példánynak, ami az InvocationHandler egy implementációja. Ez az interfész a következőképp néz ki:
public interface InvocationHandler{ Object invoke(Object proxy, Method method, Object[] args) throws Throwable; }
Az implementációban az invoke metódus csinálja a dinamikus megvalósítást. Az átadott proxy paraméter az interfészt megvalósító dinamikus proxy objektum, de erre a megvalósításnak nem feltétlenül van szüksége. A method paraméterben van az, hogy a proxy-n milyen metódus hívódott meg, az Object[] tömb pedig tartalmazza az átadott paramétereket, amikor a metódust meghívták.
A dinamikus proxykat többféle célra használják:
A teszthez az alábbi osztályokra lesz szükség. Elsőként van egy interfészünk:
package hu.egalizer.gctest; public interface InterfaceA { void method(String input); }
Aztán egy ezt megvalósító osztályunk:
package hu.egalizer.gctest; public class InterfaceAImpl implements InterfaceA { public void method(String name) { System.out.println(name); } }
Az InvocationHandler implementációnk:
package hu.egalizer.gctest; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; public class InterfaceAInvocationHandler implements InvocationHandler { private Object classAImpl;// ez akkor kell, ha meg akarjuk hívni rajta a metódust public InterfaceAInvocationHandler(Object impl) { this.classAImpl = impl; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { String name = method.getName(); if (Class.class == method.getDeclaringClass()) { // Object-hez tartozó funkciók dinamikus megvalósítása if ("equals".equals(name)) { return proxy == args[0]; } else if ("hashCode".equals(name)) { return System.identityHashCode(proxy); } else if ("toString".equals(name)) { return proxy.getClass().getName() + "@" + Integer.toHexString(System.identityHashCode(proxy)) + ", with InvocationHandler " + this; } else { throw new IllegalStateException(String.valueOf(method)); } } else if (InterfaceA.class == method.getDeclaringClass()) { // InterfaceA-hoz tartozó funkciók dinamikus megvalósítása if ("method".equals(name)) { System.out.println("Given: " + args[0]); } } // Meghívjuk a metódust, mert az jó return method.invoke(classAImpl, args); } }
A memóriaszivárgást pedig így csináljuk:
package hu.egalizer.gctest; import java.io.IOException; import java.lang.reflect.Proxy; import java.net.URL; import java.net.URLClassLoader; import java.util.HashMap; import java.util.Map; public class ClassMetadataLeakSimulator { // ebbe tesszük a hivatkozásokat a class metaadatokra private static Map<String, InterfaceA> classMap = new HashMap<String, InterfaceA>(); // ennyi osztálybetöltőt próbálunk létrehozni private final static int ITERATIONS = 50000; public static void main(String[] args) { System.out.println("Class metadata leak simulator. Press Enter to start the magic!"); try { System.in.read(); } catch (IOException e) { } try { for (int i = 0; i < ITERATIONS; i++) { String leakClassloaderJAR = "file:" + i + ".jar"; URL[] leakClassloaderURL = new URL[] { new URL(leakClassloaderJAR) }; // Létrehozunk egy új ClassLoader példányt: URLClassLoader classLoader = new URLClassLoader(leakClassloaderURL); // Létrehozunk egy új proxy példányt: InterfaceA tmp = (InterfaceA) Proxy.newProxyInstance(classLoader, new Class<?>[] { InterfaceA.class }, new InterfaceAInvocationHandler new InterfaceAImpl())); // Hozzáadjuk a proxy példányt a szivárogtató hashmap-ünkhöz classMap.put(leakClassloaderJAR, tmp); } } catch (Throwable ex) { System.out.println("ERROR: " + ex); } System.out.println("Done!"); } }
A példában folyamatosan új osztálybetöltő osztálydefiníciókat hozunk létre, ezzel próbára téve a metaspace (permgen) tűrőképességét. Az URLClassLoader osztály eredetileg URL-ekről történő osztálybetöltőként működik, bár helyi fájlokból is képes a munkát elvégezni. Itt nem használjuk ki ezt a lehetőségét, csupán azért van rá szükség, hogy új osztálydefinícióként jelenjenek meg a metaspace-en. A program megpróbál adott számú új URLClassLoader osztálydefiníciót létrehozni, hacsak közben el nem fogy a rendelkezésre álló memória. Mivel az osztály hivatkozik a betöltő osztályára, a hashmap-be gyűjtött proxy példányokon keresztül ezek mind elérhetőek maradnak, így a GC nem tudja őket kipucolni.
A program futásának eredménye:
1.7-es Java esetén 128 MB permgen területtel a következő paraméterekkel:
-XX:MaxPermSize=128m -XX:+HeapDumpOnOutOfMemoryError -Xmx512M -Xloggc:gclog.log -XX:+PrintGCDetails
 Amint látható a VisualVM diagnosztikai eszköz ábráján, a permgen terület szépen lassan betelt. A
tulajdonképpeni méretet előbb megpróbálta növelni (vagyis a virtuális területet csökkenteni), de hamar elérte a maximumot. Ezután pedig némi, többnyire sikertelen GC-zést követően (ami
akkor már szinte a teljes processzoridőt elfoglalta) kaptunk egy java.lang.OutOfMemoryError-t. A heap dump elemzéséből kiderült, hogy a permanent
generation 34071 URLClassLoader osztályt volt képes befogadni, mielőtt megadta magát.
Amint látható a VisualVM diagnosztikai eszköz ábráján, a permgen terület szépen lassan betelt. A
tulajdonképpeni méretet előbb megpróbálta növelni (vagyis a virtuális területet csökkenteni), de hamar elérte a maximumot. Ezután pedig némi, többnyire sikertelen GC-zést követően (ami
akkor már szinte a teljes processzoridőt elfoglalta) kaptunk egy java.lang.OutOfMemoryError-t. A heap dump elemzéséből kiderült, hogy a permanent
generation 34071 URLClassLoader osztályt volt képes befogadni, mielőtt megadta magát.
1.8-as Java esetén alapértelmezett (korlátlan) metaspace területtel a következő paraméterekkel:
-XX:+HeapDumpOnOutOfMemoryError -Xmx512M -Xloggc:gclog.log -XX:+PrintGCDetails
A GC logokból és az ábrából is látható, hogy a metaspace terület dinamikusan növekedett az igényeknek megfelelően 15,5 MB-ról 302 MB-ig, a program pedig le tudott futni, mert simán volt ennyi szabad memória.

1.8-as Java esetén 128 MB metaspace területtel a következő paraméterekkel:
-XX:MaxMetaspaceSize=128M -XX:+HeapDumpOnOutOfMemoryError -Xmx512M -Xloggc:gclog.log -XX:+PrintGCDetails
Ez a megoldás egy java.lang.OutOfMemoryError: Metaspace hibaüzenettel örvendeztet meg minket. A dump alapján 20300 URLClassLoader osztálydefiníció után adta meg magát. A GC logból és a diagramról is látszik, hogy a hibát már akkor megkaptuk, amikor a JVM nem tudta tovább növelni a fenntartott metaspace területet, ehhez nem kellett, hogy a teljes beteljen, mint a permgen területnél.

Most, hogy megismertük a heap felosztását, lássuk végre, hogyan működik az objektumfoglalás és öregedés egy GC során.
1. minden új objektum az éden területen jön létre. Mindkét survivor terület üresen indul.

2. amikor az éden terület betelik, kiváltódik egy minor GC (valójában majd akkor, amikor a következő objektum foglalását már nem lehet elvégezni)

3. A hivatkozott objektumok átkerülnek a nulladik survivor területre. A nem hivatkozott objektumok törlődnek, amikor az éden területet kiüríti a GC. Egy objektum másolása természetesen sokkal költségesebb, mint egyszerű megjelölése, ezért az éden a legnagyobb a három young generációs területből. Az objektumok többsége még fiatalkorában kimúlik. Nagy éden biztosítja, hogy ezek az objektumok nem fogják túlélni az első GC ciklust és így egyáltalán nem kell majd őket másolgatni.

4. a következő minor GC újra elindul az éden területen. A nem hivatkozott objektumok törlődnek, a hivatkozott objektumok átkerülnek egy survivor területre, ebben az esetben viszont az elsőre (S1). Az utolsó minor GC-nél S0-ra átkerült objektumok is átkerülnek az S1-re, eközben az életkor információjuk inkrementálódik. Amikor minden túlélő objektum átkerült az S1-re, az S0 és az éden is törlődik. Figyeljük meg, hogy most már különböző életkorú objektumaink vannak a survivor területen.

5. a következő minor GC-nél ugyanez a folyamat ismétlődik a survivor területek felcserélésével. A hivatkozott objektumok az S0 területre kerülnek és egyet megint idősödnek. Az éden és az S1 kiürül.

6. eljött a továbblépés (promotion) ideje. Egy minor GC után, amikor egy bizonyos életkort (aging threshold) elértek az objektumok (a példában ez 8, de konfigurálható), átkerülnek az old generációba. (Erre tenured területként is szoktak hivatkozni.)

7. ahogy a minor GC-k folyamatosan bekövetkeznek, objektumok folyamatosan kerülnek át az old generációba. Persze simán lehetséges, hogy egyes objektumok túl korán átkerülnek ide. A területek mérete és aránya nagy befolyással van a foglalási sebességre, GC hatékonyságra és gyakoriságára és teljesen az alkalmazás viselkedésétől függ. Az ideális megoldást csak megfelelő architektúrális ismeretekkel és sok teszteléssel lehet megtalálni.

8. Végül egy major GC lefut az old generáción, ami kiüríti és tömöríti azt a területet
Ezt az egész működést remekül lehet szemléltetni egy, az egyébként minden JDK-ban megtalálható Java VisualVM nevű eszközzel. Ez a jvisualvm.exe fájllal indítható, azonban ma már saját github projektje is van. A Visual VM-hez tartozik egy Visual GC nevű plugin, amivel szépen grafikus felületen követhetjük a GC és a heap állapotát. A JDK demók között található Java 2D nevű programot monitorozva kaptam az alábbi diagramot a Visual GC-ben:

