
Lépni kell. Fejlődni kell. És ezt bizony az operációs rendszerek kernelei sem kerülhetik el (egykönnyen). A monolitikus struktúra több, mint 32 éve uralja az operációs rendszerek birodalmát. Az utóbb 8-16 évben már történtek kísérletek a továbblépésre (Mach, Exokernel), de eddig még senki sem tudott felmutatni jelentős eredményt. Kivéve talán egy-két rendszert: ilyen többek között a BeOS, QNX és az L4. Érdeklődésem középpontjába az L4 került, mivel fejlesztői teljesen felforgatták az eddig elméleteket és a forráskódját is felszabadították. A szabad rendszerek zászlóshajója, a "talán egyszer majd elkészülő" GNU HURD is nemrég rávetette magát az L4-re, talán azért is kapták fel ilyen hirtelen...
A monolitikus szervezési modell az egyik legrégebbi elv az operációs rendszerek kernelei megvalósításában. Mint tudjuk, a kernel feladata az operációs rendszeren belül a legfontosabb: talán ezért is fordulhatott elő, hogy adódtak olyan rendszerek is az évek folyamán, amik öntörvényűen a kernelről nevezték el magukat.
Mi is a kernel feladata? Rengeteg dolgot kell szolgáltatnia egy mai monolitikus felépítésű kernelnek, például ő ismeri az operációs rendszer által támogatott összes állományrendszert (file system - fs), hardverelemet (az eszközmeghajtókon keresztül), az ütemezési algoritmusokat, a kommunikációs lehetőségeket. Számos dolog tartozik tehát egy kernel hatáskörébe, de ez már nevében is benne van, hiszen ezért nevezzük monolitikusnak. Ennek ellenére egy kernel még nem operációs rendszer, hiszen hiányoznak belőle azok a lehetőségeket, amelyek segítségével például magával a felhasználóval képes kapcsolatot teremteni. Kompetens módon nem képes alkalmazások lefordítására sem, és magától szinte semmire sem. Irányításra van szüksége. Mint az elején is említettem, ez egy nagyon régóta méglévő elképzelés (tehát mindent egyetlen állományba kell csoportosítani), és közel harminc éves uralomra tekint vissza. (Az első UNIX rendszerek megszületésétől egészen napjaink UNIX-áig: *BSD, Linux, stb.)
Röviden nézzük meg, milyen előnyökkel jár, ha valaki ilyen típusú rendszert fejleszt:
Ha ezek alapján tekintjük a Linux 2.4.18-as verziójának forrásszövegét, akkor az kb. összesen 2,7 millió sorból áll. Ebbe természetesen beleértendők a különböző meghajtóprogramok, az összes komponens (állományrendszerek, memóriakezelés, ütemezés, üzenetek, I/O) forrása. De ez mind hozzátartozik ahhoz a méretes tar.gz vagy éppen tar.bz2 file-hoz (~15-20 MB), amit egy ilyen kernel frissítésekor letöltünk.
A monolitikus rendszerek természetesen a korral azért fejlődtek is, hiszen kialakultak alverziói, amelyek bizonyos más rendezési elveknek megfelelően egy alstruktúrát is létrehoztak:
Miután már nagyjából tudjuk, hogyan néz ki egy "átlagos" rendszer (azért tegyük hozzá, hogy az IBM AIX rendszere, ill. egy másik nagyon ismert cég sorozata már (valamennyire) mikrokerneles szerkezetű!), feltehetnénk a kérdést, hogy miért van szükség erre a kavarásra, miért kell felrúgni több évtizedes, bevált módszereket. Nos, a legegyszerűbb válasz talán az lenne, hogy az informatika hihetetlenül dinamikus "iparág", és még rengeteg fejlesztenivaló fekszik benne; és vannak olyan emberek, akik ebben látják a fejlődést.
Akármennyire is tűnik egy ilyen rendszer kényelmesen kódolhatónak és gyorsnak (mondjuk, gyors is), számos (néha igenis létfontosságú) dolog még mindig hiányzik egy monolitikus kernelből:
Nyilván ki lehetett találni, hogy a modern mikrokernelek a fenti kritériumoknak megfelelnek, de mégsem annyira elterjedtek - bár napjainkban már létezik egy feltörekvő változatuk, illetve kereskedelemben is kaphatóak (mint pl. a QNX). Egyetlen hátrányuk van, hogy lassúak (egy monolitikus rendszerhez képest, majd meglátjuk, miért), de az utóbbi időben már sikerült ezt a korlátot is az 5%-os határ alá szorítani (mindenféle kernelen kívüli specializáció nélkül!).
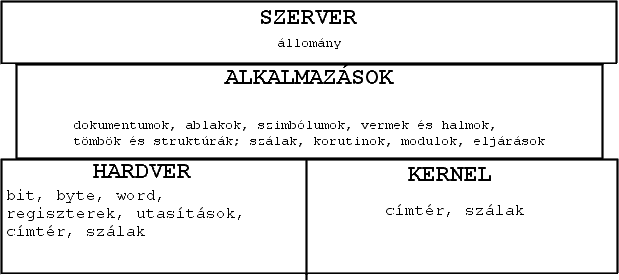
Mint ahogy láthatjuk is, a mikrokernel sokkal kevesebb komponenst tartalmaz. Az elnevezés is innen származik, nem pedig a méretéből, hiszen az ettől független (bár többnyire kisebb is, mint monolitikus társai). Így a benne elérhető szolgáltatások száma is sokkal kevesebb, pl. a L4-es mikrokernelben csak 7(!) rendszerhívás van (szemben a monolitikus kernelek talán százas(?) nagyságrendjével).
Az ábrán egy új elem is megjelenik, a szerver: ez adja a mikrokernelek tényleges funkcionalitását, egy szerver tesz lehetővé egy felhasználó is elérhető funkciót (pl. FAT32 típusú állományrendszer elérése), amely úgy működik akár egy normális UNIX folyamat: elindítható, leállítható, vagy akár újra is indítható. Ezekben (a mikrokernel kevés funkciója és a szerverek alkalmazása) rejlik az igazi erő és lehetőség: a monolitikus kerneleknél "bedrótozottnak tekinhető" rendszerhívások bármelyike helyettesíthető egy-egy szerverrel, pl. a még a memóriakezelés is (egy ún. "memóriaszerverrel").
Ezek a szerverek párhuzamosan futnak egymás mellett, mint folyamatok. Az egész mikrokerneles filozófiát tekinthetjük OO-nak is: ha a szervereket objektumoknak tekintjük, amelyek üzenetekkel kommunikálnak egymással. Ez a legkézenfekvőbb módszer, hiszen a szerverek nincsenek programozási nyelvhez kötve, csupán egyetlen dologra, az ún. interfészre kell figyelnünk (hiszen enélkül nem lehetséges a kommunikáció).
Az interfészek esetében viszont van egy óriási segítsége a programozónak, amit a Mach tervezőinek köszönhetünk: ez az interfész generátor. Ez nem más, mint egy "előfordító", amely a megírt programba behelyettesíti a tényleges struktúrákat és függvényeket, amelyek elengedhetetlenül szükségesek. Sőt, ennek továbbfejlesztett változata az L4-ben alkalmazott (ill. a utahi Flux Research Group által is kutatott) IDL (Interface Definition Language), amely a szerverek írását tovább egyszerűsíti; szinte gyerekjáték elkészíteni vele egy mikrokerneles rendszert.
Igen, a mikrokerneles rendszerek másik előnye, hogy ha valaki készíteni akar egy operációs rendszert, akkor rengeteg dolgot meg kell írni (de talán feleslegesen, hiszen vagy léteznek már jobb implementációk, vagy pedig nincs is tisztában, hogyan kellene kódolni az adott komponenst), a betöltésért felelős rutinoktól (ebben azért sokat segít egy jó "boot loader" is, mint pl. a GRUB) kezdve egészen a virtuális memória kezeléséig.