Ez az ábra szerintem az eddigiek alapján sok magyarázatot már nem igényel. A Histogram nevű diagram százalékosan mutatja, hogy a young generáció objektumai hány szemétgyűjtést éltek túl (a Histogram-hoz a tesztprogram JVM-jét -XX:+UseParNewGC paraméterrel kell indítani). A tenuring threshold azt jelenti, hogy 15 szemétgyűjtés után kerül egy objektum az old generation-be. A Spaces diagramon a háttér világosabb és sötétebb szürke négyzetekkel van behálózva. A sötétszürke a ténylegesen lefoglalt (utilized, commited) memóriát, míg a világosabb szürke a JVM által lefoglalható, de még nem lefoglalt (uncommited) memóriát jelzi. A konkrét értékek látszanak a Graphs részben is a következő formátumban: (maximális, lefoglalt): használt.
Látszik, hogy az édenben lévő objektumok összmérete folyamatosan nő, míg le nem fut egy szemétgyűjtés (zöld tüske), ekkor az éden kiürül. Ezzel egy időben azt is látjuk, hogy a túlélő objektumok az egyik survivorből átkerülnek a másikba. Ha az egyik survivor betelne, az ide kerülendő objektumok automatikusan az old generationbe kerülnek átmásolásra. Ezt a hibajelenséget premature promotionnek nevezik. Amikor emiatt betelik az old generation is, és le kell futtatni a GC-t azt promotion failure-nek hívják. Ha elfogy a memória, OutOfMemoryError-t kapunk. Ezt azonban a JVM már csak akkor dobja, ha a GC lefutott és ezután sincs szabad memória.
Eddig még nem említettem az alábbi két furfangos ötletet, amik közül az első a GC, a második a memóriafoglalás gyorsítására használatos.
Kártyajáték
Ha nem szeretnénk bejárni az egész heap-et a használt objektumok meghatározásához, akkor a GC-nek tudnia kell, hogy a heap nem átvizsgált területén szerepel-e referencia átvizsgált területen lévő objektumokra. A generációs szemétgyűjtés esetén tipikus példa, hogy az old generáció átvizsgálása nélkül szeretnénk szemétgyűjtőzni a young generációt. Az ezt lehetővé tévő adatszerkezetet card table-nek hívják. Ez gyakorlatilag egy bájttömb, amiben minden bájtot egy kártyának (card) hívnak. Egy kártya a heap egy bizonyos címtartományának felel meg. A HotSpot-ban ennek a címtartománynak a mérete 512 bájt, ezt hívják kártyalapnak (card page). Amikor egy old generációban lévő objektum valamely referencia mezőjét valami beállítja, akkor egy ún. write barrier kód (általában egy shift and store utasítás) beállítja piszkosnak (dirty) az ahhoz a címtartományhoz tartozó kártyát. Minor GC-k esetén a mark fázisban ezért csak azokat az old generációs területeket kell átvizsgálni, amelyek esetén piszkos a hozzájuk tartozó kártya. Az itt lévő objektumok szolgálhatnak további GC root-ként a young területhez.
TLAB
A HotSpot egy speciális technikát is alkalmaz a memóriafoglalások gyorsítására. Ennek az ismertetését azért nem korábban tárgyaltam, mert most a szemétgyűjtés alapjainak ismeretében már jobban látható az előnye. Az objektumok nem csak úgy találomra kerülnek a memóriába létrehozáskor, hanem egy ún. pointer bump allocation nevű módszer segít ebben. Ez gyakorlatilag egy mutatót jelent, ami megmondja, hogy hová lehet tenni a következő objektumot a memóriában. A HotSpot ezt mindig ide teszi, majd növeli a mutató értékét. Ha például a mutatónk értéke 16, és létre akarunk hozni egy 32 bájtos objektumot, akkor ez a módszer visszaadja a 16-ot referenciaként, ott kezdődhet az új objektum, a mutatót pedig 48-ra állítja. Új objektum létrehozásakor csak annyit kell vizsgálni, hogy az éden terület tetejéig van-e még elég hely. Ha igen, létrehozzuk, ha nem, akkor lefut a minor GC, ami mindig kiüríti az éden területet, tehát probléma nélkül kezdődhet újra a lefoglalás szépen sorban. Ez nagyon gyors objektumlétrehozást tesz lehetővé.
Többszálú programoknál azonban eléggé hamar probléma jelentkezhet, hiszen a mutatót szinkronizálni kellene a szálak között, ami jelentős teljesítménybeli visszaesést jelentene. Ezért a JVM egy ún. Thread-Local Allocation Buffer (TLAB) nevű technikát alkalmaz. Ez azt jelenti, hogy minden szál megkap egy kis saját memóriaterületet az édenben, ahol már pointer bump allocation módszerrel foglalhatja magának az objektumok tárterületét mindenféle lockolástól mentesen. Csak akkor kell szálbiztos módon dolgozni, amikor a kiosztott TLAB betelik és újat kér a szál. Ennek a technikának köszönhetően a HotSpot-ban egy new Object() művelet az idő legnagyobb részében mindössze 10 gépi utasítást igényel. (A TLAB-ot ki lehet kapcsolni a -XX:-UseTLAB kapcsolóval, de ezután megnézhetjük a többszálú programunk teljesítményét. Igazi feketeövesek viszont a -XX:TLABSize=N paraméterrel saját maguk is beállíthatják a TLAB méretét. )
Így már látjuk, hogy a generációs heap hogy segíti a gyors memóriafoglalást, bár azon az áron, hogy az élő objektumokat a GC-nek mozgatnia kell. Ha nem kellene mozgatnia, akkor viszont a memóriafoglalás lenne lassabb. Sajnos nincs ingyenebéd.
Azon elvetemültek számára, akiket érdekel az assembly programozás, picit bővebben is kivesézem a card marking, vagyis kártya megjelölés folyamatát. Az alábbi kódrészletek szerint működik az 1.6-7-8-as JVM. Ez a kód egy teljesen szokványos setFoo(Object bar) metódusnak felel meg.
; rsi a 'this' cím
; rdx a paraméter, referencia a bar-hoz
; JDK6:
mov QWORD PTR [rsi+0x20],rdx ; this.foo = bar
mov r10,rsi ; r10 = rsi = this
shr r10,0x9 ; r10 = r10 >> 9;
mov r11,0x7ebdfcff7f00 ; r11 a card table bázisa, például
; byte[] CARD_TABLE
mov BYTE PTR [r11+r10*1],0x0 ; beállítjuk a 'this' kártyát piszkosra:
; CARD_TABLE[this cím >> 9] = 0
; JDK7(ugyanaz):
mov QWORD PTR [rsi+0x20],rdx
mov r10,rsi
shr r10,0x9
mov r11,0x7f6d852d7000
mov BYTE PTR [r11+r10*1],0x0
; JDK8:
mov QWORD PTR [rsi+0x20],rdx
shr rsi,0x9 ; az okosabb JIT észrevette,
; hogy az RSI-t később nem használjuk,
; úgyhogy helyben megcsinálja a shift műveletet
mov rdi,0x7f2d42817000
mov BYTE PTR [rsi+rdi*1],0x0
Tehát egy referencia beállítása mellé némi egyéb plusz munka járul, ami gyakorlatilag erre való (a >> 9 művelet konvertálja a memóriacímet kártyaindexszé):
CARD_TABLE[this address >> 9]=0;
Ez persze a primitív típusú mezők egyszerű beállításához képest jelentős többletköltség, viszont szükség van rá a megfelelő memóriakezeléshez. Így a youg generáció szemétgyűjtőzése esetén csökken az old generáció átvizsgálási ideje.
Bár ez már igazán nem tartozik a cikk által bemutatni kívánt témakörhöz, nem tudom megállni, hogy a card table apropóján beszámoljak egy érdekes párhuzamos programozási problémáról.
A card table elképzelés használhatónak bizonyult, ugyanakkor kiderült, hogy masszívan párhuzamosított környezetekben teljesítménybeli hátránya lehet. Erről egy Oracle-nél dolgozó kutató számolt be és mivel nem titok, én is megosztom. (Párhuzamos programozásban ezt a problémát false sharing-nak nevezik.) Tegyük fel, hogy a processzorunkban a cache vonal mérete 64 bájt, ami a modern processzorokban szokványosnak számít. Ez azt jelenti, hogy 64 kártya osztozik egy cache vonalon (64*512=32 KB). Így aztán ugyanarra a 32 KB-os területre eső, de különböző szálak által tárolt referenciák miatt mindig ugyanazon card table alatt lévő cache vonalba történik írás. Ez eléggé gyakori write invalidálást és cache koherencia forgalmat eredményez, ami pedig csökkenti a teljesítményt és rossz hatással van a skálázódásra is. Ez a hatás pedig érdekes módon még nagyobb is egy teljes, átmozgatást végző GC után. A szálak ugyanis a TLAB-ok miatt hajlamosak eltérő címtartományokba foglalódni, viszont egy teljes GC után a fennmaradó objektumok sokkal szorosabban fognak egymás mellett elhelyezkedni, vagyis jobban előjön a fent említett probléma. Ráadásul a legtöbb card table-be való tárolás redundáns, hiszen az adott kártyát már valami más korábban valószínűleg piszkosra állította. Ez egy egyszerű megoldást sugallt: a barrierben egyszerű feltétel nélküli tárolás helyett elsőként megvizsgáljuk a kártya állapotát és csak akkor tároljuk az új értéket, ha még tiszta. Ez persze kicsit növeli a barriert és egy feltételes elágazást tesz bele, de elkerüli a problémát.
Ennek a módosításnak a bekapcsolására a JDK 7-be bekerült egy -XX:+UseCondCardMark parancssori opció. Ezzel a fenti kód így módosul:
; rsi a 'this' cím
; rdx a paraméter, referencia a bar-hoz
; JDK7:
0x7fc4a1071d5c: mov r10,rsi ; r10 = this
0x7fc4a1071d5f: shr r10,0x9 ; r10 = r10 >> 9
0x7fc4a1071d63: mov r11,0x7f7cb98f7000 ; r11 = CARD_TABLE
0x7fc4a1071d6d: add r11,r10 ; r11 = CARD_TABLE + (this >> 9)
0x7fc4a1071d70: movsx r8d,BYTE PTR [r11] ; r8d = CARD_TABLE[this >> 9]
0x7fc4a1071d74: test r8d,r8d
0x7fc4a1071d77: je 0x7fc4a1071d7d ; if(CARD_TABLE[this >> 9] == 0)
; goto 0x7fc4a1071d7d
0x7fc4a1071d79: mov BYTE PTR [r11],0x0 ; CARD_TABLE[this >> 9] = 0
0x7fc4a1071d7d: mov QWORD PTR [rsi+0x20],rdx ; this.foo = bar
Ami nagyjából annyit tesz, hogy:
if (CARD_TABLE [this address >> 9] != 0) CARD_TABLE [this address >> 9] = 0;
Ez egy picit több kód, de elkerüli a potenciálisan konkurens írásokat a card table-be.
G1 esetén a card marking egy picit bonyolódik, bár ennek megértéséhez még szükség lesz a később tárgyalandó G1 szemétgyűjtő ismeretére is:
movsx edi,BYTE PTR [r15+0x2d0] ; GC flag beolvasása
cmp edi,0x0 ; if (flag != 0)
jne 0x00000001066fc601 ; GOTO OldValBarrier
Label WRITE:
mov QWORD PTR [rsi+0x20],rdx ; this.foo = bar
mov rdi,rsi ; rdi = this
xor rdi,rdx ; rdi = this XOR bar
shr rdi,0x14 ; rdi = (this XOR bar) >> 20
cmp rdi,0x0 ; ha this és bar nem ugyanaz a generáció
jne 0x00000001066fc616 ; GOTO NewValBarrier
Label EXIT:
; ...
Label OldValBarrier:
mov rdi,QWORD PTR [rsi+0x20]
cmp rdi,0x0 ; if(this.foo == null)
je 0x00000001066fc5dd ; GOTO WRITE
mov QWORD PTR [rsp],rdi ; rdi paraméterként beállítása
call 0x000000010664bca0 ; {runtime_call}
jmp 0x00000001066fc5dd ; GOTO WRITE
Label NewValBarrier:
cmp rdx,0x0 ; bar == null
je 0x00000001066fc5f5 ; GOTO EXIT
mov QWORD PTR [rsp],rsi
call 0x000000010664bda0 ; {runtime_call}
jmp 0x00000001066fc5f5 ; GOTO exit;
Ez nagyjából erről szól:
oop oldFooVal = this.foo;
if (GC.isMarking != 0 && oldFooVal != null){
g1_wb_pre(oldFooVal);
}
this.foo = bar;
if ((this ^ bar) >> 20) != 0 && bar != null) {
g1_wb_post(this);
}
A hívások akkor jelentenek pluszmunkát, ha nem vagyunk elég szerencsések és
Látható tehát, hogy a referenciák írása olyan pluszmunkát jelent, ami a primitív típusoknál nem jelentkezik. Öröm az ürömben, hogy ez csak az írást érinti, az alkalmazások által sokkal gyakrabban végzett olvasást nem.
Ebben a fejezetben végre eljött az, amire mindig is vártunk: megismerjük a HotSpot szemétgyűjtő mechanizmusait:
Az egyes JVM-ek esetén eltérő lehet az alapértelmezett GC: ez a JVM verziójától, típusától (szerver vagy kliens) és az adott platformtól is függ. Szerver JVM-nél Java 5 és 6 esetén általában a parallel collector az alapértelmezett, kliens JVM-nél pedig a serial collector, de például SPARC vagy IA-64 és x86-64 esetén már kliens gépeknél is a parallel collector. A sokféle különböző lehetőség miatt erről én táblázatot itt nem közlök.
A serial collector a fentebb leírt módon működik, azaz a túlélő objektumok a survivorre, majd az old generation-re kerülnek a mark-copy szemétgyűjtési módszerrel. Az old generation és a permanent generation szemétgyűjtése pedig a mark-sweep-compact algoritmussal történik. Ez biztosítja a pointer bump allocation foglalási stratégia működését is. A szemétgyűjtés egy szálon történik és a JVM az alkalmazást teljesen leállítja a safepoint-okban, amíg az folyik. (GC logokban és egyes netes leírásokban a young generációs serial collector DefNew néven jelenik meg, én is így fogok rá hivatkozni a későbbiekben.)
A serial collector általában jó választás kliensoldali alkalmazásokhoz, akár egy 64 megás heap esetén is viszonylag ritka és rövid (< 0,5 mp) leállásokkal jár. Ez grafikus felhasználói felülettel rendelkező, egy felhasználót kiszolgáló alkalmazások esetén megfelelő. Akkor is jól jöhet, ha több JVM osztozik egy processzoron, hiszen ekkor úgysem tud párhuzamosan futni a szemétgyűjtés a processzorok kihasználtsága miatt. Több processzor, nagy terhelés, intenzív memóriahasználat és sok párhuzamos felhasználó esetén viszont már nagyban ronthatja az alkalmazásunk teljesítményét.
A parallel collector alapvetően annyival másabb mint a serial collector, hogy a young generation szemétgyűjtése nem egy, hanem annyi szálon fut, ahány magot ki tud használni. Maga az alapelv viszont nem változott: ugyanúgy megállítja a többi szálat, és mark-copy algoritmust használ. Az old generation szemétgyűjtése megegyezik a serial collector szemétgyűjtésével, ami a mark-sweep-compact algoritmus. A szálak alapértelmezett száma parancssori kapcsolóval is módosítható: -XX:ParallelGCThreads=<szálak száma>. Egy maggal rendelkező gépen az Oracle dokumentációja szerint akkor is a serial collector fog futni, ha a JVM-et expliciten parallel collector bekapcsolásával indították.
A parallel colectort throughput collectornak is nevezik, mivel több magot is használni tud, hogy felgyorsítsa az alkalmazás áteresztőképességét (throughput). Az Oracle olyan alkalmazásokhoz ajánlja, ahol nagy mennyiségű munkát kell elvégezni, de hosszabb megállások az old generáció szemétgyűjtésénél elfogadhatóak. Ilyen például kötegelt feldolgozások vagy nagy számú adatbázis-lekérdezés.
Ennek a GC-nek két altípusa van:
-XX:+UseParallelGC: többszálú young generációs szemétgyűjtés és egyszálú old generációs szemétgyűjtés-tömörítés
-XX:+UseParallelOldGC: mind a young, mind az old generációs GC többszálú, a tömörítéssel egyetemben
Többszálú young generációs szemétgyűjtésből valójában kétféle is létezik:
 A CMS collector-t olyan alkalmazások számára fejlesztették ki, ahol fontos a rövidebb GC-idő, viszont már az
alkalmazás futása mellett is jut a GC számára némi erőforrás. A young generation minor szemétgyűjtése itt is ugyanúgy működik, mint a Parallel Collector esetében, a változás az old
generation szemétgyűjtésében van, amit a jobb oldali - már ismerős - ábra mutat be. Ez négy fázisból áll:
A CMS collector-t olyan alkalmazások számára fejlesztették ki, ahol fontos a rövidebb GC-idő, viszont már az
alkalmazás futása mellett is jut a GC számára némi erőforrás. A young generation minor szemétgyűjtése itt is ugyanúgy működik, mint a Parallel Collector esetében, a változás az old
generation szemétgyűjtésében van, amit a jobb oldali - már ismerős - ábra mutat be. Ez négy fázisból áll:
A két teljes megállási esemény alatti mark fázis többszálú és a konkurens fázisok is lehetnek ilyenek.
Mivel az alkalmazás és a szemétgyűjtő konkurens módon fut egy major GC esetén, a GC szál által még használatban lévőnek tartott objektumok a GC végére elképzelhető, hogy fölöslegessé válnak. Ilyen, már nem használt objektumokat, amiket mégsem pucolt ki, floating garbage-nek hívják. Ezek mennyisége függ a konkurens működés időtartamától és az alkalmazás általi referenciafrissítések gyakoriságától. A floating garbage objektumokat a következő szemétgyűjtési ciklus fogja kidobálni. Ez az ára a rövidebb teljes megállási eseményeknek. Emiatt érdemes kb 20%-kal felülbecsülni az old generation méretét.
A CMS collector ún. non-compacting szemétgyűjtő, azaz tömörítést nem végez, ez pedig töredezettséghez vezet. Ez egyrészt megnehezíti a kezelést, hiszen nem egy mutatót kell karban tartani, hanem egy listában kell nyilvántartani a szabad területeket. A többi szemétgyűjtővel ellentétben a CMS nem akkor fut le, mikor betelik a heap, hanem hamarabb, hogy még képes legyen lefutni. Ha azonban a már nem használt terület felszabadítása még nem teljes, de az old generáció már betelt vagy pedig egy új foglalás már nem sikerült a rendelkezésre álló helyen, akkor az alkalmazás teljesen leállítódik és a jól ismert mark-sweep-compact algoritmus fut le. Ezt az esetet concurrent mode failure-nek hívják és azt jelzi, hogy a CMS paraméterezésén valamit érdemes változtatni.
A CMS elindulásának többféle módja is van.
Egyrészt a CMS becsléseket végez róla, hogy a tenured generáció mikor fog betelni és hogy egy ciklus mennyi ideig tartana. Ezeket a dinamikusan frissített előrejelzéseket használva akkor kezd el futni, amikor még feltételezhető, hogy a befejezése még a tenured generáció betelése előtt megtörténik. Ezek számítása során némi felülbecsléssel él, mert a concurrent mode failure elég költséges tud lenni.
A CMS másrészt akkor is elindul, ha a tenured generáció kihasználtsága egy bizonyos százalékot elér (initiating occupancy). Ez a küszöbérték alapértelmezetten 92%, de Java kiadásról kiadásra változhat és a -XX:CMSInitiatingOccupancyFraction=<N> parancssori paraméterrel is megváltoztatható, ahol N a százalék, vagyis 1 és 100 közötti érték.
A young és tenured generáció GC megállásai függetlenek egymástól, de nem indulnak egyszerre, bár létrejöhetnek gyors egymásutánban. Az egyik generáció GC-jét tehát azonnal is követheti a másiké, ami egy hosszabb megállásnak tűnhet. Ennek elkerülésére a CMS a remark megállást megpróbálja durván félúton az előző és a következő young generációs megállások közé időzíteni. Ez az ütemezés nem vonatkozik az initial mark megállásra, ami általában sokkal rövidebb, mint a remark. Az old generáció konkurens fázisai közben viszont már indulhat young generációs szemétgyűjtés.
Java 7-ig volt a CMS-ben egy ún. incremental mode nevű megoldás is. Bár ez még a Java 8-ban is megvan, de már nem támogatott, mivel hosszú távon kivezetésre kerül. Láttuk, hogy a GC konkurens módban egy vagy több processzort használhat. Nos az incremental mode a hosszú konkurens szakaszok hatásának csökkentését szolgálja azzal, hogy időszakosan megállítja a konkurens fázist és visszaadja a processzort az alkalmazásnak. Ezt i-cms-nek is hívják, és a konkurens módban végzett feladatot tehát elosztja kisebb időszeletekre, amiket a young generációs szemétgyűjtések közé időzít. Ez a funkció akkor hasznos, amikor az alkalmazás, aminek a CMS által biztosított alacsony leállási időre van szüksége olyan gépeken fut, amelyekben kevés (1 vagy 2) processzor van.
Az i-cms mód egy ún duty cycle nevű értékkel vezérli, mennyi munkát lehet a CMS szemétgyűjtőnek elvégezni, mielőtt vissza kell adnia a processzort az alkalmazásnak. A duty cycle a young generációs szemétgyűjtések közötti idő azon százaléka, ameddig a CMS-nek engedélyezett a futás. Az i-cms mód automatikusan kiszámolja a duty cycle-t az alkalmazás viselkedése alapján (ez az ajánlott módszer, amit automatic pacing-nek hívnak), de igény szerint parancssorból is megadható.
Az i-cms parancssori opciói
| Opció | Leírás | Alapérték JSE 5 és korábbinál | Alapérték JSE 6 és későbbinél |
|---|---|---|---|
| -XX:+CMSIncrementalMode | Engedélyezi az incremental mode-ot. Ehhez a CMS-t is engedélyezni kell a -XX:+UseConcMarkSweepGC kapcsolóval. | kikapcsolva | kikapcsolva |
| -XX:+CMSIncrementalPacing | Engedélyezi az automatic pacing funkciót. A duty cycle automatikusan beállításra kerül a JVM által gyűjtött futási statisztika alapján. | kikapcsolva | kikapcsolva |
| -XX:CMSIncrementalDutyCycle=<N> | A minor GC-k közötti idő százaléka (0-100), amíg a CMS futhat. Ha a CMSIncrementalPacing engedélyezve van, akkor ez csak a kezdeti érték. | 50 | 10 |
| -XX:CMSIncrementalDutyCycleMin=<N> | A duty cycle alsó határa százalékban, amikor a CMSIncrementalPacing engedélyezve van. | 10 | 0 |
| -XX:CMSIncrementalSafetyFactor=<N> | Az óvatosság százaléka a duty cycle számításához. | 10 | 10 |
| -XX:CMSIncrementalOffset=<N> | Annak a százaléka, amennyivel a duty cycle jobbra van léptetve (shift) a minor GC-k közötti időben. | 0 | 0 |
| -XX:CMSExpAvgFactor=<N> | A CMS exponenciális átlag GC statisztikáinak számításához használt súlyozás százaléka. | 25 | 25 |
Az Oracle az i-cms finomhangolásához a CMSIncrementalSafetyFactor és a CMSIncrementalDutyCycleMin érték növelését javasolja, valamint az incremental pacing kikapcsolását és fix duty cycle használatát.
A garbage first (G1) szemétgyűjtőt szerverekhez tervezték és alapvetően többprocesszoros, nagy memóriával rendelkező gépekhez szánták. Az volt az alapvető cél, hogy növeljék a JVM-en futó alkalmazások áteresztőképességét és csökkentsék a szemétgyűjtőkre jellemző teljes leállási eseményeket, egyben megjósolhatóvá téve azok hosszát. Mivel az Oracle szerint a G1 alapjaiban jobb megoldás, mint a CMS, hosszú távon szeretnék azt kiváltani. A kettő közötti egyik nagy különbség, hogy a G1 tömöríti a szabad helyeket, ami kiküszöböli a töredezettséggel kapcsolatos problémákat. A G1 emellett a CMS-hez képest jobban megjósolható leállási időket is biztosít és lehetővé teszi a felhasználónak, hogy megadjon kívánt leállási időkeretet.
A G1 a következő alkalmazások számára hasznos:
A G1-et a Java 7-hez fejlesztették ki, de később visszaportolták Java 6-ra is. A Java 9-nél pedig már ez az alapértelmezett. A G1 elsődleges célja az volt, hogy megoldást adjon azon felhasználóknak, akik olyan alkalmazásokat futtatnak, amik nagy heap területet igényelnek korlátozott GC késleltetéssel. Amennyiben régebbi GC-t használunk és nem tapasztalunk hosszú GC megállásokat, akkor nyugodtan maradhatunk a réginél. A friss JDK-k nem igénylik a G1-re váltást. A G1-nél a heap felépítése némileg eltér a korábbiakhoz képest:

A heap itt azonos méretű ún. régiókra van osztva, ezek közül mindegyik a virtuális memória egy összefüggő területét foglalja magában. Bizonyos régióhalmazok a korábban megismert szemétgyűjtőknél látott szerepeket kapnak (éden, survivor, old), azonban immár nincs adott méretük, ami nagyobb rugalmasságot biztosít a memóriahasználatban. (Survivor-ből itt a működés miatt már nincs külön S0 és S1.) A G1 sok tekintetben a CMS-hez hasonlóan működik. Ez is egy konkurens marking fázisban határozza meg, mely objektumok vannak használatban. Mikor a mark fázis kész, a G1 már tudja, hogy melyek a nagyrészt üres régiók. Elsőként ezeket pucolja ki, ami általában nagy szabad területet eredményez. Emiatt a módszer miatt hívják ezt a típust garbage first-nek. Ahogy a név sugallja, a G1 azokra a heap területekre koncentrálja a szemétgyűjtést és a tömörítést, amelyek valószínűleg tele vannak kidobható objektumokkal. A G1 egy ún. megállás-előrejelzési modellt (pause prediction model) használ, hogy megfeleljen a felhasználó által adott megállási időigénynek és annyi régiót választ ki a szemétgyűjtésre, amennyit a megadott állási idő alatt fel tud dolgozni.
A G1 által újrafelhasználásra szánt régiókat ún. evakuálással üríti ki: egy vagy több régióból átmásolja az objektumokat egy újba, ez a folyamat pedig egyszerre szabadítja fel és tömöríti a memóriát. Többprocesszoros rendszereknél ez párhuzamos feldolgozással történik, hogy csökkenjen a leállási idő és nőjön az áteresztőképesség. Így aztán szemétgyűjtésenként a G1 folyamatosan csökkenti a töredezettséget, mindezt a felhasználó által megadott állási idők alatt. Ez mindegyik korábban tárgyalt módszernél fejlettebb: a CMS nem végez tömörítést, a Parallel Collection pedig csak teljes heap tömörítést végez, ami igen nagy állási időket eredményezhet. (A CMS esetén is előfordulhat tömörítés közvetetten: ha már olyan nagyon töredezett az old generáció, hogy full GC-re van szükség, mert a promotálni, vagyis oda áthelyezni kívánt objektum már nem fér el másképp. A full GC-k a G1-nél is egyszálúak, viszont az alkalmazás beállításainak megfelelő finomhangolásával elkerülhetőek.)
Fontos megjegyezni, hogy a G1 nem valósidejű szemétgyűjtő. Nagy valószínűséggel megfelel ugyan a meghatározott állási időknek, de nem teljesen. A korábbi szemétgyűjtések tapasztalatai alapján végez becslést, hogy mennyi régiót lehet szemétgyűjtőzni a felhasználó által megadott idő alatt. Ezáltal meglehetősen pontos képe van arról, hogy mennyi költséget jelent a régiók szemétgyűjtőzése és ezt a modellt használja, hogy meghatározza, melyik és mennyi régiót szemétgyűjtőzzön, hogy benne maradjon az adott megállási időkeretben.
A G1 szemétgyűjtés lépésről lépése
1. G1 heap
A heap a G1-nél egybefüggő memóriaterület, ami több fix méretű régóra van felosztva. A régióméretet és azok mennyiségét a JVM induláskor határozza meg. A cél az, hogy ne legyen több 2048 régiónál (de mindenképpen kettő hatvány legyen), amelyek mérete 1-32 MB közötti lehet a megadott heapmérettől függően.
2. G1 heap objektumfoglalás
A régiók valójában az éden, survivor és old generáció területek logikai reprezentációi.
A színek jelzik, hogy melyik régió milyen területnek felel meg. Az élő objektumok evakuálódnak (másolódnak vagy mozgatódnak) egyik régióból a másikba. A régiókat úgy tervezték, hogy párhuzamosan lehessen őket szemétgyűjtőzni az alkalmazás többi szálának leállításával vagy anélkül is. A képen látható, hogy a régiók édenként, survivorként és old generációként foglalhatóak le. Valójában van egy negyedik típusú objektum is, amit humongous régiónak neveznek. Ezeket a régiókat arra tervezték, hogy olyan objektumokat tároljanak, amelyek egy szabvány régiónak legalább 50%-át elfoglalják (vagy egy szabvány régiónál akár nagyobbak is lehetnek). Ezek folyamatosan egymás után következő régiókban tárolódnak. (Ha egy objektum nagyobb, mint egy régió, akkor a G1 esetén automatikusan az old generációban jön létre.) Egy plusz típusú régió pedig a heap nem használt területeinek jelzésére szolgál.
3. Young generáció a G1-ben
A heap nagyjából 2048 régióra oszlik. A minimális méret 1 MB, a maximális pedig 32 MB, de egy JVM-nél futás közben minden régió azonos méretű. A kék régiók tárolják az old generációs objektumokat, a zöldek meg a young generációsakat.
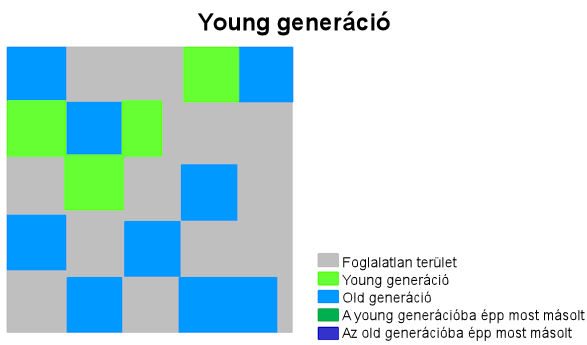
Ahogy a mellékelt ábra is mutatja, a régióknak nem szükséges folyamatosan elhelyezkedniük, mint a régebbi GC-k esetén. (A képeket az Oracle hivatalos oktatóanyagából vettem. A képre egy négyzethálót is oda kell képzelni, amelyek a régiókat határolják, a foglalt színek a régiók belső foglalását jelzik, nem pedig egy-egy régiót.)
4. Young szemétgyűjtés a G1-ben
Az élő objektumok evakuálódnak egy vagy több survivor régiókba, miközben nő az élettartamuk is. Amelyek a megfelelő életkort (aging threshold) elérik, az old generációs régiókba kerülnek (promote).