Ezt régebben úgy oldották meg, hogy létrehoztak egy OSKit (Utahi Egyetem) nevű programcsomagot, amely tartalmazta a legalapvetőbb rendszerkomponenseket (ezeket glue-nak, vagyis "tapasznak" nevezte) a különböző rendszerekből összeollózva. A célja az volt, hogy megkönnyítse az új operációs rendszerek fejlesztését: a fejlesztőknek kizárólag csak a lényegre kelljen koncentrálniuk; ne vesszenek el a részletekben. Tetszőlegesen le lehet cserélni azt a komponenst, amelyiket újra akarjuk implementálni, vagy pedig bővíthetjük a rendszer a saját "találmányainkkal".
Nos, a Mach is erősen kihasználta az OSKit nyújtotta lehetőségeket, talán ezért is lett ilyen robusztus. Viszont ha egy idealizált rendszert veszünk (a rendkívül kicsi és kizárólag csak a lényeget tartalmazó L4-et), akkor az lényegében fel tudja vállalni egyfajta "OSKit-szerű" funkciót, hiszen ha azt vesszük, kapunk egy mikrokernelt, és minden komponensre egy-egy szervert (amennyiben az ún. többszerveres megoldást alkalmazzuk). Amelyiket újra akarjuk implementálni, az egyszerűen lecseréljük, és mindenféle újraindítás nélkül kísérletezhetünk(!) pl. egy saját memóriakezelő megírásával. Sőt, a jövőben talán lehetőségünk nyílik ezen komponensek futás idejű nyomkövetésére is! (A GNU HURD rendszere elméleti síkon ezt a lehetőséget már támogatja, ill. implementálta is a nemrég eldobott GNUMach-alapú sorozatban.) (Természetesen nem kell sajnálni a monolitikus rendszerek fejlesztőit sem, hiszen a modern számítógépek teljesítmények növekedésének köszönhetően már szinte mindegyiket virtuális gépek alatt tesztelik, tehát mostanság már nekik sem kell újraindítani a rendszert...)
Hogy továbbra is az OO-nál maradjunk, kifejtem az üzenetek fontosságát is. Mint korábban említettem, a szerverek üzenetekkel kommunikálnak egymással. Hozzá kell tenni, hogy igazából ezt üzenetváltásnak kellene nevezni, hiszen ekkor mindig két üzenet keletkezik: az egyiket a küldő adja át a címzettnek (mondjuk egy szerver-kliens modellben, tehát erre is utal a szerver elnevezés!), ez lenne lényegében pl. egy esemény jelzése ("Megszakítás történt!"), vagy pedig egy kérés ("Foglalj nekem 100 KB memóriát!"); a másik üzenet ennek megerősítése, tehát egy visszajelzés arról, hogy a címzett megkapta az üzenetet. Ez mindenképpen fontos, mert csak akkor "vehetünk komolyan" egy üzenetet, ha az meg van erősítve! Ennek igazából nem is lenne jelentősége, ha mondjuk egyetlen számítógépen futna az összes folyamat, hiszen egy ilyen inkonzisztenciát okozó hardver- vagy szoftverhiba valószínűsége igen csekély (vagy bekövetkezésekor maga a kernel is "borulna"). De mivel a szabály az szabály, ezért kötelező még ekkor is válaszolni (sok esetben ez a folyamatok közötti szinkronizációt is szolgálja).
Ellenben hihetetlenül fontos szerepe van egy ilyen válasznak abban az esetben, ha mondjuk a rendszer funkciónak nem egyetlen processzoron, esetleg nem is egyetlen számítógépen futnak! Ez már az osztott rendszerek témakörébe kalauzol minket (ld. A.S. Tannenbaum Amoeba-ja, szerepel a történeti áttekintésben is), de korántsem áll messze a mikrokernelektől. Hiszen ezáltal a szervereket mindenféle külön támogatás nélkül valós időben is párhuzamosan futatthatjuk; egyedül magának a mikrokernelnek kell támogatnia a több processzor megfelelő kezelését, ill. a hálózatot. Meglepő, de ez az "emberi szemléletmód" sokkal jobban definiálhatóbbá, jobban bővíthetőbbé teszi a mikrokerneleken alapuló rendszereket. A lehetőségek (egyelőre) határtalanok: még rengeteg kiaknázandó fegyvertényt rejt magában egy ilyen rendszer. De példák már léteznek:
Az API-k és személyiségek támogatásával megszűnik egy másik probléma is, amely napjaink operációs rendszereinek fejlődését akadályozza: ez az alkalmazások hiánya. Ha egy rendszer nem kap elegendő támogatást (tehát nem jelenik meg rá kellő számú felhasználói program), akkor szinte áshatja is a saját sírját, hiszen a kutya sem fogja használni, legfeljebb egy-két megszállott hacker. Az előbbi eszközökkel viszont áthidalható a probléma, mert nem kell megvárni a "honosított" alkalmazásokat, illetve a rendszer sincs kötelezve saját bináris formátum használatára (ami szintén időt vesz a tervezésből és a fejlesztésből).
Jelenleg a mikrokernelek második generációja van fejlesztés alatt, de röviden nézzük is át, milyen elődökön keresztül vezetett az út; ezek az elődök milyen újításokkal voltak felszerelve.
MACH: a Carnegie-Mellon University (CMU) és az Open Source Foundation (OSF) által fejlesztett kernel. Talán ez tekinhető az első (működő) mikrokernelnek, ami a Kaliforniai Egyetem (UC) Berkeley-ben házaló Computer Systems Research Group által kifejlesztett és megalapozott BSD architektúrából építkezik. Erre később próbáltak is építeni egy BSD-típusú rendszert, amelyet Lites-nek neveznek (napjainkban pedig egy új, open source változat is készülget, az xMach; bár jelen pillanatban nem érhető el a website-juk).
Annak ellenére, hogy robusztus kernelről van szó (igazából, mint első nekifutásként egy monolitikus kernel leszűkítése), még most is használják a 4-es verzióját (ezt viszont Utahban fejlesztik), és többek között a FSF (Free Software Foundation) is elkészítette a saját Mach4 implementációját, GNUMach néven (sajnos az 1.3-as verziónál abbamaradt a fejlesztés- őszintén megvallva jobb is, mert a "sima" Mach4-nél is kuszább lett a kódja, mert tartalmazta a Linux 2.0-ban előforduló meghajtók igen nagy részét, főleg a hálókártyákét; amitől nem lett feltétlenül "fitt").
Elméleti jelentősége ott van, hogy a Mach alkalmazta először a külső lapozó (external pager) elvét (vagyis lényegében a rendszerben menet közben is variálható memóriakezelést);
CHORUS: a Sun saját mikrokerneles szárnypróbálgatása, Inria Chorus nevéhez fűződik, a Machhal együtt az első kereskedelmi mikrokernelek egyike;
AMOEBA: a Vrjje Universiteit (Hollandia) által fejlesztett mikrokernel. Maga Andrew S. Tannenbaum professzor áll a hátterében, mint az korábban is írtam, fő elméleti jelentősége az elosztott rendszerekben van, és a forráskódja is elérhető a szerző honlapjáról;
L3: a szintén emlegetett L4 elődje, a GMD (German National Research Center for Information Technology) fejlesztette ki. Elméleti jelentősége a felhasználó szintű meghajtók (User Level Driver) alkalmazásában van;
SPIN: a Washingtoni Egyetem (UW) fejlesztette ki, itt szintén megfordul a külső lapozás lehetősége, és saját kernelfordítóval rendelkezik, amely lehetővé teszi, hogy a felhasználó által javasolt algoritmusokat be tudjuk építeni a rendszerbe: tehát egy átlagos felhasználó is képes rendszerhívásokat írni. Az ágak és a memóriahivatkozások felügyeletével a kernel megbizonyosodik róla, hogy újonnan generált kód nem sérti a kernel vagy a felhasználó integritását. A Spin a Machra alapozódik;
EXOKERNEL: a Massachusetsi Műszaki Egyetem (MIT) készítette. A mikrokernel képes többszörözni a "hardverprimitíveit", megbízható módon. Jelenleg MIPS-en működik, és az feltevése, hogy nélkülöz minden absztrakciót: csak ezeket az ún. "hardverprimitíveket" tartalmazza (bár vannak benne azért eszközmeghajtók is). Ennek következményeképp az Exokernel erősen hardverfüggő. Valahogy úgy lehet elképzelni az egészet, hogy a mikrokernellel felépítünk egy interfészt a programok számára, ami nem túl bonyolult, inkább egy "virtuális processzorhoz" hasonlítható;
Az IBM és a GDM közös fejlesztése, közel egy évtizednyi kísérletezés eredménye. Talán a Mach után ez az első olyan kernel, amelynek komolyan gyakorlati jelentősége is van, ami a felhasználó szintű címtereket jelenti (User Level Address Space). Az Exokernellel egyidős, és érdekessége (a jelentős teljesítményért cserébe, amit kapunk), hogy csak 486-ostól felfelé támogatja a x86-os architektúrát (tehát még Pentium, Pentium Pro, sőt tartalmaz Pentium4-re is vonatkozó optimalizációkat!). De emellett létezik ARM és Alpha rendszerekre is. Másik meglepő dolog, hogy tényleg apró: az ARM változat forrásszövege csupán csak 6.000 sorból áll! Az egész igazándiból C++ és assembly kódrészletek keverékéből áll, és így erősen objektum-orientált is.
Én személy szerint az L4-et tartom a legmeggyőzőbb és a legkorszerűbb mikrokernelnek. Ezért gondolom, hogy ha "piacképesebb" rálátást akarok adni a problémákra, akkor a legújabb elméleteket kell elővenni. Természetesen ahol szükséges, ki lesznek emelve a korábbi mikrokernelek hibái, megoldásai is. A technikai megvalósításokba nem merészkednék bele; ez már jóval túlhaladná a témakört, illetve szükséges lenne némi védett módú assemby-tudás is.
Az L4 tehát három absztrakciós rétegből épül fel: címterek, szálak és a kommunikáció. (Ezek összesen csak 12 KB-nyi kódot takarnak!) A Machnál közel 25-ször gyorsabb, legalábbis a legsarkallatosabb pont, a kommunikáció tekintetében; illetve egy alapvető L4-es üzenetváltás még egy normális UNIX-hívásnál is kétszer gyorsabb (viszont egy ilyen funkció megvalósításához több üzenetváltásra van szükség - többnyire)!
A címtér nem más, mint "logikai" memória, egy szegmens. A fizikai (tehát a gépben lévő) memóriát tudjuk vele felosztani; talán úgy kellene elképzelni, mint egy halmazt. Ezeknek a halmazoknak értelmezett a metszetük is: az a memóriterület, amit a két címtér megoszt egymást között (pl. kommunikáció céljából). Maguk a címterek egy tetszőleges intervallumot képeznek a fizikai memóriacímekből: az egyik kezdődhet a nullás (ún. lineáris) címtől, mint akár egy másik is. A tényleges címekké való átkonvertálást az MMU végzi (a processzorban). Ezek szolgáltatottak felváltani a Mach tervezése közben elkövetett hibát: a külső lapozás szabályainak "huzalozását". Mivel ez elég komoly megszorítást jelent a teljesítmény szempontjából, ezt mindenképpen át kellett lépniük a második generációs mikrokerneleknek. Tehát ahelyett, hogy a kernel szabná meg a játékszabályokat, itt csak biztosítja az eszközöket ahhoz, hogy kialakíthatóak legyenek a megfelelő szabályozások. Ezek az eszközök megengedik a különböző védelmi sémák kialakítását, vagy akár a fizikai memória kezelését is a "kernel felett".
Az ötlet a kernelen kívüli címterek rekurzív felépítésében rejlik. A kezdeti címtér a fizikai memóriát reprezentálja és az első címtér-kezelő szerver (szigma0) irányítása alá tartozik. A rendszer indulásakor a többi címtér tehát még üres. A további címterek létrehozásához és karbantartásához (a kezdeti címtéren) a mikrokernel három műveletet biztosít: az "oda adás" (grant), a "belapozást" (map) és a "kilapozást" (demap, v. unmap, flush). Egy címtér tulajdonosa (egy vagy több szál, ami az adott címtérben hajtódik végre) "oda adhatja" bármelyik lapját bármelyik más címtérnek, biztosítva arról, hogy a címzett elfogadja. Az "oda adott" lap végleg eltűnik az "adományozó" címteréből, és megjelenik az "adományozott" címterében. Fontos, hogy a tulajdonos csak azok a lapokat "osztogathatja el", amelyet hozzá tartoznak. A tulajdonos természetesen "belapozhatja" (mondhatjuk azt is, hogy "kölcsön adhatja") saját címterének lapjait, amennyiben azt a másik elfogadja. Miután ez megtörtént, mind a két címtér tudja használni az immáron megosztott lapot. Tehát ellentétben az "oda adással" a lap megmarad a tulajdonos címterében. Mint az "oda adásnál" is, itt is csak azok a laphatók "adhatók kölcsön", amelyeket a tulajdonos birtokol. A tulajdonos "vissza is veheti" (vagyis "kilapozhatja") a "kölcsönadott" lapokat. A "visszavett" lap továbbra is elérhető marad a tulajdonos számára, de minden más címtérből eltűnik, ahonnan az közvetlenül, vagy közvetve elérhető volt. Bár ezen címterek tulajdonosainak explicit engedélyére nincs szükség, maga a művelet mégis biztonságos, hiszen az egész le van korlátozva lapokra. A "kölcsönadott" lapok használói már az elején beleegyeznek egy lehetséges "visszavételbe", amikor azt vagy "kölcsön" vagy pedig "örökbe kapják".
Mivel a lapozásokhoz szükséges az egyetértés a belapozó és a befogadó között, ezért ezt az IPC (folyamatok közti kommunikáció) valósítja meg. A címteres megoldás a memóriakezelést és a lapozást a mikrokernelen kívülre helyezi; a kernelben csak a grant, map, demap funkciók találhatóak. A belapozás és a kilapozás (map és demap) ahhoz szükséges, hogy memóriakezelőket tudjunk a mikrokernel tetején létrehozni. Az "oda adást" (grant) pedig csak különleges esetekben használják, hogy elkerüljék pl. a redundáns nyilvántartást, és a címterek túlcsordulását. A külső lapozásos megvalósítással szemben a kernel kizárólag csak a saját mechanizmusaira szorítkozik, a szabályokat pedig teljesen a felhasználói szintű szerverekre hagyja. Ennek illusztrálására akár fel is lehetne írni néhány ugyanilyen alacsonyszintű rendszerhívást, amelyek szintén címtér-alapú szervereket használnak, amik pedig a kernel mechnanizmusain. Egy szerver a kezdeti címteret kezeli, akár egy klasszikus memóriakezelő, de a mikrokernelen kívül. A memóriakezelők könnyen ráépíthetők egymásra; az első memóriaszerver belapozza, vagy elkéri a fizikai memória egy részét az 1-es memóriaszervernek és a 2-es memóriaszervernek. Így már van két parallel memóriakezelőnk.
Egy lapozó is beleépíthető a memóriakezelőbe vagy a memóriakezelést végző szerverbe. A lapozók használják a mikrokernel által nyújtott grant, map, demap primitíveket. A fennmaradó interfészek, a lapozó-kliens, a lapozó-memóriaszerver teljesen az IPC-re épülnek és a kernelen kívül vannak definiálva. A lapozók használhatóak a hagyományos lapozott virtuális memória megvalósítására, vagy akár állományok/adatbázisok belapozására, úgy, mint lapozatlan belső memóriának, amelyet a eszközmeghajtók vagy a multimédia rendszerek is használnak.