Ez a lépés egy teljes megállási esemény. A következő young szemétgyűjtőhöz kiszámítódik az éden és survivor mérete, amihez a G1 nyilvántartást is vezet. Olyan dolgok, mint a megállási idő, szintén figyelembe lesznek véve a számítás során. Ez a megközelítés egyszerűvé teszi a régiók átméretezését, szükség szerint nagyobbak vagy kisebbek is lehetnek.
5. Young szemétgyűjtés vége a G1-ben
Az élő objektumok evakuálódnak a survivor vagy old generációs régiókba.

A G1 esetén azt látjuk, hogy több GC szál dolgozik egyszerre, mint például a CMS esetén. A szálaknak itt ugyanis némi plusz munkájuk is van még: folyamatosan karban kell tartani a remembered sets és collection sets nevű adatstruktúrákat.
Collection sets (CSets): ez tárolja azon régiók listáját, amelyeket majd szemétgyűjtőzni lehet. Ennek során egy CSet-ben minden régió élő adata evakuálásra kerül (másolás/mozgatás). Egy CSet régiói lehetnek éden, survivor és/vagy old generációbeliek. A CSet-eknek az Oracle szerint kevesebb mint 1% többletköltsége van a JVM memóriaméretére.
Remembered sets (RSets): ezek tartják nyilván az egy régióhoz tartozó objektumreferenciákat. Ez teszi lehetővé a különböző régiók egymástól független szemétgyűjtőzését. Régiónként pontosan egy RSet van. Például amikor az A, B és C régiókat vizsgáljuk, tudnunk kell, hogy van-e rájuk referencia a D és E régiókból, hogy meghatározzuk azt, élőek-e. A teljes heap és a teljes régiók átvizsgálása elég hosszú lenne. Így a G1-nek a teljes átvizsgálás helyett csak a régióhz tartozó RSet-et kell vizsgálnia. Egy régióhoz tartozó RSet listázza a kívülről a régióba hivatkozó referenciákat. Az RSet hasonló, mint a korábbi szemétgyűjtőknél már tárgyalt card table mechanizmus. Az RSet-ek átlagos teljesítménybeli többletköltsége az Oracle szerint kevesebb, mint 5%, cserében lehetővé teszik a független szemétgyűjtőzést.
Az alábbi ábrákon látható, hogy minden régiónak (nagy szürke négyzet) van egy RSet-je, amiben fel vannak jegyezve a máshonnan ebbe a régióba mutató referenciák. Ezeket a referenciákat kiegészítő GC root-okként lehet kezelni. Megjegyzendő, hogy az old régiókban lévő a konkurens marking fázisban szemétnek nyilvánított objektumok akkor is figyelmen kívül lesznek hagyva, ha van hozzájuk kívülről hivatkozó referencia: a hivatkozó objektumok is kidobandóak ebben az esetben.

A következő lépés ugyanaz, amit más szemétgyűjtők is csinálnak: több párhuzamos GC szál meghatározza, hogy mely objektumok vannak használatban és melyek nem:

Az élő objektumok végül a survivor régiókba kerülnek át (új survivor régió létrehozásával, ha szükséges). Az immár üres régiók felszabadíthatók és új objektumfoglalásokra felhasználhatók.

Az alkalmazás futása közben két módszer segít karban tartani az RSet-eket:
Old generáció szemétgyűjtése G1-gyel
Akárcsak a CMS, a G1 is arra lett tervezve, hogy rövid megállásokat okozzon az old generációs objektumok esetén. A G1 az old generáción a következő fázisokban működik:
A mixed collection egy olyan szemétgyűjtés, ami a young és old generáció tömörítését és evakuálását is elvégzi. (Ekkor a CSet-ben old és young generációs régiók is szerepelnek). Egy mixed collection általában több mixed GC ciklus alatt készül el. Amikor megfelelő mennyiségű old régió is szemétgyűjtőzve lett, a G1 visszaáll a csak a young generáció GC-zésére, amíg a következő marking ciklus véget nem ér. Ezt a viselkedést számos parancssori beállítással lehet vezérelni, ezekről később lesz szó. Egy mixed collection nem mindig követi a cleanup fázist. Amikor például az old generációból konkurens módon fel lehet szabadítani nagy részeket, akkor erre nincs szükség. Tehát lehet számos csak young generációs evakuációs megállás a concurrent marking vége és a mixed evakuációs megállás között.
Ezek alapján a G1 szemétgyűjtés folytatása lépésről lépésre
6. Initial marking
Az initial marking rá van ültetve egy young generációs GC-re. A logokban a következőképp van jelölve: GC pause (young)(inital-mark). Vagy (G1 Evacuation Pause) (young) (initial-mark). Ekkor egyben a young terület evakuációja is megtörténik.

7. Concurrent marking
Amennyiben a GC üres régiókat talált (X-szel jelölve), azok a remark fázis után azonnal törlődnek. Emellett azok az információk is itt számolódnak, amelyek az életben lévőséget meghatározzák.

8. Remark
Az üres régiók eltávolítása és újrafelhasználása. Életben lévőség meghatározása az összes régióra.

9. Copy/cleanup fázis
A G1 kiválasztja a "legkevésbé életben lévő" régiókat, ezeket lehet a leggyorsabban szemétgyűjtőzni. Ezek a régiók össze lesznek gyűjtve egy young GC-vel egyidőben. A logban ezt a következő jelöli: [GC pause (mixed)]. Tehát a young és old generációk egy időben vannak szemétgyűjtőzve.

10. copying/cleanup fázis utáni állapot
A kiválasztott régiók szemétgyűjtőzése és tömörítése megtörtént: a képen sötétkék és sötétzöld régiókkal jelölve.