A felhasználó által definiált lapozási stratégiák lekezelése tehát felhasználói szinten is történik, a mikrokernel részéről egyáltalán nincs korlátozva. A multimédia és más valósidejű alkalmazások (tehát egy adott időn belül feltétlenül választ várnak) úgy foglalják le a memóriát, hogy megjósolható legyen a futási idejük. Például, a felhasználói szintű memóriakezelők és lapozók megengedik a fizikai memória egy pontosan meghatározott szeletének legfoglalását, vagy a memóriaterület zárolását (lock) egy adott ideig. Az ilyen multimédia és időosztó erőforrás-foglalók a szerverek együttműködése által képesek létezni. Az olyan memória-alapú eszközök, mint a bittérképes megjelenítők, megvalósíthatóak egy memóriakezelő által, amelyik a képernyő-memóriát a saját címterében tárolja.
Egy címtér tekinhető az eszköz-portok bejegyzéseinek természetes absztrakciójaként. Ez teljesen magától adódik a memóriába leképzett B/K eszközök esetén, de természetesen a B/K-portok is implementálhatóak. Az, hogy ezeket mennyire lehet irányítani, az adott processzortól függ. A 386-os és utódai például lehetővé teszik, hogy minden portot külön irányítsunk (egy nagyon kicsi lap hozzárendelése minden porthoz), de nem lehet belapozni a portok címeit; a PowerPC teljesen memóriába leképzett B/K-t használ, tehát a eszköz-portok irányítása és belapozása 4 KB-os lapokkal történik. A B/K eszközökhöz tartozó jogokat és az eszközmeghajtókat a mikrokernel alatt futó memórikezelők és lapozók is képesek kezelni, tehát nem szükséges támogatás a kernel részéről.
A szál egy tevékenység, ami egy adott címtérben zajlik. Egy "tao" szál leírható regiszterek egy halmazával, ami legalább tartalmaz egy műveletmutatót (instruction pointer), egy veremmutatót (stack pointer) és egy állapotinformációt (state information).
Egy szál állapotinformációja magában foglalja azt a "szigma-tao" címteret, ahol a "tao" valójában végrehajtódik. A címterek dinamikus és statikus hozzárendelése a döntő oka a szálak (vagy azzal ekvivalens) elvének alkalmazása a mikrokernelekben.
A címterek "meghibásodását" kivédve minden változás, ami a szál címterében bekövetkezik, a kernel irányítása alatt kell állnia. Ebből következik, hogy a mikrokernel tartalmaz valamiféle definíciót a "tao"-ra, amely a fenti tevékenységet reprezentálja. Néhány operációs rendszerben lehetnek további okok, hogy a szálakat mint az alapvető absztraktciós primitíveket alkalmazza, pl. a preempció. Ebből következik, hogy a kernelnek támogatnia kell a címterek közti kommunikációt, amit folyamatok közti kommunikációnak (IPC - Inter-Process Communication) is neveznek. Ez a klasszikus módja a szálak közötti üzenetek átadásának. Az IPC mindig feltételez egy "hallgatólagos megegyezést" mind a két oldalán: a küldő eldönti, hogy üzenetet fog küldeni és tisztában van annak tartalmával; a fogadó pedig eldönti, hogy fogadni akarja-e az üzenetet és szabad kezet kap annak értelmezésében. Az IPC nem csak a legalapvetőbb kapcsolat az alrendszerek között, de címterekkel együtt a függetlenség egyik alapköve. A belapozás/kilapozás lényegében az IPC-hez szükségeltetik, mivel az szintén igényli lapozó és lapozott kölcsönös beleegyezését.
A korábban már Yokote (1993) és Kühnhauser (1995) által is leírt architektúrákban nem csak a memóriában elhelyezkedő elemeket kellett felügyelni, hanem azok kommunikációját is. Ez mind a kommunikációs csatornák (communication channels) vagy pedig a klánok (Clans) alkalmazásával megoldható.
Az utóbbi módszert használja az L4, hiszen ez is az egyik újítása. A klánok lehetővé teszik az IPC-k figyelését a felhasználók által definiált szervereken keresztül. Ez egy nagyon gyors módszer, csak 2 (processzor)ciklust igényel IPC-nként.
Mielőtt rátérnénk a klánokra, nézzük meg, milyen megoldások léteznek még. Például a biztonságot egy szabályzattal adjuk meg: minden felhasználó hozzá tud férni minden objektumhoz; a szerverekhez való fizikai hozzáférés meg van tiltva; a felhasználók csak a saját állományaikhoz férnek hozzá; a felhasználók hozzá tudnak férni a saját állományaikhoz, annak a csoportnak az állományaihoz, amiben vannak és a publikus file-okhoz (ez lényegében a UNIX módszere). Tehát meg kell mondani azt, hogy ki (hitelesítés) mihez (felhatalmazás) férhet hozzá a rendszeren belül.
Most lépjünk át arra a szintre, hogy a hozzáférést IPC-ken keresztül valósítjuk meg. Ekkor felmerülhet a kérdés, hogy milyen mechanizmusokra van szükség a hőn áhított biztonság realizálására; hogyan hitelesítsünk, hogyan fog megjelenni a felhatalmazás, hogy adhatunk még további biztonsági szabályokat hozzá, és ezek betartását hogyan tudjuk elérni. Felhatalmazást a "hamisíthatatlan" szálazonosítókkal is megoldhatjuk, amelyek belapozhatóak mind a taszkokhoz, felhasználókhoz, csoportokhoz, gépekre, tartományokra (domainekre). Így az egész a kernelen kívülre kerül, és bármilyen szabályrendszer megalkotható. Akkor vegyük hozzá a hitelesítést is. A szerverek ugyebár objektumokat implementálnak; a klienseik IPC-n keresztül férnek hozzájuk. A szerverek az IPC-n keresztül szintén "hamisíthatatlan" kliensidentitásokat kapnak. A szerverek így képesek külső szabályokat is implementálni, és a mikrokernelben ezt semmilyen belső mechanizmusnak nem kell támogatnia (továbbra sem).
Vegyünk egy példát a fenti módszerre:
Ezzel létrehoztunk egy rendszert, amely a szerver-kliens kapcsolat szempontjából garantáltan be fogja tartani a szabályokat, viszont arról nem tudunk semmit, hogy a kliensek hogyan fogják cserélgetni az adatokat! Tehát igenis szükség van olyan mechanizmusokra, amelyek nem csak megvalósítják a szabályokat, hanem teljes mértékben be is tartják azokat. Ezeknek a mechanizmusoknak pedig elég rugalmasnak kell lenniük ahhoz, hogy az összes előforduló szabályt kezelni tudják.
Az L4 rendszerben a kernel nem hitelesíti a kommunikációkat, de lehetőséget ad a küldő azonosítására és megengedi, hogy bármelyik IPC-üzenet egy másik folyamathoz legyen átirányítva. Ezen átirányítások definiálására használja az L4 a "klánok és vezérek" (Clans & Chiefs) modelljét. Ebben a modellben a "vezér" egy megkülönböztetett folyamat egy klánon belül (ami pedig a folyamatok egy (rész)halmaza). A klántagok vezérekhez való hozzárendelése az L4-ben statikus. Bármilyen üzenetváltás, ami két tag között történik, azt a kernel minden beavatkozás nélkül továbbítja. Viszont bármilyen kívülről beérkező és kimenő üzenetet a kernel automatikusan átirányít az adott klán vezérének. A klán feje, a vezér megvizsgálja az üzenetet (tehát a küldő és a fogadó azonosítóját, illetve az üzenet tartalmát), és eldönti, hogy továbbadható-e a címzettnek. A vezér akár módosíthatja is az üzenetet - teljes hozzáférést kap. A tagok pedig megbíznak a vezérekben, ill. azok döntéseiben. A klánok segítségével helyi vonatkozású monitorok és korlátozások vezethetőek be, és implementálhatóak a kernelen kívül. Mivel a vezértaszkok felhasználói szinten futnak, ezért a "klán-elv" sokkal kifinomultabb és a felhasználó által jobban definiálható ellenőrzést tesz lehetővé, mint az aktív irányítás.
Milyen hátrányai lehetnek ennek a modellnek? Az egész statikus: akkor választhatjuk ki, hogy egy taszk melyik vezérhez tartozzon, amikor azt létrehozzuk. Tehát, ha irányítani szeretnénk az IPC-ket, akkor mindig ki kell jelölnünk egy vezért. Az általános esetben ez sokkal több üzenetváltás jelent, és minden taszknak van saját vezére.
A klánok implementálásának egyik eszköze, amellyel a biztonsági előírások betartását tudjuk teljes hatékonysággal elérni. Azokban a rendszerekben, ahol címterekkel határolják a folyamatokat, ott minden, a biztonságot érintő műveleteket IPC-ken keresztül valósítanak meg. Ezért az IPC-hez kapcsolódó mechanizmusoknak rendelkezniük kell egy hatékony hozzáférési szabályozással. De az fontos kikétel, hogy az ezzel járó többletmunkát minimalizálni kell! Az L4 tehát olyan lehetőségeket kínál, amivel egy "megbízható" folyamat dinamikusan képes "IPC-ösvényeket" kiépíteni szinte elhanyagolható lassulással. A szabályok kötelező betartatása és az IPC sebessége mindig is egy mikrokernel megalkotásának sarkos pontja. Egy ilyen rendszerben a szolgáltatások felhasználói szinten vannak implementálva, és sok folyamat kommunikációjára van szükség egyetlen taszk megvalósításához. A régebbi mikrokernelekben, mint pl. a Mach, a kernel csak annyit szabályozott, hogy egy folyamat képes-e a küldeni vagy éppen üzenet fogadni egy másik folyamatnak/tól. A szerver-objektumok műveleteinek tényleges hitelesítését pedig maguknak a szervereknek kell elvégezniük. Míg tehát a szervernek "megbízhatónak" kell lennie a saját objektumainak irányításakor, de arra lehet nincs felkészítve, hogy értelmezze és betartsa a rendszer biztonsági elvárásait. Ekkor többnyire létezik még egy külön folyamat, amit hivatkozási monitor (reference monitor)-nak hívnak, amelynek feladata a globális előírások betartatása.
A legújabb mikrokernelekben Jochen Liedtke (L4) teljesen kivette a kernelből a hitelesítést, ezzel is optimizálva az IPC-t. Ebben a rendszerben nem hitelesíti a kapcsolatokat, de "hamisíthatatlan" forrásazonosítást kínál fel, és megengedi, hogy bármelyik üzenetpár egy másik folyamatnak legyen átirányítható. (Ld. "Klánok"!)
Ezeket az átirányításokat "megbízató" folyamatok irányítják, amiket átirányítás-vezérlők (redirection controller)-nek nevezünk; feladatuk elvégezni a hozzájuk tartozó folyamatok üzeneteinek átirányítását. Ezzel a mechanizmussal le tudjuk kezelni az "IPC-ösvényeket", tehát az egész rendszer biztonsági szabályzata csupán pár üzenetváltással megoldható. Például egy "IPC-ösvényt" kell csak figyelni kezdetben (monitorozni), de amint a monitor "áldását adja rá", az akár el is távolítható (amennyiben a biztonsági előírások lehetővé teszik). Csak akkor kell újra beavatkoznia a kommunikációba a monitornak, amikor a szabályok megváltoznak.
Ezzel a mechanizmussal párhuzamosan egy másik megoldás is született a problémára, amit portál (portal)-nak neveznek. Egy portál nem más, mint egy testreszabható IPC. Hasonlóan az átirányításhoz, a portálokat privilegizált taszkok definiálják, és a kernel hívja meg minden IPC-kérésnél. A leírások alapján portálok implementációjában szerepel egy portáltábla (portal table) a kernelben, amiben sorban hivatkozásokat találunk a portálkódokra, amit a kernel később végrehajt (tehát először minden portál "megbízható").
Az alapvető különbség az IPC-átirányítás és a portálok között, hogy a portálok esetén a "megbízható" kód a kernel belsejében fut (annak címterében; ami, mint tudjuk, privilegizált, akár a monolitikus kerneleknél!), míg az átirányítás esetén általános mechanizmusok kerülnek meghívásra, tehát egyrészt nem a felhasználónak kell megírnia a kódját, másrészt pedig (ami egyben a legfontosabb) minden testreszabás a kernelen kívül implementálható (felhasználói címtérben)!
Egyelőre még nem dőlt el, hogy melyik a módszer a "nyerő", de azt már most is megállapíthatjuk, hogy az L4-nek sikerül szorosan tartani a saját és a biztonságos rendszerfelépítés elveit.
Tekintsük át röviden, hogy milyen gondok léphetnek fel egy üzenet átirányításakor. Amikor elküldünk egy üzenetet X-nek, akkor az a következő lehet: maga a cél; "nem létező"; egy köztes elem.
Ha X maga a cél, akkor kapunk egy gyors kommunikációs kapcsolatot, és szabadon információt cserélhetünk a céllal. Ha X nem létezik, akkor lényegében akadályba ütközünk, ami lehetetlenné teszi a kommunikációt (IPC hiba). Ha X egy köztes elem, akkor az lehet valamilyen biztonsági szabályzó (figyelő, elemző, visszadobó, módosító), kommunikáció-könyvelő, vagy nyomkövető is. Ebben az esetben nincs félnivalónk, a célhoz nagy valószínűséggel el fog jutni az üzenet (amennyiben nem lesz eldobva), csak egy másik folyamaton keresztül. Ekkor pl. "álcázásra" is lehetőségünk nyílik: a cél azt fogja hinni, hogy az üzenet a köztes elemtől érkezett.
A hardveres megszakítások természetes absztrakciója egy IPC-üzenet. A hardver szálak egy halmazának tekinthető, amelyeknek speciális szálazonosítójuk van, és üres üzeneteket küldenek (ami csak a küldő azonosítóját tartalmazza) a hozzájuk rendelt szoftveres szálaknak. A fogadó szál a küldő azonosítójából következteti ki, hogy az egy hardveres megszakítás és éppen melyik (íme egy pszeudókód):
driver thread:
do
wait for (msg,sender);
if sender = my hardware interrupt
then read/write io ports;
reset hardware interrupt
else ...
fi
od.
A megszakítások üzenetekké való átalakítását a kernelnek kell elvégeznie, de a mikrokernel nem foglalkozik az eszközökhöz kapcsolódó megszakítás-kezeléssel. Egyáltalán semmit sem tud a megszakítások szemantikájáról.
Némely processzoron a megszakítás nyugtázása az egy eszközhöz kapcsolódó tevékenység, amelyet a felhasználói szinten lévő eszközmeghajtók kezelik le. Az "iret" utasítást csak arra használják, hogy kivegyék a rendszerveremből az állapotinformációt, vagy éppen visszaváltsanak felhasználói módba, amit a kernel el is rejthet. De ha a processzornak privilegizált utasításra van szüksége egy megszakítás "elengedéséhez", azt a kernel implicit módon elvégzi, amikor az eszközmeghajtó kiadja a következő IPC-műveletet.
Egy mikrokernelnek egyedi azonosítókat kell biztosítania (unique identifier - uid) mindennek, legyen az akár szál, taszk vagy kommunikációs csatorna. Ezek az uid-ek szükségesek a megbízható és a hatékony helyi kommunikációhoz.