Ezzel befejeződött az old generációs GC. Sajnos a G1-nél is vannak olyan esetek, amikor semmi se segít rajtunk, csak egy full GC. Ezek:
Vannak helyzetek, amikor a szabványos szemétgyűjtés nem megfelelő. Kedvcsinálóként dióhéjban lássunk két, az előzőektől meglehetősen eltérő módszert: a távoli szemétgyűjtőt, ami elosztott objektum referenciákkal foglalkozik és a valósidejű szemétgyűjtőt, ami valós idejű működést garantál. (Vagy legalábbis szeretne.)
Remote garbage collector - távoli szemétgyűjtő
A távoli eljáráshívással (remote method invocation - RMI) úgy lehet egy lokális objektumot (kliensoldali stub) használni, hogy az gyakorlatilag egy másik JVM-ben lévő (szerveroldali) másik objektumot reprezentál. Az RMI hívások esetén természetesen a szerveroldali objektumnak is léteznie kell. Tehát az RMI esetén szükség van rá, hogy úgy tekintsünk a szerveroldali objektumra, hogy arra a kliensoldali stub-ból referencia hivatkozik. Mivel a szervernek nincs módjában tudnia erről a referenciáról, valamiféle távoli szemétgyűjtési megoldásra van szükségünk. Egy ilyenre például:
Azon szerveroldali objektumok, amiket már nem használ egy kliens sem, ezáltal túlélhetnek szemétgyűjtéseket (kliens objektumok ilyenkor már nincsenek életben). Egy egyébként inaktív kliens fenntarthat egy távoli objektumot hosszú ideig még akkor is, ha az objektum már egyébként készen állna a kisöprésre. Ha a kliens objektum nem vesz részt szemétgyűjtésben, akkor a hozzá tartozó szerverobjektum is megmarad. Extrém esetekben ez azt jelenti, hogy sok inaktív kliens rengeteg nem használt szerverobjektumhoz vezet, amiket nem lehet kisöpörni. Ez pedig szépen out of memory hibába taszíthatja a világot szervert.
Ennek elkerülésére az elosztott szemétgyűjtő (RMI garbage collector) rendszeres időközönként kikényszerít egy kliensoldali major GC-t (annak minden teljesítménybeli negatív kihatásával). Ezt az időközt a GCInterval rendszertulajdonság adja meg. Ugyanez a beállítás megvan szerveroldalon is és ugyanezt csinálja. (A Java 6-ig mindkét beállítás egy perces alapértéket tartalmazott, ami nem volt valami jó hatással a teljesítményre. A Java 6-ban a szerveroldali alapértelmezés egy órára módosult.) Ennek a beállításnak igazából általában a kliensoldalon van értelme (hogy lehetővé tegye a szervernek a távoli objektumok eltávolítását), de nem egészen világos, hogy miért létezik ez szerveroldalon is. Egy szerveroldali távoli objektmumot a szemétgyűjtő kisöpör amikor a bérlet lejár vagy amikor a kliens explicit módon törli azt. Az explicit szemétgyűjtésnek nincs hatása erre, ezért ajánlatos ezt a beállítást szerveroldalon minél nagyobbra venni.
Egyébként ajánlatos, hogy az RMI stateless service interfészekre legyen korlátozva. Mivel ezek az interfészek csak egy példányban léteznek és sosem kell őket szemétgyűjtésben kezelni (legalábbis amíg az alkalmazás fut), nincs szükség távoli szemétgyűjtésre. Ha ilyen módon korlátozzuk az RMI-t, akkor a kliensoldali intervallumot is elég nagyra tudjuk venni és így eltávolíthatjuk az elosztott szemétgyűjtőt az egyenletünkből.
Valósidejű szemétgyűjtők
A valósidejű rendszerek majdnem azonnali (egyszámjegyű millimásodperces tartományon belüli) végrehajtási sebességet biztosítanak minden egyes feldolgozott kéréshez. Ezeknél problémát okozhat a szemétgyűjtés által futásidejű felfüggesztésekhez használt idő, különösképpen azért, mert a GC futtatás gyakorisága és időtartama gyakorlatilag megjósolhatatlan. Optimalizálhatunk alacsony megakadási időre, de nem tudunk maximális megakadási időt garantálni. Szerencsére több megoldás is van a problémára.
A Sun eredetileg specifikált egy Java Real-Time System nevű dolgot (Java RTS) egy speciális valósidejű szemétgyűjtővel, amit Henriksson GC-nek hívnak és megpróbált megfelelni a szigorú szálütemezésnek. Ez az algoritmus megpróbálja garantálni, hogy a szemétgyűjtés nem következik be, amíg kritikus szálak (amiket prioritás ad meg) feladatot hajtanak végre. De ez az algoritmus sem garantálja, hogy kritikus szálak sosem lesznek felfüggesztve. Ráadásul a Java RTS specifikáció definiál hatókörös és halhatatlan (immortal) memóriaterületeket is. Egy hatókört (scope) úgy lehet definiálni, hogy egy adott metódust megjelölünk egy hatókörös memóriaterület kezdetének. Azon metódus végrehajtása során minden lefoglalt objektum a hatókörös memóriaterület részének tekintett. Amikor a metódus végrehajtása befejeződött és a hatókörös memóriaterületre nincs többé szükség, minden ott lefoglalt objektum törölhetővé válik. Tulajdonképpeni szemétgyűjtés nem történik, a hatókörös memóriaterületen foglalt objektumok felszabadulnak és az összes használt memóriaterület azonnal újrahasznosítódik, miután a definiált hatókör végetér.
A halhatatlan objektumok az immortal memóriaterületen foglalódnak le és sosem vesznek részt a szemétgyűjtésben, ami nagy előny. Viszont ezeknek sosem szabad hatókörös objektumokra hivatkozniuk, mert az inkonzisztenciához vezetne, mivel a hatókörös objektum anélkül törlődik, hogy arra hivatkozó referenciaellenőrzés történne.
Ez a két tulajdonság olyan memóriaszervezési lehetőséget ad a kezünkbe, ami a Java esetén egyébként nem létezik és lehetővé teszi, hogy minimalizáljuk a GC megjósolhatatlanságát a válaszidőnkben. A hátránya az, hogy ez nem része a szabványos JDK-nak, tehát némi kódmódosítás szükséges hozzá, nameg az alkalmazás átfogó ismerete. (És ha jobban belegondolunk, ezek bevezetésével visszatértünk a szemétgyűjtés nélküli programozáshoz...)
Az IBM WebSphere és a JRockit is biztosít valósidejű szemétgyűjtőket. Az IBM a sajátját úgy reklámozza, mint ami 1 ms-nál kisebb megállásokat biztosít. A JRockit egy determinisztikus szemétgyűjtőt ad, aminél a legnagyobb GC időt be lehet konfigurálni. Vannak egyébként olyan JVM-ek is, mint például az Azul Systems Zing nevű JVM-e, ami úgy próbálja megoldani ezt a problémát, hogy teljesen megszünteti a teljes megállási eseményt a szemétgyűjtésből. (És van számos valósidejű Java implementáció is.)
Összefoglalva nézzük át, a különböző parancssori beállításokkal milyen szemétgyűjtést lehet beállítani az egyes generációkra. A sor a young generációs, az oszlop pedig az old generációs szemétgyűjtőt tartalmazza. Az üresen hagyott cellakonfigurációknak nincs értelme.
| Old Gen. | |||||
|---|---|---|---|---|---|
| Young Gen. | DefNew | ParNew | Scavenge | G1 | |
| Serial | -XX:+UseSerialGC | -XX:+UseParallelGC | |||
| Parallel | -XX:+UseParallelOldGC | ||||
| CMS | -XX:-UseParNewGC -XX:+UseConcMarkSweepGC1 | -XX:+UseConcMarkSweepGC | |||
| i-CMS | -XX:+CMSIncrementalMode -XX:+UseConcMarkSweepGC -XX:-UseParNewGC1 | -Xincgc1 | |||
| G1 | -XX:+UseG1GC |
1: Java 8-tól deprecated
Gyakran van szükség rá, hogy egy futó JVM-ről diagnosztikai adatokat kérdezzünk le, például pont azért, hogy megtudjuk, milyen GC-t használ vagy hogy áll a heap. Erre a JDK több parancssori eszközt biztosít, ezeket én is használtam a cikk írása közben (a JDK bin könyvtárában csücsülnek):
jps (dokumentáció): egyszerű kilistázása a gazdagépen futó JVM-eknek. (Távoli gépen futó JVM-eket is el lehet vele érni.) Paraméterek nélkül is hívható, de a következő módon a JVM-eknek átadott paramétereket is megkapjuk:
jps -vVm
jcmd (dokumentáció): a jps-hez hasonló, de annál bővebb lehetőségeket biztosító eszköz (bár távoli JVM-ekhez attól eltérően nem alkalmas). Paraméterek nélkül hívva szintén kilistázza a futó JVM-eket. Paraméterként meg lehet adni neki a kívánt processz azonosítóját majd pedig egy diagnosztikai parancsot. Az adott JVM diagnosztikai parancsait a help paranccsal kérhetjük le. Tehát:
jcmd <PID> help
majd pedig - ha például listázott ilyen lehetőséget - a JVM flag-jeinek lekérdezése:
jcmd <PID> VM.flags
Egyszerre csak egy parancs adható át a JVM-nek és egyes parancsokhoz további paraméterek megadása is lehetséges.
jinfo (dokumentáció): egy nem támogatott, de azért meglévő eszköz, aminek a JVM pid-jét kell paraméterként megadni és rendkívül széles körű információkat ad vissza a JVM rendszertulajdonságairól, flag-jeiről.
jstat (dokumentáció): szintén nem támogatott, de azért meglévő eszköz statisztikai adatok lekérdezésére. Paraméterként egy statisztikai parancsot vár (elég sok mindent tud) és szintén a kívánt szál PID-jét. Ezt a dokumentáció lvmid-nek titulálja, mert szintén lehet vele távoli JVM-eket is birizgálni, ekkor host-ot és portot is vár, de helyi gépen egy egyszerű PID-del is megelégszik. Ezzel a paranccsal főként a szemétgyűjtő működésével kapcsolatos információkat kérhetjük le, például:
jstat -gcutil <PID>
A jstat-nak azt is meg lehet adni, hogy mennyi időközönként (vagy hány alkalommal) mutassa meg a JVM állapotát. Ha ezt 1 másodpercenként szeretnénk megtenni:
jstat -gcutil <PID> 1s
"s" helyett ezredmásodperceket is megadhatunk "ms" jelöléssel.
Amint azt bizonyára mindenki jól tudja, a Java-ban vannak szabványos paraméterek, amiket minden JVM megért. Ilyen például a -version. Vannak nem szabványosak, amelyek egyáltalán nem biztos, hogy minden JVM-ben megvannak. Ezek -X-szel kezdődnek. Ilyen például a HotSpot-ban lévő -Xmx a memória beállítására. Ezen kívül a -XX-szel kezdődőek speciális futásidejű viselkedéseket vezérelnek. Ezek egy részét : utáni + vagy - segítségével lehet kapcsolni. Ilyenek például a fenti, adott GC-típust megadó paraméterek, vagy a -XX:+PrintGCDetails, amivel a bővebb GC logolást lehet be- (-XX:+PrintGCDetails) vagy kikapcsolni (-XX:-PrintGCDetails). A szemétgyűjtőre egyetlen szabványos JVM paraméter vonatkozik:
-verbose:gc
általános információk megjelenítése minden egyes GC-ről a szabványos kimenetre
A HotSpot azért ennél már jóval több saját paraméterezést tartalmaz a szemétgyűjtőkkel kapcsolatban:
-Xloggc:filename
a GC logolást egy megadott fájlba irányítja át. Amennyiben ezzel egyszerre a -verbose:gc paraméter is meg van adva, azt a JVM figyelmen kívül hagyja.
-Xnoclassgc
az osztályok szemétgyűjtőzésének kikapcsolása. Ezzel megtakaríthatunk némi időt a GC megállások során, viszont így az osztály objektumok érintetlenek maradnak és folyamatosan élőnek lesznek jelölve. Így számítani kell nagyobb memóriafoglalásra és esetleg még egy java.lang.OutOfMemoryError is felbukkanhat a láthatáron.
-XX:+DisableExplicitGC
letiltja az explicit System.gc() hívások feldolgozását. Ezután természetesen továbbra is meg lehet hívni, csak sunyi módon semmi nem fog történni.
-XX:+ExplicitGCInvokesConcurrent
lehetővé teszi, hogy a System.gc() hívás egy konkurens szemétgyűjtést indítson el. Csak a -XX:+UseConcMarkSweepGC paraméterrel együtt van értelme.
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
ugyanaz mint az előző, csak még a nem használt osztályokat is kipucolja.
-XX:InitiatingHeapOccupancyPercent=N
beállítja, hogy a konkurens GC a heap milyen kihasználtságánál induljon el (N százalékban). Ezt a paramétert azon szemétgyűjtők használják, amelyek a konkurens GC ciklust a teljes heap és nem csak egy generáció foglaltsága alapján indítják (például a G1). 0 érték megadása folyamatos GC-zést jelent.
-XX:MaxGCPauseMillis=N
beállít egy előirányzott maximumot GC-zés időtartamára (ezredmásodpercekben). Ez csak egy irányelvet ad meg, amihez a JVM megpróbálja tartani magát. Alapértelmezetten egyébként nincs ilyen időtartam a JVM-ben.
-XX:MaxHeapFreeRatio=N
beállítja, hogy egy GC után mennyi lehet a heap maximális szabad területe. Amennyiben a szabad terület ezen érték fölé megy, a heap leméretezésre kerül (vagyis megnő a virtuális terület). Alapértelmezetten ennek értéke 70%.
-XX:MaxTenuringThreshold=N
a tenuring threshold küszöbérték beállítása. Alapértelmezett értéke a parallel collector esetén 15, a CMS esetén 6.
-XX:MinHeapFreeRatio=N
egy GC után a minimális engedélyezett szabad heap terület százalékban. Amennyiben a szabad heap terület ezen érték alá megy, a mérete megnövelődik (a virtuális terület csökken). Alapértelmezett értéke 40%.
-XX:+ParallelRefProcEnabled
azon alkalmazásoknál, amelyek intenzíven használják a java.lang.ref.Reference osztályt (vagyis a gyenge referenciákat), a GC sok időt tölthet annak eldöntésével, hogy mit lehet a nem erős referenciákból kidobni és mit nem. A remark fázis ezt alapesetben egy szálon teszi. Ez a paraméter engedélyezi ezen referenciák többszálú feldolgozását.
-XX:+PrintAdaptiveSizePolicy
plusz információk kiírása a generációk adaptív, vagyis igény szerinti átméretezéséről.
-XX:+PrintGC
GC logolás bekapcsolása.
-XX:+PrintGCApplicationConcurrentTime
kiírja a logba, mennyi idő telt el az utolsó GC miatti megállás óta.
-XX:+PrintGCApplicationStoppedTime
kiírja a logba, mennyi ideig tartott a GC megállás.
-XX:+PrintGCDateStamps
minden egyes GC eseményhez beírja a logba a dátumot és időt.
-XX:+PrintGCDetails
bővebb GC logolás bekapcsolása.
-XX:+PrintGCTaskTimeStamps
minden egyes GC szálhoz időbélyeg írása a logba
-XX:+PrintGCTimeStamps
időbélyeg írása a logba minden egyes GC eseményhez. Ez relatív időbélyeg, vagyis a JVM indulása óta eltelt időt mutatja.
-XX:+PrintTenuringDistribution
tenuring információk megjelenítése a logban, vagyis hogy milyen mennyiségű oobjektum van adott életkorban. Ilyesmi lesz az eredménye:
- age 1: 28992024 bytes, 28992024 total
- age 2: 1366864 bytes, 30358888 total
- age 3: 1425912 bytes, 31784800 total
...
Az age 1 objektumok a legfiatalabb túlélők, amik épp most kerültek az édenről a survivor területre.