Ha S1 üzenetet akar küldeni S2-nek, akkor meg kell adni az S2-t mint célt (vagy valamilyen kommunikációs csatornát, ami az S2-höz vezet). Ezért tudnia kell a mikrokernelnek, hogy melyik uid tartozik az S2-höz. Másrészről, ha S2 meg akar bizonyosodni arról, hogy az üzenet tényleg az S1-től jött. Emiatt minden azonosítónak egyedinek kell lenni mind (processzor)időben és (cím)térben.
Elméletileg akár titkosítást is lehetne használni. A gyakorlatban viszont túlságosan "drága" (sok időbe telik), hogy a helyi üzeneteket titkosítani kelljen, és a kernelben is illik megbízni (tehát alkalmazása nem indokolt)! S2-nek amúgy nem kötelező rábíznia magát a felhasználó által felajánlott lehetőségekre, mivel az S1 vagy valamelyik más példány meg is többszörözheti és átadhatja azokat S2 irányítása nélkül más alrendszereknek, amiben az S2 éppen nem is bízik.
Ahogy az IPC-műveletek egyre gyorsabbak lesznek, úgy az ún. "sztubkód" hatékonysága is egyre fontosabb lesz a helyi kliens-szerver alapú RPC (Remote Procedure Call)-k és a komponenseken belüli kapcsolatok tekintetében. Ez a sztubkód egy olyan programrészlet, amely garantálja, hogy a folyamatok "beszélgetése" a mikrokernel szabályai szerint folyik. Egyben megkönnyítik egy szerver- kliensíró munkáját, hiszen nem kell ismernie azt, hogy az üzenetek milyen elemekből állnak. Nem is beszélve arról, hogy ezzel létrehozunk egy újabb absztrakciós szintet, tehát teljesen el lehet fedni vele az üzenetkezelés implementációját, egy hordozható eszköztárat alakítunk ki. De mivel ezek a rendszer igen fontos építőelemei (minden programba beépülnek, és ugyebár a teljesítmény szempontjából fontos IPC/RPC-ket kezelik), rosszul megírva akár meg is duplázhatják egy üzenetváltás költségeit. Igazából a sztubnak is lehetne magyar megfelelője, talán a "tok" lenne rá a legjobb szó; bár a "tokkód" elég furcsán hangzik :))
Az L4 fejlesztése során így kifejlesztettek egy teljesen új IDL-fordítót, amely közel optimális kódot generál az L4 mikrokernel és a gcc (GNU Compiler Collection) használatakor. A jelenleg még csak kísérleti fázisban lévő IDL4-fordító tehát szorosan együttműködik gcc-vel és annak x86 architektúrára készített kódgenerátorával.
Természetesen más architektúrák és más fordítók más optimizációkat kívánnak meg. Viszont azt lehet elérni, hogy a esetek igen nagy százalékában ez a fordító megközelítőleg háromszor gyorsabb (és kisebb) kódot generál, mint egy elterjedtebb hordozható IDL-fordító. A mérések szerint ez az előny nem is annyira elhanyagolható: egy kellően jó sztubkód tíz százaléknál is nagyobb teljesítménynövedekést indukál. Ezeket eredményeit az IBM SawMill-jében is felhasználták, aminek feladata egy többszerveres operációs rendszer technológiájának kifejlesztése.
A többszerveres és a komponens-alapú rendszerek ígéretes szervezési módnak tűnnek napjaink operációs és alkalmazói rendszereinek szempontjából. A komponensek vagy szerverek (és kliensek) egymással a tartományaikon keresztül kommunikálnak a módszereik meghívásaival. Ha egy hívás átlépi a biztonsági küszöböket (a címtereket), akkor ezeket jellemző módon IPC-ken keresztül valósítják meg: először is, az ilyen kölcsönhatásoknak nagyon gyorsan és pontosan kell lezajlaniuk. Ezért közel egy évtizedig a teljesítményekre vonatkozó kutatások és fejlesztések egy viszonylag elfogadható IPC-s költséget adtak eredményül. Másodsorban, a komponensek kölcsönhatásainak egy alkalmazásprogramozó szempontjából is könnyen kezelhetőnek kell lennie. Ez az elvárás alkotta meg interfész-definíciós nyelv (Interface Definition Language)-eket; ilyenek a CORBA IDL, a DCOM és a hozzájuk tartozó fordítók. Az interfész eljárás/módszer-definícióiból az ilyen fordítók sztubkódot hoznak létre: "becsomagolják" a kliens oldalon a paramétereket, levezénylik az üzenetváltásokat a kernel által biztosított IPC- és RPC-mechanizmusokon keresztül, "kibontják" a kapott paramétereket a szerver oldalon, meghívják a kért szerverbéli eljárást/módszert, stb.
Végeredményben egy programozó ugyanúgy képes megadni és használni távoli interfészeket, mint belsőket. Mindeddig az IDL-fordítókhoz kapcsolódó kutatások leginkább arra koncentráltak, hogy használható és hordozható sztubkódot hozzanak létre, ahelyett, hogy azok teljesítményét figyelembe vették volna. Tény, ami tény, a mikrokernelek hajnalán több száz ciklusra is felduzzadt így egy üzenetváltás.
Napjainkban egyre nagyobb a jelentőségük ezeknek a kódoknak is. Természetesen az eddig kísérletezések sem vesztek kárba, hiszen kiváló alapot szolgáltattak az optimizált interfészekhez; ezért ne feltétlenül baklövésnek, inkább egy lépcsőnek vegyük őket!
Az interfészek megértéséhez elsőként szükségünk van maguknak az üzenetek felépítésének (felületes) megismerésére. Az L4 alapvető kommunikációs paradigmája a szinkron-IPC. Ennek alapműveletei a küldés (send), fogadás (receive) és a hívás (egy összekapcsolt, "atomi" küldés és fogadás), és az atomi "válaszadás és várakozás" (reply & wait). Maguknak az üzeneteknek pedig számos fajtája különíthető el:
A Mach interfész-generátora, a MIG (Mach Interface Generator) a Matchmaker nyelvet használja fel. Ez a nyelv a "többnyelvű" folyamatok közötti kapcsolati interfészek leírására és a generálás automatizálására használatos. A MIG ennek egy "gyengített" implementációja, amely C és C++ nyelvű távoli eljáráshíváson (remote procedure call) alapuló interfészeket és IPC-ket generál a Mach rendszer taszkjai között. Az RPC-k természetesen itt is egy kliens és egy szerver között történnek.
A Mach IPC-interfésze programozási nyelvtől független és meglehetősen összetett. A MIG-et is tehát arra tervezték, hogy C nyelven automatikusan legenerálja a küldéshez szükséges adatok összegyűjtését és a fogadáshoz szükséges adatok szétszedését, amik a folyamatok közti kommunikációk során keletkeznek. A felhasználónak ehhez mindenképpen meg kell adnia egy olyan állományt, amely mind tartalmazza az üzenetküldés és a távoli eljáráshívás interfészét. Ebből a MIG három további file-t állít elő:
Az olyan IDL-fordítók, mint a Flick (Flux Research Group - Utah) viszonlyag könnyűvé teszik egy teljesen új operációs rendszer vagy félig kész kernel "mikrokernel felé hozását", és akár új adattípusokkal is bővíthetőek. Egy IDL-fordító kimenete többnyire egy általános célú fordítóprogram (mint amilyen a gcc is, amit egy programozó a kód fejlesztésére használ) bemenete.
Természetesen újabb terület ezen fordítók könnyű hordozhatósága a különböző általános célú fordítóprogramok között.
A Flick hatékony sztubkódot ún. inline függvények (amikor nem egy függvényhívást helyezünk el egy kódban, hanem a forrásszövegben előforduló hívások helyére magának a függvények a kódját helyezzük el) és makrók alkalmazásával próbál generálni, amikor azok csak lehetségesek. Mindazonáltal, amikor ezt pl. a gcc-vel kombináljuk, eredményül óriási mennyiségű adatműveletet kapunk, melyek valójában feleslegesek. Elméletileg ezeket a fordítónak el kellene távolítania. Gyakorlatilag viszont az ehhez szükséges adatelemzések túlságosan is körülményesek; ebből következik, hogy a generált programkód mégsem hatékony.
Beszéljünk egy egyszerűsített modellről! Ezen keresztül kerül bemutatásra mind a szerven és a kliens oldalán megjelenő sztubkód. Ebben az egyszerű modellben feltételezzük, hogy egy kliens meghívja a szerver által nyújtott M eljárást, vagy módszert. A szinkronizációtól és az egyidejűségtől most eltekintünk. Az M-nek vannak bemenő paraméterei (in) (azok az értékek, amelyek a kliens ad át a szervernek) és kimenő paraméterei (out) (azon értékek, amit a szerver visszaküld a kliensnek), és eredmény paraméterei (inout), amelyeket először megkap a szerver, majd azokat felülírja és visszaküldi. Az IDL-fordító generál egy M_kliens klienssztub-eljárást minden M függvényhez, ami szerepel az interfész definíciójában. Ez a klienssztub hívódik meg a kliens által. Ez elrejti, hogy a szolgáltatás nem a kliens címterében ("helyben") fut le, hanem egy másikban vagy éppen egy tőle kilométerekre levő másik számítógépen!
A klienssztub tehát összeállítja az üzenetet, és minden olyan információt belerak, amire a szervernek szüksége van a feladat teljesítéséhez, beleértve minden paramétert. (A neve "feltűzés" (marshalling).) Az üzenet ezután el lesz küldve a szervernek és a kliens pedig vár annak válaszára. A válaszként kapott üzenet tartalmazza az összes kimenő és eredmény paraméter értéket. A klienssztub kibontja ezeket az értékeket az üzenetből, és "szétszedi" (unmarshalling) az adott kliens paraméterekbe.
Részletesebben, az M_kliens lépései:
K1: létrehoz egy kérést (request message), mely tartalmaz minden bemenő és eredmény paramétert, és egy kulcsot (key), ami azonosítja az M eljárást/módszert ("feltűzés");
K2: elküldi a kérést annak a szervernek, amely implementálja M-et, és megvárja annak válaszát;
K3: kitölti az eredmény és kimenő paramétereket a válaszban megkapott adatokkal ("szétszedés"), majd
K4: visszatér velük a hívó klienshez.
A szerver programozója implementál egy M_szerver eljárást szerver oldalon minden egyes M-hez, ami szerepel az interfész definíciójában. Az IDL-fordító létrehoz egy központi (kód)sablont, ami kezeli a kommunikációt, dekódolja, összerendezi és visszarendezi a paramétereket. Ez a központi szerverkód általában tartalmaz egy főciklust, ami fogadja a kliensek felöl érkező kéréseket és továbbítja azokat a megfelelő M_szerver eljáráshoz. Minden egyes M_szerver-hez az IDL-fordító generál egy szerversztubot, amit megvizsgálja a kérést és fogadja az adatokat ("szétszedés"). Ezután a sztub meghívja magát a rutint és végül elkészíti a választ a kliens számára. Egy IDL-fordítónak mind a főciklust, mind a sztubokat automatikusan kellene generálnia. A felhasználók számára pedig lehetőséget kellene adnia, hogy azok könnyen módosíthassák a ciklus kódját, ha esetleg további tulajdonságokat szeretnének implementálni, pl. terhelés-kiegyenlítés (load balancing).
Lényegében egy szál várja a kliensek kéréseit:
Sz0: fogadja a kérést és a kapott kulcsból megállapítja, hogy melyik M eljárást/módszert kellene meghívni és milyen paramétereket kell majd az M-nek visszaadnia;
Sz1: kibontja a bemenő és eredmény paramétereket a kapott üzenetből ("szétszedés");
Sz2: meghívja az M_szerver szerverbéli eljárást a kibontott paraméterek értékeivel;
Sz3: létrehoz egy válaszüzenetet (reply message) és eltárolja a kapott értékeket, az M_szerver eljárás eredmény és kimenő paramétereit ebben az üzenetben ("feltűzés");
Sz4: visszaküldi a választ a kliensnek.
A K2, Sz0 és az Sz4 lépéseket alapjában véve a "futtató IPC-rendszer" határozza meg, ami jelen esetünkben az L4 mikrokernel. A K4 és Sz2 lépéseket a használt általános célú fordító adja meg, ami most a gcc. A "feltűzés" és "szétszedés", tehát a K1+Sz1, illetve az Sz3+K3 kevésbé behatároltak (az IDL-fordító szempontjából) és sokkal fontosabbak. Ahogy a Flick-kel kapcsolatban is megemlítettük, egy kevésbé optimális kód könnyen jelentős mennyiségű felesleges másolási műveletet eredményez a "feltűzés" és a "szétszedés" során.
Hogy lássuk, miként képesek a paraméterek a leghatékonyabban áramlani az M_kliens és M_szerver között, meg kell figyelnünk egy "helyi" eljáráshívást. A gcc és sok más C fordító a bemenő paramétereket a verem tetejére helyezi az eljárás meghívása előtt. Most nézzük ezt "távoli" esetben: csupán három paraméter-érték kerül a kliens vermére (M_kliens), és a szerver oldalán futó M_szerver-nek normális esetben egy teljesen ugyanolyan veremmel kellene rendelkeznie, mert az M_szerver-nek ugyanazok a paraméterei, mint az M_kliensnek.
Tehát ekkor a sztubkódnak csak a kliens vermének egy részét kell átmásolnia a szerver vermére. Semmilyen egyéb művelet, sem "feltűzés"/"szétszedés" nem szükséges.
Mivel C-ben a kimenő paraméterek többnyire mutató típusú változókkal vannak implementálva (melyek bemenő paraméterként is szerepelnek), ki kell egészítenünk a paraméterek halmazát további ilyen változókkal, amelyek azon társaikat címzik, akiket később vissza fogunk küldeni a kliensnek, mint kimenő paramétereket. Az L4-ben konkrétan így oldják meg:
1. A kliens felépít egy olyan üzenetet, ami tartalmazza mind a bemenő és az eredmény értékeket (meg még esetleg egyéb sztringeket). Az üzenetpufferben van elég hely, hogy tudja fogadni benne a szervertől érkező választ;
2. A szerver kiegészíti a kapott üzenetet még mutatókkal, amelyek megcímezhetővé teszik az eredmény és kimenő paramétereket (és az opcionálisan szereplő sztringeket is) a M_szerver szerver oldali eljárás számára. Ezután hívódik meg az M_szerver. Mint bármelyik más C függvény, a saját bemeneti paramétereivel dolgozik;
3. Miután befejeződött az M_szerver, a sztub eltávolítja a mutatókat és a bemenő paramétereket a veremről, a tetejére teszi a visszatérési értéket és megfelelő üzenőfejlécet, majd elküldi az így keletkező választ a kliensnek.
Közvetlen következménye a verem és az üzenet felosztásának, hogy az IDL-fordítónak át kell rendezni a paramétereket.
Jelen pillanatban az IDL4 csak 32 bites szavakat és legfeljebb 2 MB-os sztringeket képes kezelni. Ezek később még ki fognak egészülni a lapokkal is, így az IDL függvényein keresztül tud majd kezelni lapozást is. Ezek ellenére bármilyen más adattípus implementálható a alaptípusokkal. A nagyobb objektumok, mint tömbök vagy rekordok egyszerűen tekinthetők sztringeknek, míg a kisebbek (karakterek, rövidebb egészek) nyugodtan kiterjeszthetőek 32 bites szavakká. A kisebb objektumok szavakká való kiterjesztése amúgy sem okoz többletköltséget, hiszen a gcc is szavakként kezeli ezeket, amennyire csak lehetséges egy normál függvény generálásakor. Hasznos a nagyobb adattípusok indirekt sztringekként történő megvalósítása is, mert nem másolódnak közvetlenül az üzenőpufferba.