-XX:+ScavengeBeforeFullGC
minden full GC előtt engedélyez egy minor GC-t. Ez alapértelmezetten be van kapcsolva és az Oracle nyomatékosan javasolja, hogy ne is kapcsolja ki senki. Ha lefut a full GC előtt egy minor GC, akkor csökken az old generációból a young generációra hivatkozó referenciák száma.
-XX:StringDeduplicationAgeThreshold=N
amikor a String objektumok elérik a megadott életkort (vagyis ennyiszer élték túl a szemétgyűjtést), alkalmassá válnak a deduplikálás elvégzésére. Megjegyzendő viszont, hogy azon sztringek, amelyek már ezt megelőzően az old generációba promotálódtak, mindenképpen részt vesznek a deduplikációban, az életkoruktól függetlenül. Alapértelmezett értéke 3.
-XX:+UseGCOverheadLimit
a szemétgyűjtő algoritmusok OutOfMemoryError kivételt dobnak, ha az alkalmazás futásának már túl sok ideje esik a GC-re: ha a teljes idő több, mint 98%-a a GC-vel telik és a heap kevesebb, mint 2%-át sikerül ennek során felszabadítani. Ez a tulajdonság meggátolja, hogy az alkalmazások túl sok ideig fussanak anélkül, hogy lényegi munkát végeznének, mert a heap túl kicsi. Ezzel a paraméterrel kikapcsolhataó ez a funkció, ha szükséges. CMS esetén a szabály annyiban módosul, hogy a konkurens módon futó rész nem számolódik bele a 98%-ba, csak a teljes megállási esemény.
-XX:+UseStringDeduplication
a sztring deduplikálás bekapcsolása. Ennek a használatához a G1 szemétgyűjtőt is be kell kapcsolni.
Már láttuk, hogy a sok sztring objektum memóriafoglalásának csökkentésére a Java tartalmaz egy internalizálás nevű funkciót. A Java 8-ban emellett megjelent egy sztring deduplikálás nevű új tulajdonság, ami előnyt kovácsol abból, hogy a sztringek belsejében final típusú karaktertömbök vannak, tehát a JVM tud velük huncutkodni. A deduplikálás alapértelmezetten ki van kapcsolva és használatához G1 szemétgyűjtőre is szükség van.
UTF-16-os sztringek esetén minden egyes karakterhez két bájt szükséges. Nem szokatlan, hogy egy program memóriafoglalásának 30%-át a sztringek teszik ki. Ha a deduplikálás be van kapcsolva, akkor a szemétgyűjtő egy sztring objektumnál veszi a karaktertömbök hash értékét és gyenge referenciával eltárolja a tömbre hivatkozva. Amikor talál egy másik sztringet ugyanolyan hash kóddal, karakterről karakterre összehasonlítja a kettőt. Ha megegyeznek, akkor az egyik sztringet úgy módosítja, hogy a karaktertömbjének referenciája a másik sztringre mutasson. Ezután az első karaktertömbre már nem hivatkozik más, így a szemétgyűjtő ki tudja pucolni. Ennek a folyamatnak persze van némi többletköltsége, de szigorú korlátok vezérlik. Például ha egy sztringre sokáig nem találni duplikátumokat, akkor többé már nem is keres hozzá a G1.
Ez a funkció elsőként a Java 8 update 20-ban jelent meg. Tekintsük a következő kódot:
package hu.egalizer.gctest; import java.util.LinkedList; public class Durvasag { private static final LinkedList<String> lotsOfStrings = new LinkedList<>(); public static void main(String[] args) throws Exception { int iteration = 0; while (true) { for (int i = 0; i < 100; i++) { for (int j = 0; j < 1000; j++) { lotsOfStrings.add("String " + j); } } iteration++; System.out.println("Survived iteration: " + iteration); Thread.sleep(100); } } }
Futtassuk ezt Java 8 alatt a következő JVM paraméterekkel: -Xmx256m -XX:+UseG1GC
A program 30 iteráció után java.lang.OutOfMemoryError kivétellel ér véget.
Most futtassuk a következőképp: -Xmx256m -XX:+UseG1GC -XX:+UseStringDeduplication -XX:+PrintStringDeduplicationStatistics
Így már jelentősen tovább fut és 50 iterációig elér. A JVM most ki is írja, hogy mit csinál:
[GC concurrent-string-deduplication, 8323.1K->0.0B(8323.1K), avg 99.6%,
0.0209513 secs]
[Last Exec: 0.0209513 secs, Idle: 0.2464255 secs, Blocked: 0/0.0000000
secs]
[Inspected: 213500]
[Skipped: 0( 0.0%)]
[Hashed: 213500(100.0%)]
[Known: 0( 0.0%)]
[New: 213500(100.0%) 8323.1K]
[Deduplicated: 213500(100.0%) 8323.1K(100.0%)]
[Young: 12( 0.0%) 480.0B( 0.0%)]
[Old: 213488(100.0%) 8322.6K(100.0%)]
[Total Exec: 4/0.0396959 secs, Idle: 4/0.4761534 secs, Blocked: 0/0.0000000
secs]
[Inspected: 404033]
[Skipped: 0( 0.0%)]
[Hashed: 403112( 99.8%)]
[Known: 768( 0.2%)]
[New: 403265( 99.8%) 15.4M]
[Deduplicated: 401960( 99.7%) 15.3M( 99.6%)]
[Young: 21( 0.0%) 832.0B( 0.0%)]
[Old: 401939(100.0%) 15.3M(100.0%)]
[Table]
[Memory Usage: 64.6K]
[Size: 2048, Min: 1024, Max: 16777216]
[Entries: 2073, Load: 101.2%, Cached: 0, Added: 2073, Removed: 0]
[Resize Count: 1, Shrink Threshold: 1365(66.7%), Grow Threshold:
4096(200.0%)]
[Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0]
[Age Threshold: 3]
[Queue]
[Dropped: 0]
A log nagyon jó, mert nem nekünk kell összeadni az egyes futások adatait, hanem azok is ott láthatók a Total Exec. részben.
A logrészlet a deduplikáció negyedik futását mutatja, ami 20 ms-ig tartott és nagyjából 210 ezer sztringet nézett át. Ezek mindegyike új volt, vagyis eddig még nem vizsgált. Ezek a számok persze némileg máshogy néznek ki valós alkalmazásokban, ahol a sztringeket többször átadogatják egymásnak a metódusok, így néhányuk ekkorra már szerepel az átnézésben vagy már van hashkódja (mint tudjuk, a sztringek hash kódja lusta kiértékeléssel történik, tehát csak akkor amikor elsőként szükség van rá). Itt még mind a 213500 sztring most lett elsőként szép magyar kifejezéssel szólva hash-elve.
A fenti példában minden sztringet deduplikálni (újabb szép magyar szó) lehetett, így 8,1 MB adatot tudott kipucolni a memóriából. A Table rész információt ad a belső adminisztrációs tábláról, a Queue pedig megmutatja, hogy mennyi deduplikációs kérés lett eldobva a terhelés miatt; ez a tulajdonság része a többletköltség-csökkentő mechanizmusnak.
Felmerül a kérdés: hogy viszonyul ez az egész a sztring internalizáláshoz? Nos amint azt bizonyára minden szemfüles olvasó észrevette, nagyon hasonló a kettő, viszont az internalizálás ugyanazt a String példányt használja fel, nem csak a karaktertömböt. Az viszont különbség, hogy a futásidőben dinamikusan létrehozott sztringek esetén (például amikor adatbázisból olvasunk be sok szöveges adatot), az internalizálás explicit odafigyelést igényel fejlesztés közben, a deduplikálást viszont a háttérben automatikusan elvégzi a G1 (persze csak ha be van kapcsolva). Mivel mindez aszinkron és a GC-vel konkurens módon, annak futása közben működik, ezért viszonylag kis többletköltsége van. Ha a példaprogramban nem lenne ott a sleep, akkor persze túl sok munka esne a szemétgyűjtőre és a deduplikálás egyáltalán nem futna. De ez a probléma lényegében csak a példakódnál jelentkezik, valódi alkalmazásoknak általában van némi szabad idejük, hogy ezt a GC elvégezhesse.
A specifikusan parallel collector szemétgyűjtőhöz való parancssori kapcsolók a következők:
-XX:ParallelGCThreads=N
a parallel GC által használható szálak száma a young és old generáció szemétgyűjtéséhez. Alapértelmezett értéke attól függ, mennyi mag áll a JVM rendelkezésére.
-XX:InitialSurvivorRatio=N
a kezdeti survivor arány. Ezt a méretet a JVM az alkalmazás viselkedése alapján futás közben módosítja, hacsak nincs kikapcsolva az adaptív átméretezés (-XX:-UseAdaptiveSizePolicy). A következő képlet ajánlott az arány kiszámításához (S a survivor terület, Y a young generáció, R a kezdeti survivor terület hányadosa):
S=Y/(R+2)
Az egyenletben a 2 jelenti a két survivor területet. Minél nagyobb érték van megadva a kezdeti survivor terület arányának, annál kisebb lesz a kezdeti survivor terület mérete. Alapértelmezetten ez az arány 8, tehát 2 MB-os young generációnál 0,2 MB.
A specifikusan CMS-hez való parancssori kapcsolók a következők (az i-CMS-t már korábban tárgyaltam):
-XX:CMSInitiatingOccupancyFraction=N
megadhatjuk vele, hogy az old generáció hány százalékos telítettségénél (N) induljon el a CMS szemétgyűjtés. Bármely negatív érték (az alapértelmezett -1 is) azt jelenti, hogy a -XX:CMSTriggerRatio paraméter határozza meg ezt az értéket.
-XX:+CMSScavengeBeforeRemark
láttuk, hogy a CMS-nek két teljes megállási eseménye van (initial mark és remark). Ezek gyorsabban lefuthatnak, ha nem kell a young és old generáció között még külön referenciákat vizsgálniuk, ezért ezzel a paraméterrel bekapcsolhatjuk, hogy a remark fázis előtt fusson le egy minor GC. Ha viszont bekapcsoljuk, akkor ez esetben a GC logokban akkor is látunk minor GC-ket, ha az éden terület még nincs is tele. Persze az nem csak emiatt az opció miatt lehet, hanem amiatt is, mert a programunk olyan nagy objektumokat szeretne lefoglalni, ami már nem fér el a maradék szabad helyen.
-XX:CMSTriggerRatio=N
a MinHeapFreeRatio azon százaléka, amennyi lefoglalt, mielőtt egy CMS szemétgyűjtés elindul.
-XX:ConcGCThreads=N
a konkurens GC által használt szálak száma. Alapértelmezett értékét a JVM maga határozza meg az elérhető magok számából.
-XX:+UseCMSInitiatingOccupancyOnly
annak beállítása, hogy a CMS indítását csak a kihasználtság értéke vezérelje. Alapesetben ez a kapcsoló ki van kapcsolva és más tényezők is részt vesznek a CMS indításának meghatározásában.
A specifikusan G1 szemétgyűjtőhöz való parancssori kapcsolók a következők:
-XX:G1HeapRegionSize=N
a régiók méretének beállítása, így nem a JVM-re bízzuk ennek eldöntését. N értéke 1m és 32m között lehet.
-XX:+G1PrintHeapRegions
logolás során kiírja, hogy a G1 mely régiókat foglalta le és szabadította fel.
-XX:G1ReservePercent=N
a szabadnak fenntartott memória százalékértékének beállítása. Növelésével lehet csökkenteni annak a rizikóját, hogy az objektumok új régiókba másolásakor elfogyjon a memória. Más szóval csökkenthető a promotion failure jelentkezésének valószínűsége. Amikor ezt módosítjuk (alapértelmezetten 10%), a heap méretét is módosítsuk ennek megfelelően.
A következőkben az összes típusú szemétgyűjtő esetén (a valós idejű és a távoli kivételével) megnézzük, hogy milyen bejegyzéseket írnak a logba és azokat hogyan értelmezzük (Java 8 esetén). A logokat az alábbi példaprogram futtatásával próbáltam kicsikarni. A kód elindít két job-ot minden 100 ezredmásodpercben. Mindkét job adott élettartammal emulál objektumokat: létrehozza, hagyja őket élni egy adott ideig, aztán megfeledkezik róluk, lehetővé téve, hogy a GC felszabadítsa a memóriát.
package hu.egalizer.gctest; import java.util.ArrayDeque; import java.util.Deque; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class GcTester implements Runnable { private static ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2); private Deque<byte[]> deque; private int objectSize; private int queueSize; public GcTester(int objectSize, int ttl) { this.deque = new ArrayDeque<byte[]>(); this.objectSize = objectSize; this.queueSize = ttl * 1000; } @Override public void run() { for (int i = 0; i < 100; i++) { deque.add(new byte[objectSize]); if (deque.size() > queueSize) { deque.poll(); } } } public static void main(String[] args) throws InterruptedException { executorService.scheduleAtFixedRate(new GcTester(200 * 1024 * 1024 / 1000, 5), 0, 100, TimeUnit.MILLISECONDS); executorService.scheduleAtFixedRate(new GcTester(50 * 1024 * 1024 / 1000, 120), 0, 100, TimeUnit.MILLISECONDS); TimeUnit.MINUTES.sleep(10); executorService.shutdownNow(); } }
A logokhoz a JVM-et az alábbi paraméterekkel kell indítani: -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
Egy GC log részlet nagyjából a következőképp néz ki (a példaprogramot -Xmx512m paraméterrel futtatva):
2017-09-05T22:16:44.677+0200: 1.581: [GC (Allocation Failure) 2017-09-05T22:16:44.678+0200: 1.581: [DefNew: 139765K->17429K(157248K), 0.0936400 secs] 362075K->361613K(506816K), 0.0937556 secs] [Times: user=0.08 sys=0.02, real=0.09 secs] 2017-09-05T22:16:45.177+0200: 2.081: [GC (Allocation Failure) 2017-09-05T22:16:45.177+0200: 2.081: [DefNew: 157184K->157184K(157248K), 0.0000394 secs]2017-09-05T22:16:45.177+0200: 2.081: [Tenured: 344183K->349561K(349568K), 0.0605620 secs] 501368K->500745K(506816K), [Metaspace: 2831K->2831K(1056768K)], 0.0607333 secs] [Times: user=0.06 sys=0.00, real=0.06 secs] 2017-09-05T22:16:45.239+0200: 2.142: [Full GC (Allocation Failure) 2017-09-05T22:16:45.239+0200: 2.142: [Tenured: 349561K->349547K(349568K), 0.0450676 secs] 506685K->506671K(506816K), [Metaspace: 2831K->2831K(1056768K)], 0.0451294 secs] [Times: user=0.05 sys=0.00, real=0.04 secs]
Minor GC
Ebből nézzük az első sort részletesen:
2017-09-05T22:16:44.677+02001: 1.5812: [GC3 (Allocation Failure4) 2017-09-05T22:16:44.678+0200:
1.581: [DefNew5: 139765K->17429K6(157248K)7, 0.0936400 secs] 362075K->361613K8(506816K)9,
0.0937556 secs10] [Times: user=0.08 sys=0.02, real=0.09 secs]11
Most már látjuk, mi történik egy serial minor GC esetén a heap-en. A szemétgyűjtés előtt a heap kihasználtsága 362075 KB volt. Ebből a young generáció megevett 139765 KB-ot, az old generáció pedig ebből kiszámolható: 222310 KB volt. Egy ennél is fontosabb információ a következő számcsoportból látható: miután a szemétgyűjtés lement, a young generáció használata 122336 KB-tal csökkent, de a teljes heap csak 462 KB-tal. Ebből ki tudjuk számolni, hogy 121874 KB objektum promotálódott a young generációból az old-ba.
Full GC