A fenti elméleti leírás illusztrálására elemezzük ki, hogy a fordító mit fog tenni a pfs_write() függvény esetében! (A pfs_write() a fizikai állományrendszer írási műveletét realizálja). A függvény prototípusa a következő (kiegészítve a paraméterek szerepével)):
int pfs_write(
int handle /*be*/,
int* pos /*eredmény*/,
int len /*be*/,
int data_size /*be*/,
int* data /*be,
data_size hosszan*/ );
Az IDL4 három állományt hoz létre, amelyek magukban foglalják a klienssztubot, a szerversztubot és a fő szerverciklust. A sztubok a gcc-ben függvényként szerepelnek, de assembly-ben vannak megírva. A szerverben futó főciklus C-ben keletkezik, így könnyen átalakítható egy alkalmazásíró számára. Minden függvényben közös, hogy dekódolják a beérkező kéréseket, tehát kiválasztják megfelelő szolgáltatást és meghívják azt a sztubon keresztül:
setupNewBuffer(); /* az új puffer előkészítése */
ipcReceive(); /* az IPC-üzenet fogadása */
do { /* a ciklus eleje */
unpackQuery(); /* a kérés "szétszedése" */
callStub(); /* a sztub meghívása */
packResponse(); /* a válasz "feltűzése" */
setupNewBuffer(); /* egy új puffer előkészítése */
ipcReplyWait(); /* a válasz küldése és várakozás a következő kérésre */
} while(1); /* egy végtelen ciklus */
A kliens oldalon keletkezett kód a következőképpen fog működni:
1. Az indirekt sztringek leíróinak elkészítése: a pfs_write() egyetlen bemenő sztringgel rendelkezik, ez a "data", tehát ehhez létre kell hozni egy leírót (descriptor);
2. A paraméterek "feltűzése": a bemenő és eredmény paraméterek a veremre pakolódnak, a sorrend fordított. Viszont két paraméter (a "len" és a "handle") nem oda kerül, hanem az EBX és az EDI regiszterekbe;
3. Az üzenőfejléc létrehozása: a fejléc megadja, hogy mennyi szót (dword ~double word - x86 architektúrán ez ekvivalens a 32 bites szavakkal) kell mindkét irányba továbbítani, illetve ehhez csapódik még egy lapozásra használatos, de jelen pillanatban nem alkalmazott szó is;
4. A regiszterek beállítása az IPC-re és a függvénykulcs megadása: az IDL4-nek meg kell adnia a külső és fogadó pufferek címét és egy határidőt (timeout). Ugyanitt kerül átadásra a regisztereken keresztül a függvény azonosítója;
5. Az IPC meghívása;
6. A szerver kimenetének "szétszedése": a pfs_write() esetében a visszatérési értékét és a "pos" paramétert kell lekezelni. Ezek szintén átadhatók kizárólag csak regiszterek segítségével, így egyáltalán nem használtunk semmilyen memóriapuffert.
Ez a sztub a szerver ciklusából hívódik meg. Átalakítja a klienstől érkező kérést egy verembeli keretté (frame) a szerver számára:
1. Beállítja a veremmutatót az üzenőpufferra: az üzenet fejléce és a függvény azonosítója (amely az első szó a sorban) felülírható, így az új ESP a puffer ötödik szavára mutat;
2. Hozzáadja a mutatókat a sztringekhez és a kimenő értékekhez: először is, hogy "pos"-t címző mutató kerül a veremre, majd egy a bemenő sztringpufferba. Végül a megadjuk annak a szálnak az azonosítóját, ahonnan az üzenet származik;
3. Elvégzi a függvény meghívását;
4. Felépíti a választ: a bemenő értékeket és mutatókat eldobja, majd a visszatérési értéket és az új üzenet fejlécét teszi hozzá;
5. Visszaállítja a veremmutatót: a függvényhívás közben az eredeti érték el volt mentve az EBP-ben, az egyetlen olyan regiszterben, amit a gcc automatikusan elment.
Az IDL4 bebizonyította, hogy a sztubkódok optimizálása jelentősen mégtérül, és talán nagyban hozzájárul ahhoz, hogy az ilyen komponens-alapú rendszerek megüssék a piac által megkövetelt szintet. Bár ezzel kapcsolatban felmerül néhány kérdés:
- Mennyire tehető hordozhatóvá egy optimizáló IDL-fordító?
- Mit kell tenni ahhoz, hogy a fordítót egy újabb általános célú fordítóprogramra, vagy számítógépes architektúrára át tudjuk ültetni?
Jelenleg az IDL4 kódgenerátor a gcc fordítóprogramra és az x86-os processzorok van "belőve". A fejlesztőknek azért van néhány sejtésük arról, hogy mivel járna más architektúrákra felépíteni ugyanezt a rendszert:
Az utolsó pont egy legkritikusabb. Nagyon nehéz, vagy egyenesen lehetetlen megoldani az optimalizációkat, ha a C fordító nem ad hozzáférési lehetőséget a saját kódgenerálási folyamatához. De a probléma még akkor is fennállni látszik, mikor az IDL-t leválasztjuk a programozási nyelvről. Az összes többi esetben az adaptáció költsége hasonló, ha nem alacsonyabb, mint egy átlagos fordítóra való portolás.
Az ilyen mikrokerneles rendszerek egyik nagy próbája a már létező UNIX változatok implementálása. Ezt többnyire egyetlen szerverrel valósítják meg, ami tehát az adott monolitikus kernel átírása egy folyamatba. Viszont az igazi rugalmasságot és erőt az rejti magában, amikor egy mikrokernel felett több szerver fut párhuzamosan, és mindegyik más-más funkciót lát el a rendszerben. Remélem, még nincs késő, és például a neuronhálón alapuló operációs rendszerek nem söprik le az asztalról több évtized kemény fejlesztői munkáját. Nem azért tartanám igazságtalanságnak, mert felszámolnák a szívemhez közel álló "klasszikus" rendszereket, hanem mert ez akkor egy olyan rendszer lenne, amely soha nem tudott beteljesedni, elfoglalni az őt megillető (megérdemelt) helyét.
Jochen Liedtke: On m-Kernel Construction (15th ACM Symposium on Operating Systems Principles, 1996);
Toward Real Microkernels (September 1996/Vol 39., No. 9 - Communications of the ACM);
Trent Jaeger, Kevin Elphinstone, Jochen Liedtke, Vsevolod Panteleenko, Yoonho Park: Flexible Access Control Using IPC Redirection (IBM T.J. Watson Research Center);
Kevin Elphinstone, Volkmar Uhlig, Uwe Dannowski, Espen Skoglund: m-Kernel Construction (az előadássorozat vázlata);
Andreas Haeberlen, Jochen Liedtke, Yoonho Park, Lars Reuther, Volkmar Uhlig: Stub-Code Performance is Becoming Important (University of Karlsruhe - System Architecture Group, IBM T.J. Watson, Dresden University of Technology - Department of Computer Science);
Keith Loepere: Mach 3 Kernel Principles (Open Software Foundation and Carnegie-Mellon University, 1992);
Richard P. Draves, Michael B. Jones, Mary R. Thompson: MIG - The MACH Interface Generator (Carnegie-Mellon University - Department of Computer Science, 1989)
The Flux Research Group: The OSKit: The Flux Operating System Toolkit Version 0.97 (University of Utah - Department of Computer Science, 2002)
Ezzel a dokumentummal kapcsolatban minden megjegyzést, kérdést, kérést a pg0003@delfin.klte.hu címre lehet küldeni. A tévedés, félre{fordítás|értelmezés}és a frissítés jogát fenntartom! A leírás nyomtatott formában való megjelenése és terjesztése megengedett bármilyen formában, de erről kötelező értesíteni a szerzőt!