A következő két sor tartalmazza a Full GC információit. Első látásra itt egy kis zavar van, mert a Full GC sor csak a tenured területtel és a metaspace-szel foglalkozik. Akkor mitől Full GC? Nos valójában a Full GC be van ágyazva egy minor GC-be. Amikor egy minor GC sikertelen lesz (mint itt a második sorban), akkor az átvált egy Full GC-be és amikor az lefut, akkor számít a szemétgyűjtés sikeresnek. Ez történik ebben a két sorban. Ha a programot -XX:+PrintGCDetails helyett -XX:+PrintGC parancssori opcióval futtatjuk, akkor a második sor meg sem jelenik a logban, csak a harmadik, amely a Full GC-ről tudósít. Lássuk mi történt ebben az esetben:
2017-09-05T22:16:45.177+0200: 2.0811: [GC (Allocation Failure) 2017-09-05T22:16:45.177+0200: 2.081:
[DefNew: 157184K->157184K(157248K), 0.0000394 secs2]2017-09-05T22:16:45.177+0200: 2.081:
[Tenured3: 344183K->349561K4(349568K)5, 0.0605620 secs6] 501368K->500745K7(506816K8),
[Metaspace: 2831K->2831K(1056768K)9], 0.0607333 secs]
[Times: user=0.06 sys=0.00, real=0.06 secs10]
A logból látszik, hogy a full GC ellenére sem sikerült a heap foglaltságát jelentősen csökkenteni ebben az esetben.
A példaprogramot -XX:+UseParallelOldGC paraméterrel futtatva lássuk most a párhuzamos szemétgyűjtés jellemző logbejegyzéseit:
2017-09-06T12:49:58.309+0200: 6.261: [GC (Allocation Failure) [PSYoungGen: 93696K->40424K(134144K)] 313695K->312615K(483840K), 0.0195111 secs] [Times: user=0.05 sys=0.00, real=0.02 secs] 2017-09-06T12:49:58.329+0200: 6.281: [Full GC (Ergonomics) [PSYoungGen: 40424K->0K(134144K)] [ParOldGen: 272191K->312551K(349696K)] 312615K->312551K(483840K), [Metaspace: 2836K->2836K(1056768K)], 0.0291154 secs] [Times: user=0.11 sys=0.00, real=0.03 secs]
Minor GC
Ebből nézzük az első sort részletesen:
2017-09-06T12:49:58.309+0200: 6.2611: [GC2 (Allocation Failure3) [PSYoungGen4: 93696K->40424K5
(134144K6)] 313695K->312615K7(483840K8), 0.0195111 secs9]
[Times: user=0.05 sys=0.00, real=0.02 secs]10
Röviden tehát a gyűjtés előtt 313695 KB volt lefoglalva a heap-ből. Ebből a young generáció 134144 KB. Ez azt jelenti, hogy az old generáció 179551 KB volt. A szemétgyűjtő után a young generáció használata csökkent 53272 KB-tal, de a teljes heap használat csak 1080 KB-tal csökkent, vagyis 52192 KB promotálódott a young generációból az old generációba.
Full GC
2017-09-06T12:49:58.329+0200: 6.2811: [Full GC2 (Ergonomics3) [PSYoungGen: 40424K->0K(134144K)]4
[ParOldGen5: 272191K->312551K6(349696K7)] 312615K->312551K8(483840K9),
[Metaspace: 2836K->2836K(1056768K)]10, 0.0291154 secs11]
[Times: user=0.11 sys=0.00, real=0.03 secs]12
A példaprogramot -XX:+UseConcMarkSweepGC paraméterrel futtatva lássuk most a CMS szemétgyűjtés jellemző logbejegyzéseit:
2017-09-06T21:26:40.870+0200: 1.453: [GC (Allocation Failure) 2017-09-06T21:26:40.870+0200: 1.453: [ParNew: 39239K->4303K(39296K), 0.0354605 secs] 312408K->311387K(388864K), 0.0355703 secs] [Times: user=0.03 sys=0.09, real=0.04 secs] 2017-09-06T21:26:41.074+0200: 1.657: [GC (Allocation Failure) 2017-09-06T21:26:41.074+0200: 1.657: [ParNew: 39084K->39084K(39296K), 0.0000602 secs]2017-09-06T21:26:41.075+0200: 1.657: [CMS: 341794K->349365K(349568K), 0.0948730 secs] 380879K->380704K(388864K), [Metaspace: 2831K->2831K(1056768K)], 0.0975661 secs] [Times: user=0.09 sys=0.00, real=0.10 secs] 2017-09-06T21:26:41.172+0200: 1.754: [GC (CMS Initial Mark) [1 CMS-initial-mark: 349365K(349568K)] 383368K(506816K), 0.0001412 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.172+0200: 1.755: [CMS-concurrent-mark-start] 2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-mark: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-preclean-start] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean-start] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.176+0200: 1.759: [GC (CMS Final Remark) [YG occupancy: 48992 K (157248 K)]2017-09-06T21:26:41.176+0200: 1.759: [Rescan (parallel) , 0.0002084 secs]2017-09-06T21:26:41.177+0200: 1.759: [weak refs processing, 0.0000179 secs]2017-09-06T21:26:41.177+0200: 1.759: [class unloading, 0.0001895 secs]2017-09-06T21:26:41.177+0200: 1.759: [scrub symbol table, 0.0003631 secs]2017-09-06T21:26:41.177+0200: 1.760: [scrub string table, 0.0000810 secs][1 CMS-remark: 349365K(349568K)] 398357K(506816K), 0.0009036 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.177+0200: 1.760: [CMS-concurrent-sweep-start] 2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-reset-start] 2017-09-06T21:26:41.178+0200: 1.761: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Minor GC
2017-09-06T21:26:40.870+0200: 1.4531: [GC2 (Allocation Failure3)
2017-09-06T21:26:40.870+0200: 1.453: [ParNew4: 39239K->4303K5(39296K6), 0.0354605 secs7]
312408K->311387K8(388864K9), 0.0355703 secs10] [Times: user=0.03 sys=0.09, real=0.04 secs]11
A fentiekből látható, hogy a szemétgyűjtés előtt a teljes felhasznált heap 312408 KB volt, ebből a young generáció 39239 KB. Ez azt jelenti, hogy az old generáció mérete 273169 KB volt. A szemétgyűjtő után a young generáció használata csökkent 34936 KB-tal, de a teljes heap használata csak 1021 KB-tal. Ez azt jelenti, hogy 33915 KB promotálódott a young generációból az oldba.
Full GC
Most hogy már belejöttünk a GC logok olvasásába, jöjjön egy némileg eltérő formájú log, csak hogy ne legyen minden olyan egyszerű. Az alábbiakban az old generációs CMS hosszú logja látható. Ezen is sorról sorra végig megyünk, viszont most nem nézzük át egyszerre a teljes logot, hanem részletekben haladunk, hogy lássuk a CMS fázisait. A teljes bejegyzés mindenesetre a következőképp néz ki:
2017-09-06T21:26:41.172+0200: 1.754: [GC (CMS Initial Mark) [1 CMS-initial-mark: 349365K(349568K)] 383368K(506816K), 0.0001412 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.172+0200: 1.755: [CMS-concurrent-mark-start] 2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-mark: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-preclean-start] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean-start] 2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.176+0200: 1.759: [GC (CMS Final Remark) [YG occupancy: 48992 K (157248 K)]2017-09-06T21:26:41.176+0200: 1.759: [Rescan (parallel) , 0.0002084 secs]2017-09-06T21:26:41.177+0200: 1.759: [weak refs processing, 0.0000179 secs]2017-09-06T21:26:41.177+0200: 1.759: [class unloading, 0.0001895 secs]2017-09-06T21:26:41.177+0200: 1.759: [scrub symbol table, 0.0003631 secs]2017-09-06T21:26:41.177+0200: 1.760: [scrub string table, 0.0000810 secs][1 CMS-remark: 349365K(349568K)] 398357K(506816K), 0.0009036 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.177+0200: 1.760: [CMS-concurrent-sweep-start] 2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-reset-start] 2017-09-06T21:26:41.178+0200: 1.761: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Azt se feledjük el, hogy young generációs minor GC-k az old generáció konkurens fázisai közben bármikor elindulhatnak. Ez esetben az alábbi eseményeket itt-ott megszakítják az előző fejezetben látott minor GC-k.
1. fázis: initial mark: az első teljes megállási esemény. Az old generáció összes olyan objektumának megjelölése, ami vagy közvetlen GC root vagy pedig a young generációról van hivatkozva.
2017-09-06T21:26:41.172+0200: 1.7541: [GC (CMS Initial Mark2) [1 CMS-initial-mark: 349365K3(349568K4)]
383368K5(506816K6), 0.0001412 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]7
2. fázis: concurrent mark: az old generáció átvizsgálása és az összes élő objektum megjelölése a korábban megjelöltekből kiindulva. Mivel ez a fázis konkurens és az alkalmazás menet közben módosíthatja az objektumokat, ezért itt nem biztos, hogy a menet végére minden élő objektum meg lesz jelölve.
2017-09-06T21:26:41.172+0200: 1.755: [CMS-concurrent-mark-start]
2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-mark1: 0.003/0.003 secs2]
[Times: user=0.00 sys=0.00, real=0.00 secs]3
3. fázis: concurrent preclean: míg a korábbi fázis futott, néhány referenciát az alkalmazás megváltoztatott. Amikor ez történt, a JVM megjelölte az ahhoz tartozó kártyát piszkosra. Ebben a fázisban a piszkos kártyákon lévő objektumokon megy végig a GC és az azokból elérhető további objektumokat is feldolgozza. A kártyákat ezután helyreállítja és ezen kívül némi egyéb háztartási munkát is megcsinál.
2017-09-06T21:26:41.175+0200: 1.757: [CMS-concurrent-preclean-start]
2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-preclean1: 0.001/0.001 secs2]
[Times: user=0.00 sys=0.00, real=0.00 secs]3
4. fázis: concurrent abortable preclean: az utolsó konkurens fázis. Megpróbál még annyi munkát levenni a teljes megállási esemény alatt munkálkodó final remark válláról, amennyit lehet. A fázis időtartama nagyon sok szemponttól függ, mert egy ciklusban fut addig, amíg bizonyos feltételek nem teljesülnek (például elég iteráció lement már vagy elég hasznos munkát elvégzett, stb.). Ennek a fázisnak jelentős hatása van a következő teljes megállási eseményre.
2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean-start]
2017-09-06T21:26:41.176+0200: 1.759: [CMS-concurrent-abortable-preclean1: 0.000/0.000 secs2]
[Times: user=0.00 sys=0.00, real=0.00 secs]3
5. fázis: final remark: a második teljes megállási esemény. Az a feladata, hogy befejezze az old generáció élő objektumainak megjelölését. A CMS általában megpróbálja ezt a fázist akkor futtatni, amikor a young generáció a legüresebb. A log alapján ez egy picit összetettebb lépés, mint az eddigiek.
2017-09-06T21:26:41.176+0200: 1.7591: [GC (CMS Final Remark2) [YG occupancy: 48992 K (157248 K)]3
2017-09-06T21:26:41.176+0200: 1.759: [Rescan (parallel) , 0.0002084 secs]4
2017-09-06T21:26:41.177+0200: 1.759: [weak refs processing, 0.0000179 secs]5
2017-09-06T21:26:41.177+0200: 1.759: [class unloading, 0.0001895 secs]6
2017-09-06T21:26:41.177+0200: 1.759: [scrub symbol table, 0.0003631 secs]
2017-09-06T21:26:41.177+0200: 1.760: [scrub string table, 0.0000810 secs]7
[1 CMS-remark: 349365K(349568K)8]398357K(506816K)9, 0.0009036 secs10]
[Times: user=0.00 sys=0.00, real=0.00 secs]11
Az öt marking fázis után minden élő objektum meg lett jelölve és a GC most már kipucolhatja az old generációt.
6. fázis: concurrent sweep: a szemét eltávolítása az alkalmazás futásával párhuzamosan.
2017-09-06T21:26:41.177+0200: 1.760: [CMS-concurrent-sweep-start]
2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-sweep1: 0.000/0.000 secs2]
[Times: user=0.00 sys=0.00, real=0.00 secs]3
7. fázis: concurrent reset: a belső adatszerkezetek beállítása és felkészülés a következő CMS ciklusra.
2017-09-06T21:26:41.178+0200: 1.760: [CMS-concurrent-reset-start]
2017-09-06T21:26:41.178+0200: 1.761: [CMS-concurrent-reset1: 0.000/0.000 secs2]
[Times: user=0.00 sys=0.00, real=0.00 secs]3
Utolsóként vizsgáljuk meg a G1-gyel futtatott program logját: -XX:+UseG1GC
Evacuation pause: fully young
Az alkalmazás életciklusának kezdetén a G1-nek még nincs információja a korábban végrehajtott futásokból, ekkor még ún. fully young módban fut. Amikor a young generáció betelik, jön egy teljes megállási esemény és az éden régiókban lévő még élő objektumok átkerülnek (az esetlegesen újonnan létrehozott) survivor régiókba. Az evakuációs megállások teljes logja elég nagy, úgyhogy kihagytam néhány apróbb, itt most még lényegtelen részt belőle. Később majd ezekre részletesen rátérek.
2017-09-08T20:22:52.022+0200: 0.343: [GC pause (G1 Evacuation Pause) (young), 0.0048649 secs]1 [Parallel Time: 3.9 ms, GC Workers: 4]2 [...] [Code Root Fixup: 0.0 ms]3 [Code Root Purge: 0.0 ms]4 [Clear CT: 0.2 ms] [Other: 0.7 ms]5 [...] [Eden: 14.0M(14.0M)->0.0B(8192.0K)6 Survivors: 0.0B->2048.0K7 Heap: 14.0M(128.0M)->13.5M(128.0M)8] [Times: user=0.00 sys=0.05, real=0.02 secs]9
A munka nehezét több dedikált GC munkavégző szál (GC worker) végzi el. Ezek tevékenységére az alábbi logbejegyzésekben derül fény (a fenti logban az első kipontozott rész):
[Parallel Time: 3.9 ms, GC Workers: 4]1
[GC Worker Start (ms)2: Min: 343.0, Avg: 343.1, Max: 343.1, Diff: 0.0]
[Ext Root Scanning (ms)3: Min: 0.2, Avg: 0.3, Max: 0.3, Diff: 0.1, Sum: 1.0]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms)4: Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms)5: Min: 3.1, Avg: 3.2, Max: 3.3, Diff: 0.2, Sum: 12.9]
[Termination (ms)6: Min: 0.0, Avg: 0.2, Max: 0.3, Diff: 0.3, Sum: 0.9]
[Termination Attempts7: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms)8: Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms)9: Min: 3.6, Avg: 3.8, Max: 3.8, Diff: 0.2, Sum: 15.0]
[GC Worker End (ms)10: Min: 346.7, Avg: 346.8, Max: 346.9, Diff: 0.2]
Ezeken kívül van még némi egyéb munka is az evakuációs megállás során. Itt ennek csak egy részét nézzük át, a többiről később lesz szó. (A fenti logban a második kipontozott rész.)
[Other: 0.7 ms]1
[Choose CSet: 0.0 ms]
[Ref Proc: 0.5 ms]2
[Ref Enq: 0.0 ms]3
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]4
Concurrent marking
1. fázis: initial mark: megjelöli az összes, GC root-okból közvetlenü elérhető objektumot. Ezt a megállást a GC logban az (initial-mark) szöveg jelzi egy evakuációs megállás első sorában (figyeljük meg, hogy az előző példánál ez még nem szerepelt ott, az tisztán minor szemétgyűjtés volt, itt viszont a minor GC már kiegészül az initial mark fázissal):
2017-09-08T20:22:52.335+0200: 0.643: [GC pause (G1 Evacuation Pause) (young)
(initial-mark), 0.0189492 secs]
2. fázis: root region scan: root régiók átvizsgálása old generációkba mutató referenciák után (azokat meg is jelöli).
2017-09-08T20:22:52.351+0200: 0.663: [GC concurrent-root-region-scan-start] 2017-09-08T20:22:52.351+0200: 0.665: [GC concurrent-root-region-scan-end, 0.0023534 secs]
3. fázis: concurrent mark
2017-09-08T20:22:52.351+0200: 0.665: [GC concurrent-mark-start] 2017-09-08T20:22:52.351+0200: 0.669: [GC concurrent-mark-end, 0.0039860 secs]
4. fázis: remark: teljes megállási esemény (stop the world pause)
2017-09-08T20:22:52.351+0200: 0.670: [GC remark 2017-09-08T20:22:52.351+0200: 0.670:
[Finalize Marking, 0.0002606 secs] 2017-09-08T20:22:52.351+0200: 0.670:
[GC ref-proc, 0.0001265 secs] 2017-09-08T20:22:52.351+0200: 0.670:
[Unloading, 0.0014274 secs], 0.0028999 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
5. fázis: cleanup: megágyaz a következő evakuációs fázisnak. Beállítja az élő objektumokat nem tartalmazó régiókat. A fázis néhány része konkurens, mint például az üres régiók kezelése és az élőségi számítások nagy része, de a véglegesítéshez ennek is teljes megállási esemény kell.
2017-09-08T20:22:52.351+0200: 0.673: [GC cleanup 105M->105M(205M), 0.0004022 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Amikor olyan régiókat talál, amik csak szemetet tartalmaznak, a bejegyzés kicsit különbözik:
2017-09-08T20:22:52.351+0200: 0.673: [GC cleanup 105M->105M(205M), 0.0004022 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] 2017-09-08T20:22:52.444+0200: 0.766: [GC concurrent-cleanup-start] 2017-09-08T20:22:52.446+0200: 0.768: [GC concurrent-cleanup-end, 0.0014846 secs]
Evacuation pause: mixed
Az a legjobb, amikor a concurrent cleanup az old generációban teljes régiókat tud felszabadítani, de nem mindig ez a helyzet. Miután a concurrent marking sikeresen végetért, egy evakuációs megállás következik. Ennek egyik változata a mixed collection, ami nem csak a szemetet pucolja ki a young generációból, hanem egy csomó old régiót is betesz a collection set-ekbe. (A tisztán young generációs evakuációs megállást fentebb már láttuk.) Egy mixed evacuation pause nem mindig pontosan követi a concurrent marking fázist.
A logja néhány új dolgot is tartalmaz (a kipontozott részeket korábban már láttuk):
2017-09-08T20:22:52.976+0200: 1.284: [GC pause (G1 Evacuation Pause) (mixed), 0.0093513 secs]
[Parallel Time: 7.4 ms, GC Workers: 4]
[...]
[Update RS (ms)1: Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.0, Sum: 0.2]
[Processed Buffers2: Min: 1, Avg: 1.3, Max: 2, Diff: 1, Sum: 5]
[Scan RS (ms)3: Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[...]
[Clear CT: 0.3 ms]4
[Other: 1.7 ms]
[...]
[Redirty Cards: 0.4 ms]5
[...]
Immáron végeztünk a szemétgyűjtés technológiáinak áttekintésével, a GC-tuningolás mesterségéről ebben a cikkben már nem fogok mesélni. Viszont van még egy téma, ami ide kívánkozik. Mivel is lehetne befejezni egy GC-ről szóló cikket, ha nem a finalize()-zal?
A java.lang.Object osztály finalize() metódusáról a Java 7 API dokumentációja a következőt írja: "Called by the garbage collector on an object when garbage collection determines that there are no more references to the object."
A helyzet pofonegyszerűnek tűnik. A finalize()-t a GC meghívja, amikor eljött az ideje, vagyis úgy érzékeli, hogy az objektumra nem hivatkozik több (erős) referencia. Persze ha a helyzet tényleg iylen egyszerű lenne, akkor ez a fejezet sem született volna meg. Nézzünk először egy egyszerű példát:
public class FinalizeTest1 { static long NumberOfCreatedInstances = 0; static long NumberOfDeletedInstances = 0; public FinalizeTest1() { NumberOfCreatedInstances++; } static public void main(String args[]) { for (int i = 0;; i++) { FinalizeTest1 obj = new FinalizeTest1(); obj = null; if (i % 10000000 == 0) { System.out.println(NumberOfCreatedInstances - NumberOfDeletedInstances); } } } }
Ez a kis osztály nem implementál saját finalize() metódust, hogy később lássuk a különbséget. Ez egy egyszerű kis ciklus, ami csak példányosít és megszüntet hivatkozásokat a FinalizeTest1-re. Úgy fut, ahogy elvárható: csinál egy csomó szemetet, amit a szemétgyűjtő rendszeresen kipucol. Most módosítsuk egy kicsit az osztályt, hogy legyen finalize() implementációja!
public class FinalizeTest2 { static long NumberOfCreatedInstances = 0; static long NumberOfDeletedInstances = 0; public FinalizeTest2() { NumberOfCreatedInstances++; } protected void finalize() { NumberOfDeletedInstances++; } static public void main(String args[]) { for (int i = 0;; i++) { FinalizeTest2 obj = new FinalizeTest2(); obj = null; if (i % 10000000 == 0) { System.out.println(NumberOfCreatedInstances - NumberOfDeletedInstances); } } } }
Látszólag nincs sok különbség a két tesztosztály között, de ha lefuttatjuk GC logolást is bekapcsolva, akkor hatalmas különbséget látunk a két futás között. A FinalizeTest1 szépen nyugisan futogat; folyamatosan létrehozza az objektumokat, amit néha nagyon gyors young generációs GC megszakít, pont ahogy a kód alapján elvárnánk. A FinalizeTest2 viszont kegyetlenül lelassul (nem árt -Xmx64m vagy még kisebb heap mérettel indítani). 1.6 előtti JVM-nél pedig akár még OutOfMemory kivételt is dobhat (bár eltart egy darabig). Hacsak nincs tapasztalatunk korábbról a finalize() metódussal, akkor ez az eredmény meglepő lehet. Egy pár soros kis egyszerű kód teljesen megfektetni a JVM-et. De nézzük, mi is történik a háttérben!
Nézzük a FinalizeTest1-et. Egyszerű osztály egyszerű életciklussal. A main() metódusban a new FinalizeTest1() sor létrehozza az éden területen a FinalizeTest1 objektumot. A következő sorban jön a referencia törlése (obj=null;); ezzel az objektumhoz minden referencia törlődik. Egyébként ha az a sor nem lenne, a referencia törlése akkor is megtörténne a következő iterációban, amikor az obj a következő FinalizeTest1 példányra mutat majd, de jobb, ha ez a példa most ilyen egyértelmű.
Egyszercsak már elég FinalizeTest1 példányt hoztunk létre az éden területen, ami tele lesz. Ez kivált egy minor GC-t. Mivel semmi nem mutat az éden területen lévő objektumokra (vagy esetleg még egy, attól függően, hogy mikor indul el a GC), az édent nagyon hatékonyan üresre lehet állítani. Ha egy objektumra még van hivatkozás, az átmásolódik a survivor területre. Tehát nagyon gyorsan visszakerülünk egy üres édenhez és a fő ciklus folytatódhat további objektum létrehozással.
A FinalizeTest2 viszont máshogy néz ki. Először is amikor egy FinalizeTest2 példány létrejön, akkor a JVM látja, hogy van felüldefiniált finalize() metódusa, ami nem egyezik meg az Object-ével. Nemtriviális finalize() metódus létrehozása (vagy akár öröklése) egy osztályban már önmagában elegendő hozzá, hogy megváltoztassa az objektumok létrehozását. A JVM figyelmen kívül hagyja a triviális finalize() metódust (ami visszatér anélkül, hogy bármit csinálna, pont mint az Object-féle). Viszont ha egy példánynak nemtriviális finalize() metódusa van vagy öröklött egyet, akkor a JVM a következőt csinálja:
Tehát minden létrehozott FinalizeTest2 példány esetén kapunk egy különálló java.lang.ref.Finalizer példányt is, ami a FinalizeTest2 példányra mutat. Ez ennyire durva lenne? Hát nem igazán. Jó persze egy objektum helyett kettőt hozunk létre, de hát láttuk, hogy a modern JVM-ek csudamód hatékonyak az objektumok létrehozásában, tehát ez nem nagy ügy.
Az első GC
Mi következik ezután? Pont mint korábban, a FinalizeTest2 példányokra hivatkozó referencia megszűnik, tehát ki lehet őket pucolni. Ez az éden betelésekor lesz amikor jön egy minor GC. Ez esetben viszont a GC-nek van extra tennivalója. Először is egy csomó nem hivatkozott objektum helyett immár egy csomó, a Finalizer objektumok által hivatkozott objektumunk van. Arra meg a Finalizer osztály hivatkozik. Vagyis minden életben maradt! A GC átmásol mindent a survivor területre. De ha az nem elég nagy, hogy az összes objektumot befogadja, akkor néhány átkerül az old generációba (aminek költségesebb a GC ciklusa is). Egyből sokkal több munkánk van és ráadásul még egy csomó dolog lesz ezután is. Itt ugyanis még nincs vége! Mivel a GC felismeri, hogy semmi más nem mutat a FinalizeTest2 objektumokra a Finalizer példányokon kívül, azt mondja magában, hogy aha, bármely FinalizeTest2 példányra mutató Finalizer-t fel tudom dolgozni! Így aztán mindegyik Finalizer objektumot hozzáadja a java.lang.ref.Finalizer.ReferenceQueue sorhoz. Most már végzett és láthatóan több munkát csinált, mint amíg nem voltak Finalizer-jeink. És nézzünk rá a heap-ünkre: FinalizeTest2 példányok lézengenek benne: kitöltik a survivor területet és még az old generációban is vannak. Emellett Finalizer példányok is lófrálnak, amiket még mindig használ a Finalizer osztály. A GC végetért és semmi se lett kitakarítva!
A Finalizer szál
Most, hogy a minor GC végetért, a teljes megállási esemény befejeződik és az alkalmazás szála folytatódik. A java.lang.ref.Finalizer osztályban van egy belső osztály, amit FinalizerThread-nek hívnak és ez indítja el a Finalizer démon szálat, amikor a JVM betölti a java.lang.ref.Finalizer osztályt. Ezt a démon szálat egy monitorozó programmal láthatjuk is a JVM-ben. Ez a Finalizer démon szál egyébként meglehetősen egyszerű. Egy ciklusban dolgozik, ami arra vár, hogy valamit találjon a java.lang.ref.Finalizer.ReferenceQueue sorban. Az alábbi kódrészlethez hasonlóan (a valódi kód ennél picit bonyolultabb, mert néhány hibakezelési és elérési problémával is foglalkozik):
for(;;)
{
Finalizer f = java.lang.ref.Finalizer.ReferenceQueue.remove();
f.get().finalize();
}
A ciklus most sokkal több FinalizeTest2 példányt csinál a hozzájuk csatolt Finalizer objektumokkal, mialatt a Finalizer démon szál átfut a Finalizer objektumokon, amiket a korábbi GC rakott a referenciasorba. Ezzel még nem lehetne probléma, hiszen a mi FinalizeTest2.finalize() metódusunknak gyorsabbnak kellene lenni, mint egy új FinalizeTest2 példány létrehozásának, tehát azt várjuk, hogy képes lesz gyorsan lefutni. Van azonban egy kis probléma ezzel az optimista elvárással. A Finalizer démon szálat az alapértelmezettnél alacsonyabb prioritással futtatja a JVM. Ez pedig azt jelenti, hogy a main szál sokkal több processzoridőt kap, mint a Finalizer démon szál, tehát a FinalizeTest2 esetén az sosem fogja utolérni a main-t.
Normál alkalmazásoknál ez a kiegyensúlyozatlanság persze általában nem számít. A nemtriviális finalize()-zal rendelkező objektumokat nem hozzák létre ilyen nagy számban vagy ha mégis, akkor is csomagokban. Az átlagos alkalmazásnak tehát lesz processzorideje, hogy a Finalizer démon szál utolérje magát. A mi alattomos kis tesztprogramunk viszont túl gyorsan hozza létre a Finalizer démon szálnak feldolgozandó objektumokat és így a Finalizer referenciasor folyamatosan növekvő marad.
A második GC
Néhány Finalizer objektum azért persze kikerül a sorból és meghívódik az általuk hivatkozott FinalizeTest2 példányok finalize() metódusa. Ezen a ponton a Finalizer démon szál még egy kis plusz munkát is csinál: eltávolítja a feldolgozott Finalizer példányra mutató referenciát a Finalizer sorból. Emlékezzünk rá, hogy ez tartotta életben a Finalizer példányt! Most már semmi sem mutat arra a Finalizer példányra és a következő GC ki tudja dobni - ahogy immár a FinalizeTest2 példányt is. Egy újabb szemétgyűjtéskor a feldolgozott Finalizer objektumok ki lesznek pucolva. A többi, ami még mindig a Finalizer sorban van, ide-oda másolódik a survivor területeken, egy részük közben megint feldolgozódik és kipucolódik, de a legtöbb (a mi FinalizeTest2 alkalmazásunkban) végül az old generációban köt ki. Végül az old generáció is tele lesz és elindul egy major GC. Bár az képes kicsit többet kipucolni, már nem sokat segít - most már látjuk, hogyan érjük el az OutOfMemoryError kivételt. Az a sor folyamatosan csak nő és végül nem lesz elég hely, hogy új objektumokat létrehozzunk. (Elképzelhető olyan JVM és konfiguráció (a 7-es a jelek szerint ilyen), ahol a szemétgyűjtő elég okos, hogy képes legyen felismerni a helyzetet és egy kicsit tovább hagyja futni a Finalizer szálat, így a végtelenségig tudunk futni majdnem teljes heap-pel.)
Végszó
Most már láttuk, hogyan dolgozódnak fel a finalize()-t használó objektumok. A példa persze szándékosan ilyen volt, de legalább jól demonstrálta, hogy mi történik drámai esetben. Való életben azért azért legtöbbször nem ilyen rossz a helyzet. Megoldásként persze lehetne emelni a Finalizer démon szál prioritását, de erre nincs API, tehát kézzel kell megtenni.
A problémára egyébként a fantom referenciák is megoldást kínálnak. A finalize() kezelését ezzel teljesen átveheti az alkalmazásunk és mivel a PhantomReference nem használható egy objektum újrafelhasználására, az objektumot azonnal ki lehet pucolni már az első szemétgyűjtési ciklusban, amikor az már csak fantom referenciaként érhető el. Ezután pedig saját hatáskörben felszabadíthatunk olyan erőforrást, amit csak akarunk. A finalize() metódust igazából nem is nagyon kellene használni. A PhantomReference tisztább, szárazabb, biztonságosabb érzést ad. (Egyébként talán egyetlen értelmes érv van a finalize() használatára: amikor valamilyen erőforrást expliciten le kell, hogy zárjon a program, akkor az erőforrás finalize() metódusában meg tudjuk vizsgálni, hogy ezt megtette-e és ha nem, akkor tudunk hibalogot dobni a hiányról, vagyis hogy a program elfelejtette meghívni a close()-t.)
És ha már itt tartunk, nézzük, mi szól a finalize() használata ellen:
Referencia sorral azonban a fenti problémák egy része kiküszöbölhető.